Transformer 作者开源首个 Apache 2.0 旗舰模型,2180 亿参数 MoE 架构,单张 B200 可跑,支持 48 种语言和原生引用

Transformer 作者开源首个 Apache 2.0 旗舰模型,2180 亿参数 MoE 架构,单张 B200 可跑,支持 48 种语言和原生引用
Cohere 发布了 Command A+,这是首个采用 Apache 2.0 协议完全开源的旗舰级大模型。2180 亿总参数、250 亿激活参数的 MoE 架构,最低只需 1 张 NVIDIA B200 即可部署。对于想要私有化部署大模型的企业和开发者来说,这个模型值得关注。
Command A+ 由 Cohere(Transformer 论文作者 Aidan Gomez 创办的公司)发布,是 Command A 家族的最后一个模型,也是 Cohere 的第一个 MoE(混合专家)模型。
关键参数一览:
| 项目 | 数值 |
|---|---|
| 总参数 | 2180 亿 |
| 激活参数 | 250 亿 |
| 上下文窗口 | 128K |
| 支持语言 | 48 种 |
| 最低部署 | 1 张 B200 或 2 张 H100 |
| 许可证 | Apache 2.0 |
AI 圈的"开源"这个词已经被稀释了。很多公司放出权重却附带限制性条款:大企业不能商用、不能用来训练竞品模型。
Cohere 此前的 Command R / R+ 采用的是 CC-BY-NC 4.0(非商业许可)。但 Command A+ 切换到了 Apache 2.0,这是一个 OSI 认可的真正开源许可证。
这意味着:
Command A+ 的核心思路是两层压缩。
第一层:MoE 架构。 2180 亿参数中,每次推理只有 250 亿被激活。MoE 将问题路由给最擅长的"专家"网络,其余保持休眠。保留"巨头级"知识储备,但运行算力接近小模型。
第二层:量化。 提供 BF16、FP8 和 W4A4 三种精度版本。W4A4 是技术核心,只将 MoE 专家压到 4-bit,注意力通路保留全精度,再叠加量化感知蒸馏(Quantization-Aware Distillation)。
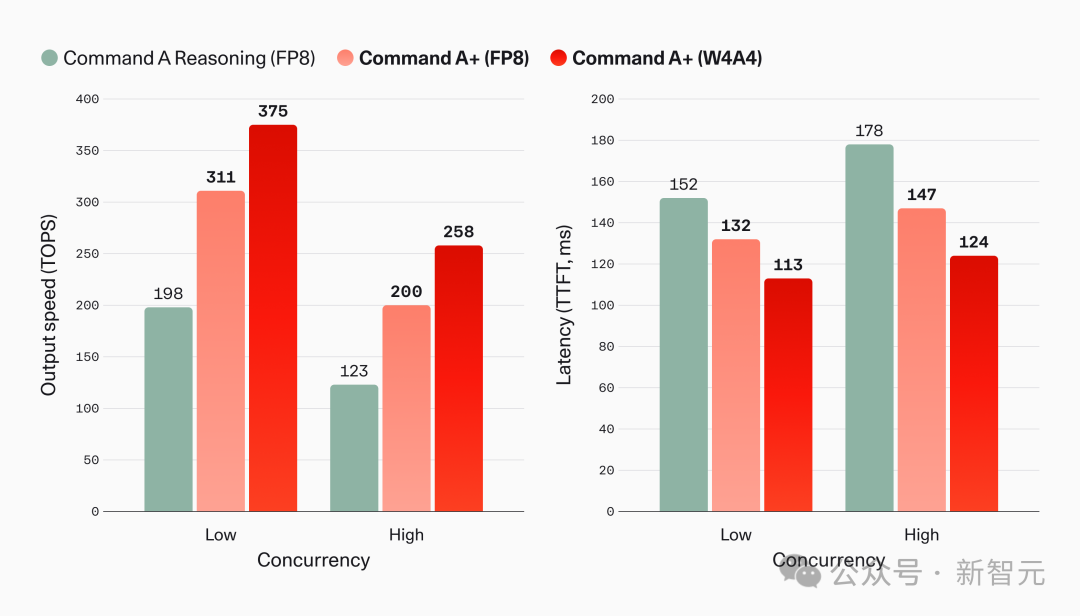
Cohere 声称 W4A4 量化方案接近无损。在低并发下达到每秒 375 个 token,首 token 延迟仅 113 毫秒。
Command A+ 做了一个原生层面的设计:当模型从外部工具检索信息时,它会生成"溯源标记"(grounding spans)。每一条事实声明都会被直接链接到具体的文档或数据库记录。
举个例子:让它出一份销售报告,它给出总销售额的同时,会明确标出提供这个数字的数据库查询结果。这种可追溯性对金融、医疗、法律等强监管行业非常重要。
据 Cohere 发布的数据:
| 基准测试 | Command A Reasoning | Command A+ |
|---|---|---|
| AIME 25 数学 | 57% | 90% |
| Terminal-Bench Hard(智能体编码) | 3% | 25% |
| 某电信推理测试 | 37% | 85% |
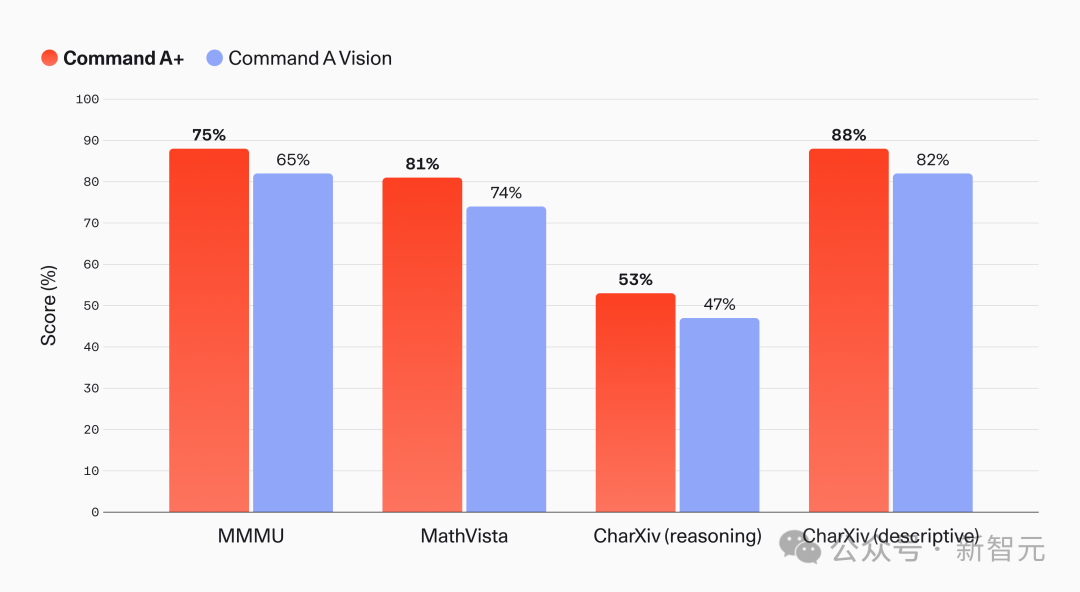
Command A+ 也是全多模态的,在 128K 输入上下文里原生处理文本和图像,适合分析扫描发票、图表和技术手册。
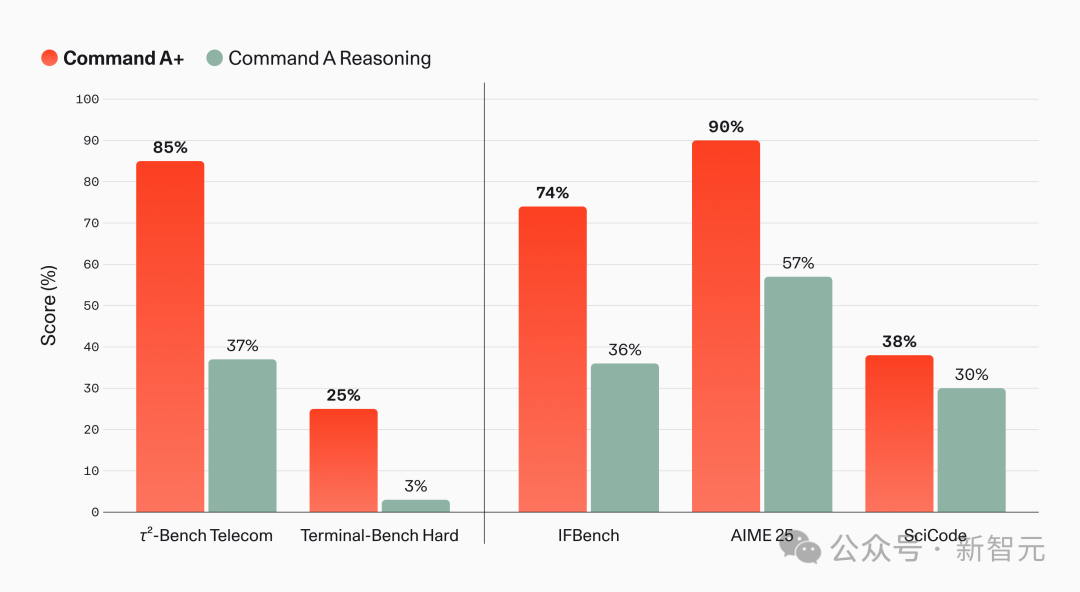
注意:以上为 Cohere 自行发布的测试数据,并非第三方独立评测。VentureBeat 指出,在深度智能体编码和综合智能的广度上,Command A+ 仍落后于 DeepSeek 等中国头部开源模型。

Seko 搭载 Seedance 2.0 全能模式,通过 Agent 工作流自动生成剧情、角色和分镜,720P 成本直降 50%,10 分钟出片。

豆包专业版 68 / 200 / 500 元三档上线,核心是接入 2.1 Pro 的办公任务模式。这篇拆解定价、额度和值不值。

DeepSeek 官方推荐的开源终端编程 Agent Deep Code,支持深度思考、推理强度调节与 Agent Skills,三步即可上手。