开源实时数字人生成方案,文本输入即可同步生成说话视频与语音,20.38 FPS吞吐、0.94秒端到端延迟

开源实时数字人生成方案,文本输入即可同步生成说话视频与语音,20.38 FPS吞吐、0.94秒端到端延迟
文本驱动音视频数字人正在从"能生成"走向"能实时交互"。来自上海创智学院、复旦大学等机构的 Hallo-Live 项目,在两张 NVIDIA H200 GPU 上实现了 20.38 FPS 的吞吐和 0.94 秒的端到端延迟,同时保持接近教师模型的视觉质量和音画同步效果。
论文地址:arxiv.org/abs/2604.23632 代码地址:github.com/fudan-generative-vision/Hallo-Live
传统的音频驱动数字人只需要对口型,但文本驱动方案要同时完成两件事:先"理解"文本里的人物、场景、语气,再同步生成对应的说话视频与语音。嘴型、发音、表情甚至上半身动作都要卡在同一个时间轴上。
相比教师模型 Ovi,Hallo-Live 的关键指标:
| 指标 | Hallo-Live | 提升 |
|---|---|---|
| 吞吐量 | 20.38 FPS | 提升 16.0 倍 |
| 端到端延迟 | 0.94 秒 | 下降 99.3% |
支持动漫风格、写实人物和多人场景,已在 GitHub 开源。
Hallo-Live 的训练分两个阶段:
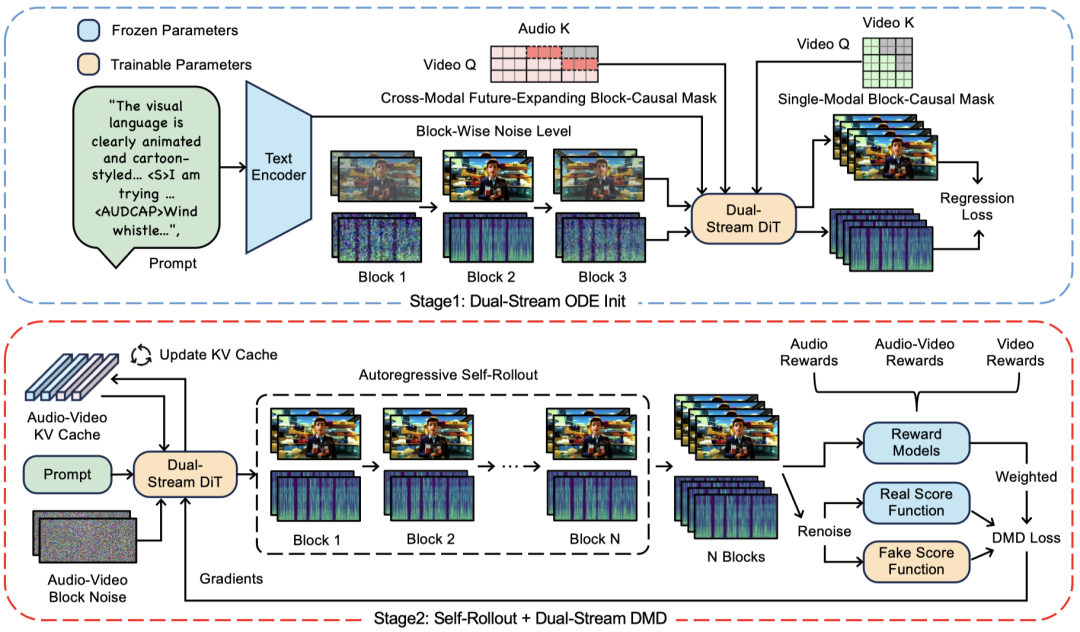
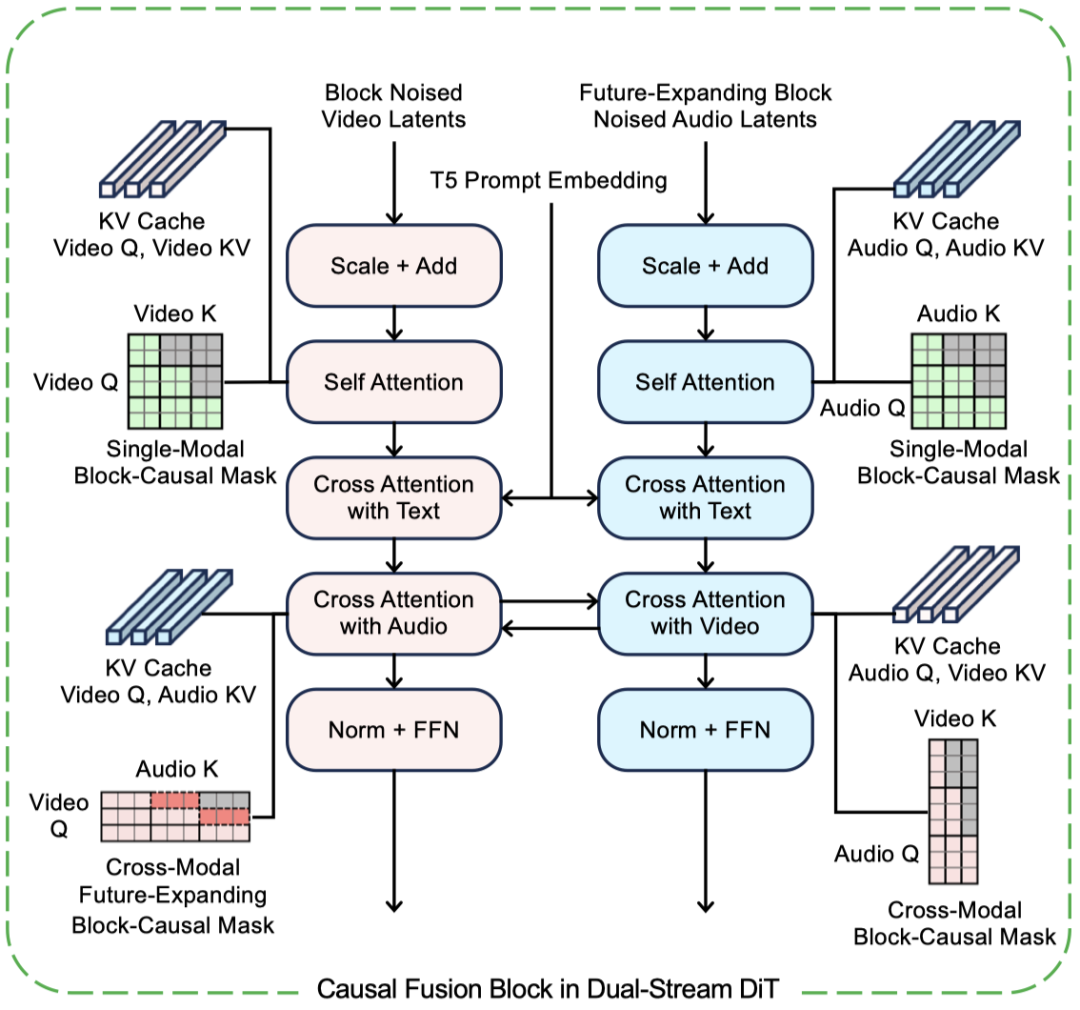
这是双流 DiT 的核心单元。视频流和音频流先分别做单模态 Block-Causal Self-Attention,再注入文本条件,随后通过跨模态 Block-Causal Cross-Attention 交换信息,在流式生成下完成音视频融合。
真实说话中,嘴唇动作往往先于声音到来(协同发音现象)。严格因果的块级注意力看不到"短时未来"语音信息,导致嘴型不自然。
Hallo-Live 把视频到音频的跨模态注意力做成"非对称"的:视频聚焦当前块,但音频键值范围额外向前扩一小段 look-ahead 窗口,相当于给视频流一个短时的"预读区"。
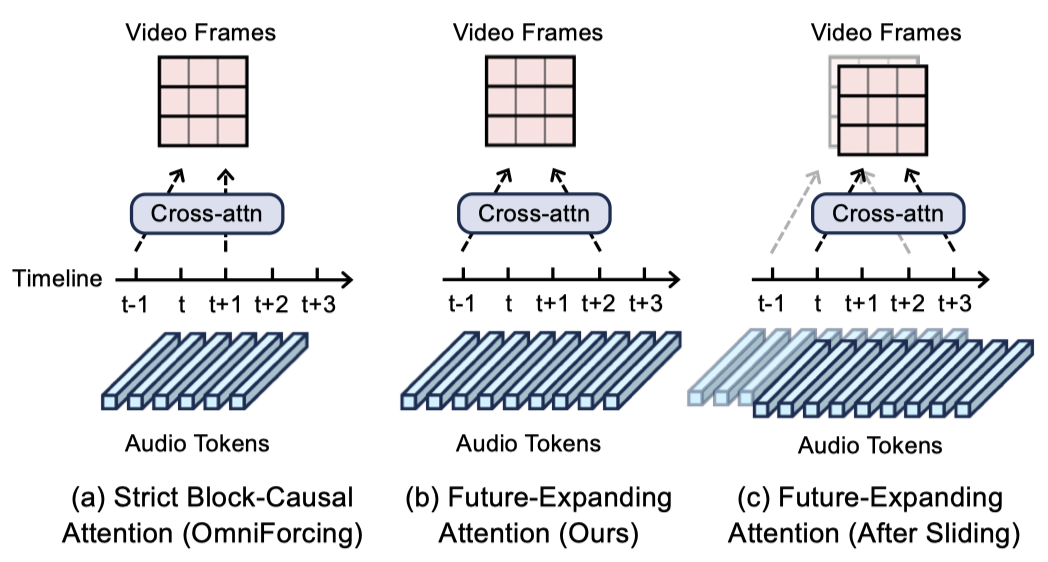
这个未来音频块不是最终输出,而是临时过渡块,不会损失音频质量。
少步蒸馏能提速,但容易带来"均值化"退化 -- 视频纹理变糊、语音更机械、音画对齐漂移。Hallo-Live 引入音频、视频和音视频同步相关的 reward,对双流 DMD 损失进行加权,在加速的同时保持生成质量。
项目已在 GitHub 开源,适合做数字人交互、实时流式生成的研究者和开发者使用。
参考链接:

DeepSeek 官方推荐的开源终端编程 Agent Deep Code,支持深度思考、推理强度调节与 Agent Skills,三步即可上手。

豆包专业版 68 / 200 / 500 元三档上线,核心是接入 2.1 Pro 的办公任务模式。这篇拆解定价、额度和值不值。

Seko 搭载 Seedance 2.0 全能模式,通过 Agent 工作流自动生成剧情、角色和分镜,720P 成本直降 50%,10 分钟出片。