来自MIT和普林斯顿的开源项目,把Transformer训练中的散碎计算重写为GEMM-Epilogue模式,反向传播加速1.6-1.8倍

来自MIT和普林斯顿的开源项目,把Transformer训练中的散碎计算重写为GEMM-Epilogue模式,反向传播加速1.6-1.8倍
GPU 内核优化一直是门槛极高的领域,通常需要资深 CUDA 工程师手工调优。来自 MIT、普林斯顿、Together AI 和 Meta 的研究者发布的 CODA 项目,试图改变这个局面 -- 用一套编程抽象,让 LLM 甚至新手也能为 Transformer 写出高性能 GPU 内核。
FlashAttention 核心作者 Tri Dao 在转发时直接说:"LLM 和新手就可以编写光速内核。"
论文地址:arxiv.org/abs/2605.19269 代码地址:github.com/HanGuo97/coda-kernels
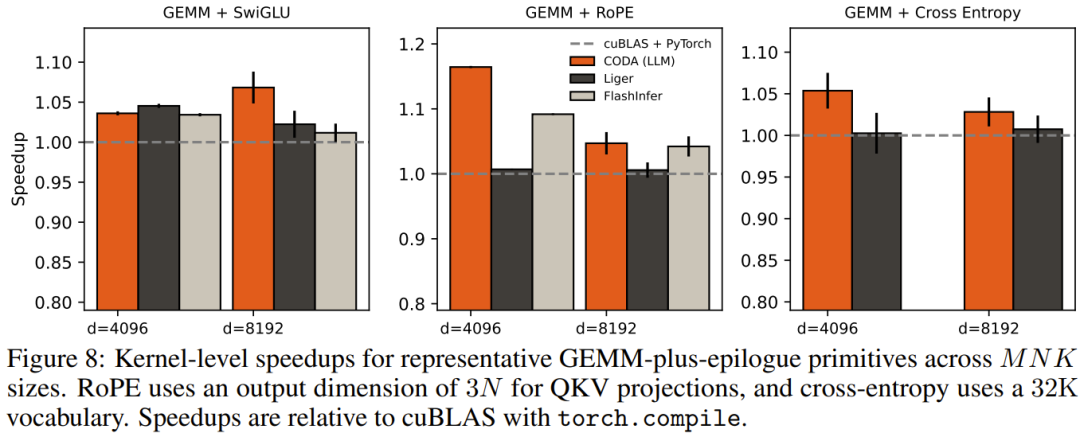
在一块 H100 上训练 LLaMA-3 风格的 1B 参数模型,矩阵乘法(GEMM)和注意力确实占主要算力。但性能分析器会揭示一批安静的"时间杀手":RMSNorm、SwiGLU、RoPE、残差加法、跨层规约。
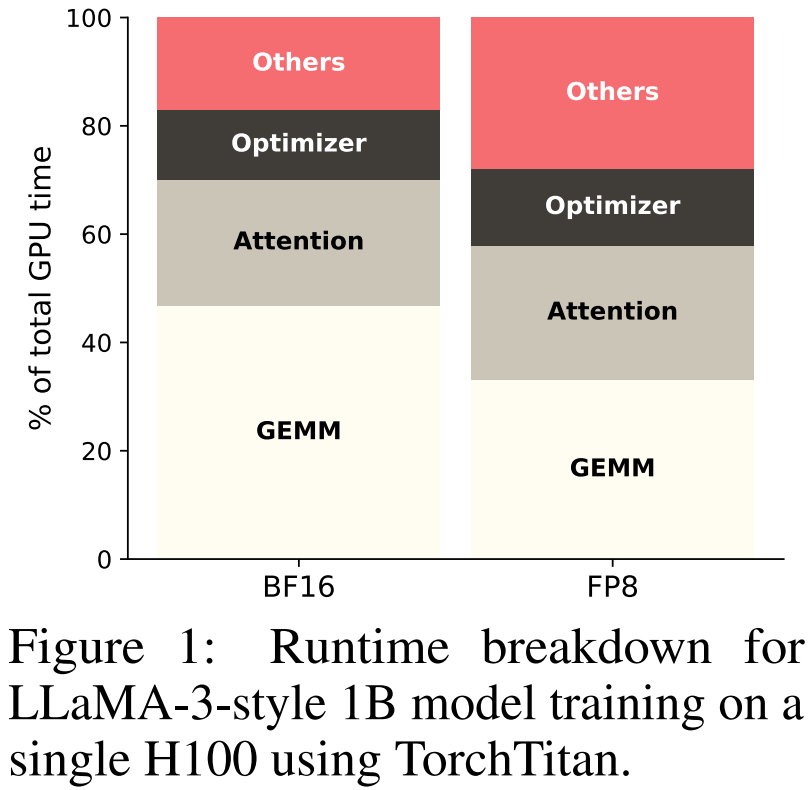
这些操作单个计算量不大,却频繁把大型中间张量从显存搬进搬出。这就是内存带宽瓶颈 -- 好比厨艺绝顶的厨师,每做一道菜都要把食材从远处仓库搬来搬去。
随着 FP8、FP4 等低精度格式让矩阵计算越来越快,这些"搬运"操作的相对成本反而在上升。PyTorch 把 Transformer 表达成一串算子序列,算子之间的边界恰好阻止了跨算子的融合优化。
GPU 上高性能矩阵乘法(GEMM)内核分两部分:
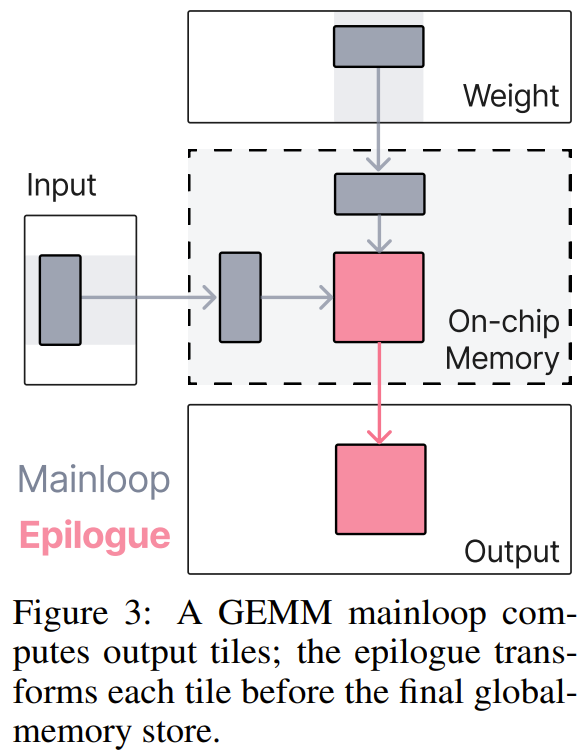
尾声存在的意义:此时矩阵乘法的输出还"活在"片上寄存器里,还没落地到全局显存。这是一个短暂的黄金窗口 -- 如果能在这个时刻多做计算,就能省掉一次显存写入再读出的往返。
CODA 的核心洞察:Transformer 里那些内存密集型操作,可以被代数地重新参数化,塞进"尾声"窗口里执行。
以最常见的 GEMM-RMSNorm-GEMM 模式为例,RMS 归一化中的行缩放因子 r 和后面的矩阵乘法满足交换律,可以把 r 的应用推迟到第二个 GEMM 的尾声。这样完整的 RMSNorm 计算就消失了。
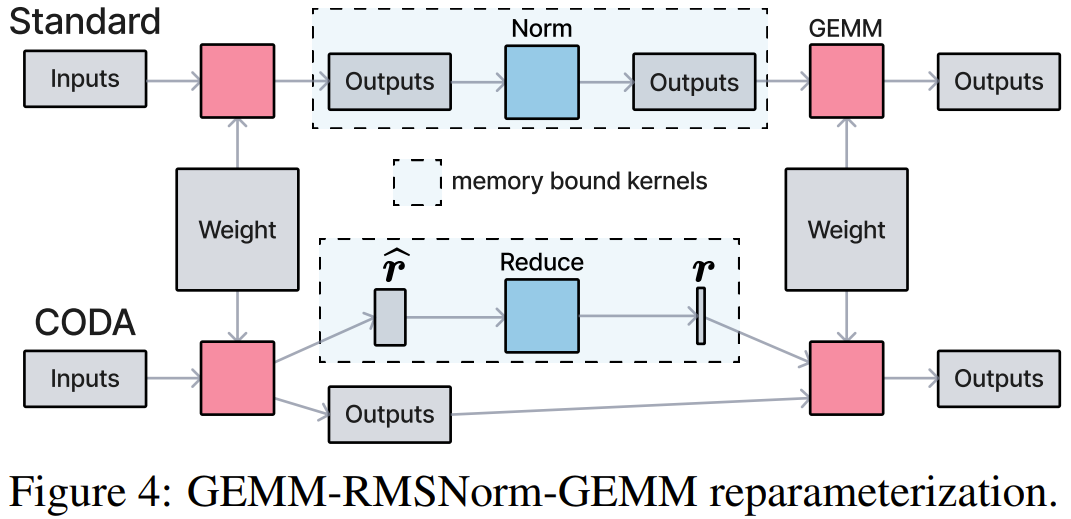
CODA 不是某个具体的融合内核,而是一套编程抽象。它固定住经过专家优化的 GEMM 主循环,然后在尾声位置暴露五类可组合的原语:
| 原语类型 | 用途 |
|---|---|
| 逐元素变换 | 残差加法、激活函数、RoPE |
| 向量加载与存储 | 广播 RMSNorm 权重 |
| 矩阵分块加载与存储 | 保存中间激活供反向传播使用 |
| 分块规约 | 局部均方根、分块 log-sum-exp |
| 有状态变换 | 在线归一化所需的 max 和 sum-exp 统计 |
用这五类积木,标准 Transformer 前向和反向传播中除注意力之外的几乎所有操作都能被覆盖。
论文评估了两种实现模式:
LLM 生成的内核在大多数基准上与人工手写版本不相上下,个别配置下甚至略有超越。在 GPU 内核优化这个历来门槛极高的领域,这是一个罕见的结论。
基准测试选择了苛刻的对手:cuBLAS + torch.compile、Liger Kernel、FlashInfer。
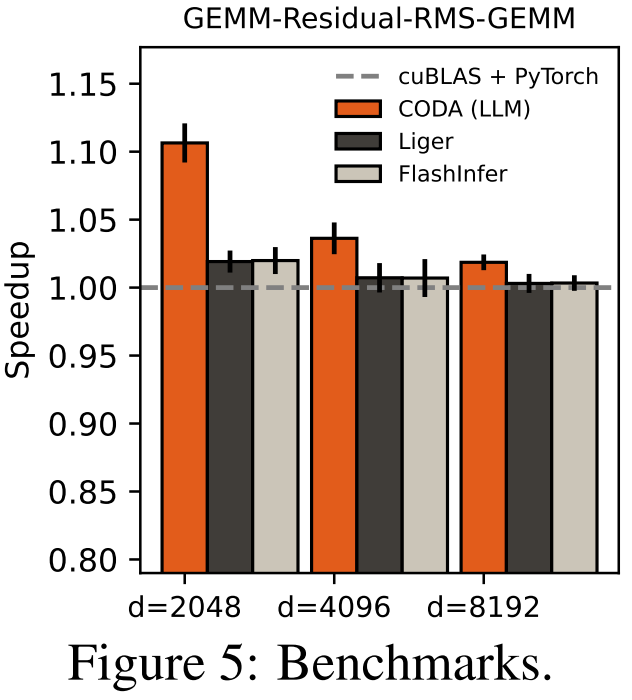
关键数据:
参考链接:

OpenAI Codex 新增 OSS 模式,支持通过 model_providers 配置接入 Ollama、LM Studio 等本地模型服务,可切换模型降低成本。

豆包专业版 68 / 200 / 500 元三档上线,核心是接入 2.1 Pro 的办公任务模式。这篇拆解定价、额度和值不值。

Codex 的 Computer Use、Chrome 插件、应用内浏览器三种操作模式各有适用场景,本文拆解权限体系并给出最佳实践。