Claude Opus 4.7 全面上线,编程 SWE-bench Pro 达 64.3% 超越 GPT-5.4,视觉分辨率翻 3 倍,但 token 消耗上涨 35%,长上下文能力暴跌。升级前必看这篇实测指南。

Claude Opus 4.7 全面上线,编程 SWE-bench Pro 达 64.3% 超越 GPT-5.4,视觉分辨率翻 3 倍,但 token 消耗上涨 35%,长上下文能力暴跌。升级前必看这篇实测指南。
Anthropic 在 4 月 17 日发布了 Claude Opus 4.7,距离上一代 Opus 4.6 仅两个多月。这个模型没有追求"全能最强",而是做了一次精准的能力取舍:编程和视觉大幅提升,但长上下文和搜索能力主动退步。如果你是开发者、数据分析师或依赖 AI 做文档处理的人,这次升级值得认真评估。但升级前有几个必须知道的坑。
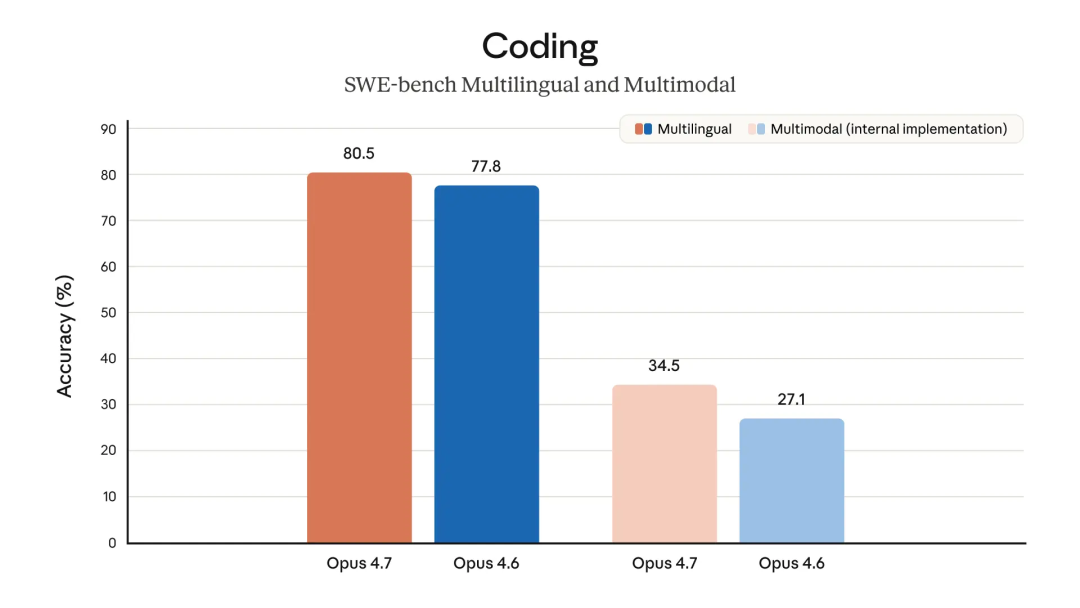
Opus 4.7 的核心升级方向是高级软件工程。在三个主流编程基准测试上,它都拿到了当前公开可用模型的最高分。
SWE-bench Verified(修真实 GitHub bug):87.6%,比 Opus 4.6 的 80.8% 提升近 7 个点,超过 Gemini 3.1 Pro 的 80.6%。
SWE-bench Pro(跨四种语言的完整工程流水线):64.3%,比 4.6 的 53.4% 跳了 11 个点。GPT-5.4 是 57.7%,Gemini 3.1 Pro 是 54.2%。
CursorBench(真实 IDE 环境的编程辅助):70%,4.6 是 58%,涨了 12 个点。
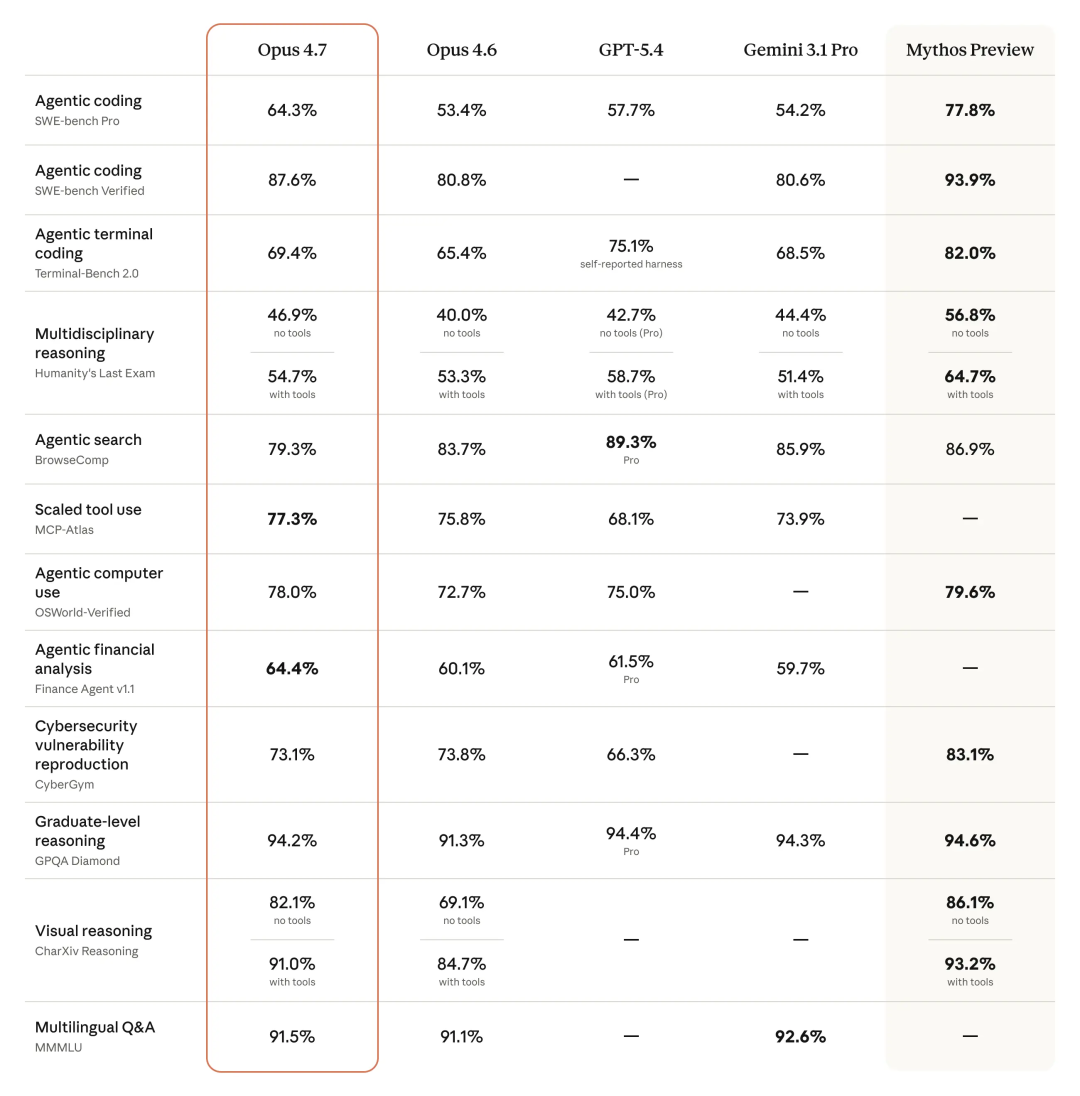
实际体感上,多位早期测试者反馈:以前需要全程盯着模型改代码的任务,现在可以放心交给 4.7 自己跑。Rakuten 的测试数据显示,4.7 解决的生产任务数量是 4.6 的 3 倍。Hex 的 CTO 表示,低 effort 档的 4.7 性能大约等于中 effort 档的 4.6。
这是本次升级幅度最离谱的部分。
最大图像输入分辨率从约 115 万像素(长边 1568 像素)提升到约 375 万像素(长边 2576 像素),是前代的 3 倍多。视觉精准度基准 XBOW 从 54.5% 直接干到 98.5%。
这意味着什么?
OfficeQA Pro(处理复杂办公文档)这项测试最能说明日常使用场景的差距。Opus 4.7 拿到 80.6%,Opus 4.6 是 57.1%,GPT-5.4 是 51.1%,Gemini 3.1 Pro 只有 42.9%。
4.7 比 GPT-5.4 高出近 30 个点,和自家上一代比跳了 23 个点,是整个 System Card 里单项提升最大的。写 PPT、做财报模型、读复杂合同、做跨文档整合,这些日常办公场景是本次升级最受益的维度。
xhigh 努力级别:新增在 high 和 max 之间的档位,Claude Code 所有计划的默认值已更新为 xhigh。大多数任务用 xhigh,最难的才上 max。
/ultrareview 命令:开启独立审查会话,逐行检查代码变更,标记 bug 和设计问题。Pro 和 Max 用户有 3 次免费试用。跑一次可能要 5-20 美元,但能发现人眼容易漏掉的问题。
Auto Mode(自动模式):扩展到 Max 用户。Claude 在你授权范围内自主做决策,减少人工确认中断。一个任务跑起来后,你可以切去处理下一个任务。
Task Budgets(任务预算):API 端的公测功能,给 Claude 设定总 token 预算,模型在执行中能看到剩余额度,避免跑到一半超支。
Opus 4.7 换了新 tokenizer。同样的文本,4.7 要多吃 1.0 到 1.35 倍的 token。叠加默认 effort 档位拉到 xhigh,实际使用成本几乎必然上升。
官方说法是"模型虽然每次吃得多,但干活更利索,总账可能更划算"。建议先在真实流量上跑一次对比再决定是否全面切换。
MRCR v2 @1M(百万 token 长上下文记忆测试)从 4.6 的 78.3% 跌到 32.2%,46 个百分点的跌幅。如果你的使用场景重度依赖长上下文(比如喂整本代码库、超长文档分析),4.7 反而不如 4.6。
4.7 对指令的解读更加字面化。以前 4.6 会"意会"的模糊指令,4.7 会严格按字面意思执行。如果你有一套跑了很久的 prompt,升级后可能需要重新调一轮。
| 场景 | 推荐度 | 说明 |
|---|---|---|
| 复杂编程任务 | 强烈推荐 | SWE-bench Pro 64.3%,实测体感显著提升 |
| 视觉/Computer Use | 强烈推荐 | 精准度从 54.5% 跳到 98.5%,首次可上生产 |
| 文档/报表处理 | 强烈推荐 | OfficeQA Pro 断层领先,80.6% |
| 深度搜索/调研 | 不推荐 | BrowseComp 退步到 79.3%,不如 GPT-5.4 |
| 长上下文任务 | 不推荐 | MRCR v2 暴跌 46 个点,不如 4.6 |
| 文字创作 | 谨慎 | 多位用户反馈文字风格变得生硬 |
定价:名义不变,输入 $5/百万 token,输出 $25/百万 token。API 模型 ID 为 claude-opus-4-7,已在 Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 同步上线。
一句话总结:如果你主要用 AI 做编程、看屏幕、处理文档,升级。如果你主要做深度调研或需要超长上下文,先别急。

腾讯游戏发布的 AI 游戏创作平台,支持自然语言生成可运行游戏,覆盖 2D/3D,内置全链路 AIGC 工具和 2 万免费资产,零基础也能做出完整游戏。

Anthropic 发布 Claude Opus 4.8,代码缺陷漏报率降至前代四分之一,同步上线动态工作流支持数百子智能体并行,思考强度对所有用户开放。

GitHub开源的CodexGuide,覆盖Codex桌面端、CLI、手机端的完整使用教程,含Plus订阅、实战案例和配置指南