VideoClaw和JoyAI-Echo两大开源框架同日发布,分别用多智能体协作和跨模态记忆库解决AI长视频一致性问题,本文对比两者技术方案。

VideoClaw和JoyAI-Echo两大开源框架同日发布,分别用多智能体协作和跨模态记忆库解决AI长视频一致性问题,本文对比两者技术方案。
AI 生成几秒钟的视频已经不算新鲜事。但让同一个角色在几分钟里始终保持一致——脸不变、衣服不漂、音色不飘——这才是 AI 视频生成真正要啃的硬骨头。
今天,两个开源框架同时给出了各自的解法:哈工大联合阿里发布的 VideoClaw,以及京东发布的 JoyAI-Echo。两者都瞄准长视频一致性,但技术路线截然不同。
长视频生成本质上不是一个"拉长时间"的问题,而是跨镜头、跨场景、跨动作的连续叙事问题:
VideoClaw 来自哈工大张民教授团队与阿里巴巴的合作,核心思路是把长视频生成拆解为多智能体协作的流水线。
用户只需输入一句灵感或故事梗概,系统调度由大模型驱动的"数字剧组",依次完成:
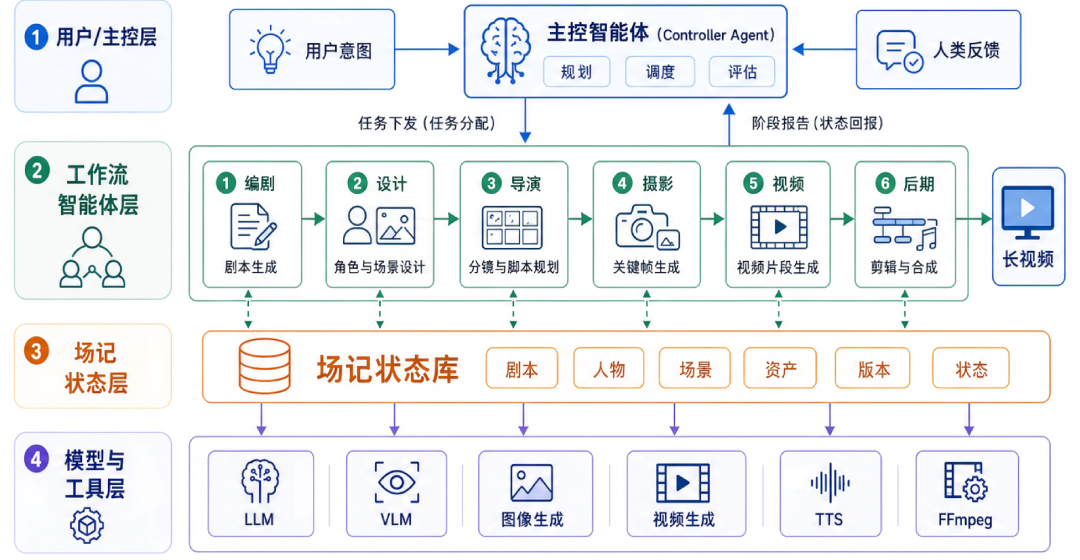
与黑盒式视频生成不同,VideoClaw 在剧本、角色场景、分镜等阶段完成后会暂停展示阶段性产物,让创作者能在关键节点介入修改。
VideoClaw 引入了类似"场记"的状态库,将角色关系、空间位置、场景分镜和版本信息沉淀为结构化资产。后续生成时从状态库中调取参考约束。
这意味着 VideoClaw 支持故事的无限续写——视频一段接一段延展,剧情冲突自然升级,人物互动基于已有情节继续推进。
VideoClaw 将视觉语言模型(VLM)嵌入生成流程中,在图片、关键帧和视频片段生成后启动审查:比对画面内容是否符合剧本设定,检查人物、场景和叙事逻辑是否出现偏移。如果候选版本未达质量阈值,会输出诊断报告并触发回溯与重新生成。
VideoClaw 支持 Linux / Mac / Windows 多平台快速安装,提供 WebUI 界面,也可集成至微信、飞书等通讯工具调用。
JoyAI-Echo 来自京东,核心思路是给模型装一个"记忆库",让它在生成长视频时不忘记角色长相和声音。
跨模态音视频记忆库
系统记录的不只是人物长相,还同步记录说话人的音色,并将两者绑定。角色首次登场时提取视觉特征和声音特征写入记忆库;后续每生成一个镜头,都从记忆库调取参考。
记忆库不是无限扩展的——保留故事开头的关键镜头和最近生成的镜头,兼顾效率和一致性。
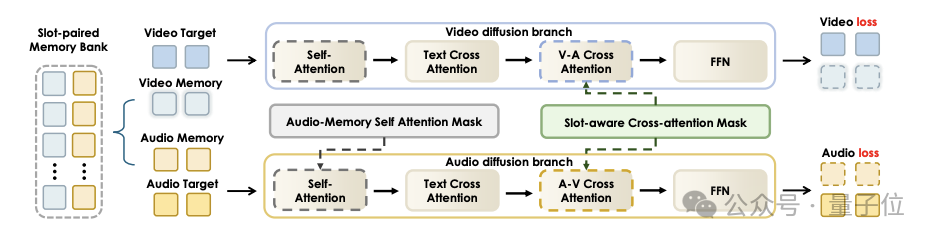
记忆驱动后训练:推理速度提升 7.5 倍
后训练流程分三步:
仅 DMD 优化就带来约 7.5 倍的推理速度提升。
轻量化实时超分
在保证生成效率的同时输出高清画面,适合数字人、品牌营销等对画质有要求的场景。
| 维度 | VideoClaw | JoyAI-Echo |
|---|---|---|
| 核心思路 | 多智能体协作流水线 | 跨模态记忆库 |
| 一致性方案 | 场记库 + VLM 质检闭环 | 音视频记忆库 + 后训练优化 |
| 交互方式 | WebUI + 微信/飞书集成 | 对话式编辑 Agent |
| 推理速度 | 未披露 | DMD 加速 7.5 倍 |
| 开源状态 | GitHub 开源 | 开源 |
| 团队 | 哈工大 + 阿里巴巴 | 京东 |
| 适合场景 | 短剧制作、影视二创、故事续写 | 高一致性音视频内容、数字人 |


SceneMaker 是一个突破性的开源框架,能从单张图像生成完整的、带 Mesh 的 3D 场景,完美解决物体遮挡和空间位姿问题。

Anthropic 托管智能体平台 CMA 一次性推六项更新:会话技能 20 升 500、effort 五档可写入 per-agent 配置、种子会话带 initial_events 一步创建。

深涌智能开源的 Agent 框架,支持 A股/美股/港股,10 分钟本地部署一个会自主分析市场主线的金融研究 Agent。