Anthropic和OpenAI同时验证的结论:AI编程智能体失败的原因不在模型,在Harness。五步搭建你的第一个Harness配置

Anthropic和OpenAI同时验证的结论:AI编程智能体失败的原因不在模型,在Harness。五步搭建你的第一个Harness配置
你的 AI 编程智能体是不是经常"自信地交付一坨跑不通的代码"?问题很可能不在模型本身,而在于你有没有给它装上 Harness。
Anthropic 和 OpenAI 在 2026 年几乎同时用实验验证了同一个结论:AI 编程智能体频频失败,问题不在模型,在模型之外的 Harness 基础设施。同一个 Opus 4.5 模型,裸跑花 9 美元全部失败,配上 Harness 花 200 美元成功率达 100%。
Harness 不是工具,也不是提示词技巧,它是围绕 AI 编程智能体搭建的一整套工程基础设施,由五个子系统组成:
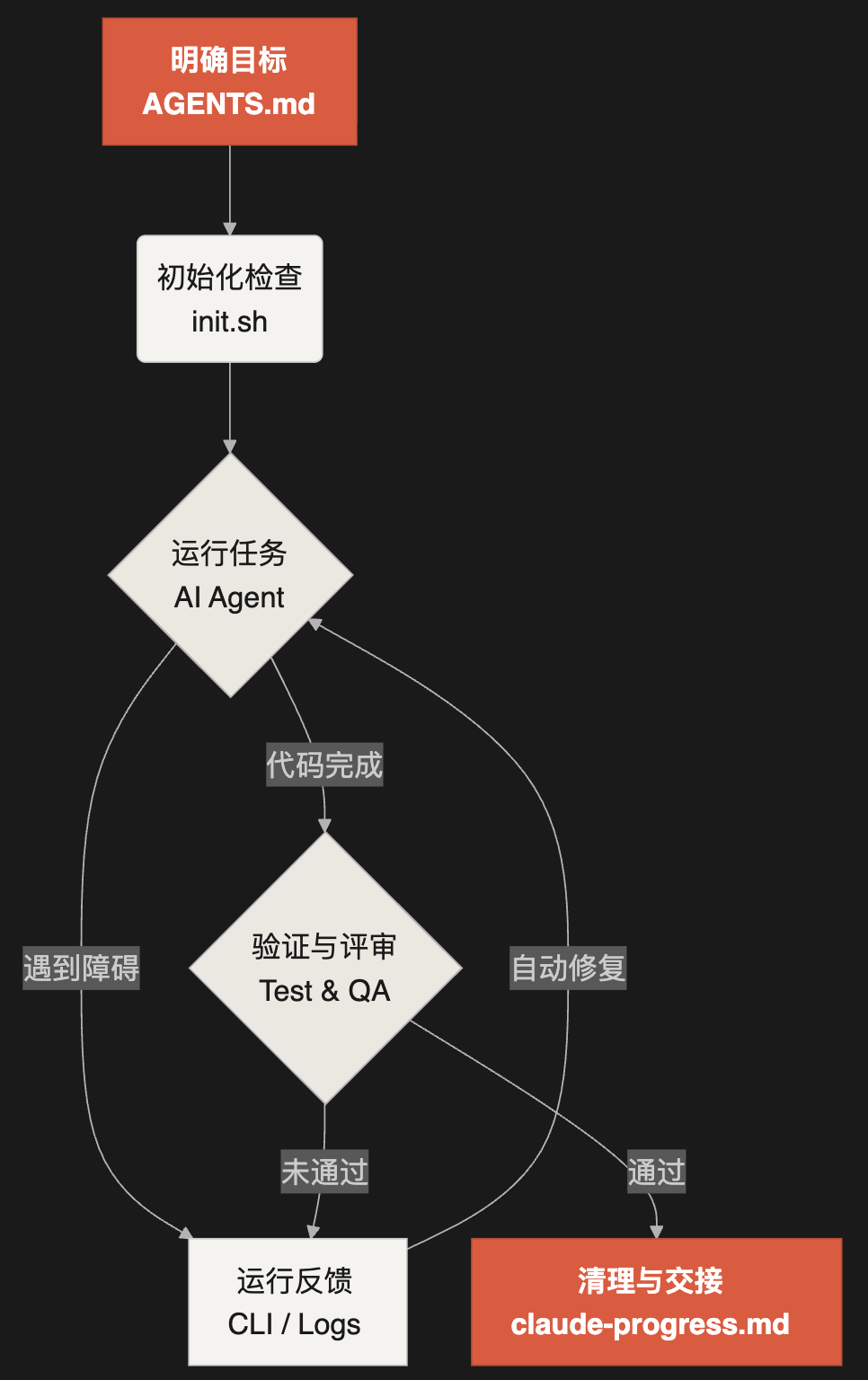
| 子系统 | 解决什么问题 | 对应文件 |
|---|---|---|
| 指令 (Instructions) | 智能体不知道项目约定,瞎写代码 | AGENTS.md / CLAUDE.md |
| 工具 (Tools) | 越权操作:rm -rf、git push --force | settings.json / config.toml |
| 环境 (Environment) | 这台能跑的到 CI 就废了 | setup.sh / Dockerfile |
| 状态 (State) | 跨会话失忆,写出冲突代码 | PROGRESS.md |
| 反馈 (Feedback) | 过早宣布胜利,代码根本跑不通 | type check / test / lint |
同一个 Opus 4.5 模型,同一道编程题:

Codex 团队在百万行真实仓库上验证。实验只改了一件事 -- 仓库根目录加了一个 AGENTS.md 文件,不到 100 行 markdown。
下面五步用文本编辑器就能完成,加起来不超过 200 行配置。
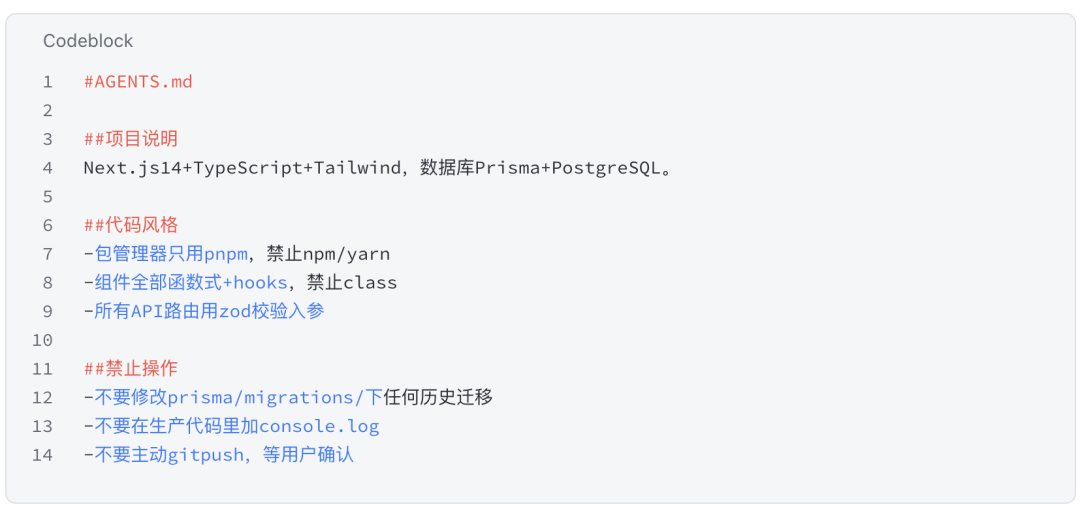
在仓库根目录创建一个 markdown 文件。OpenAI 阵营叫 AGENTS.md,Anthropic 阵营叫 CLAUDE.md。Codex、Claude Code、Cursor 启动时会自动读取并注入系统提示词。
至少写三块内容:
# Project
这是一个用 Next.js + Prisma 构建的电商后台
# Forbidden
- 禁止执行 git push --force
- 禁止删除 migrations 目录
- 禁止使用 npm(用 pnpm)
# Done means
- pnpm typecheck 通过
- pnpm test 全绿
- pnpm lint 零 error不到 15 行,就把项目约定从反复重申变成启动时自动注入。
限定智能体能调用哪些命令。
Claude Code 用 .claude/settings.json,Codex 用 ~/.codex/config.toml。
{
"permissions": {
"allow": ["pnpm install", "pnpm test", "pnpm typecheck"],
"deny": ["rm -rf", "git push --force", "DROP TABLE"]
}
}允许的直接跑,禁止的直接拒,灰色地带的弹确认。

锁定依赖版本、运行时配置。已有 Dockerfile / devcontainer.json 可跳过,否则写一个 setup.sh。
关键一行:
pnpm install --frozen-lockfile--frozen-lockfile 确保智能体无法擅自升级任何依赖。

touch PROGRESS.md四个板块:已完成、进行中、待办、已知问题。提交进 git,当成项目自身的一部分维护。
在 AGENTS.md 里固化约定:
## Rules
- 新会话第一件事:读 PROGRESS.md
- 任务完成或断点变化:立即回写 PROGRESS.md
- 冲突时以代码为准 -- 仓库是唯一事实来源
在 AGENTS.md 末尾写明验证命令:
## Done Definition
Task is NOT done until ALL of these pass:
- pnpm typecheck (exit code 0)
- pnpm test (exit code 0)
- pnpm lint (exit code 0)
- pnpm build (exit code 0)退出码不为 0,任务就不算完成。如果项目还没有这些命令,今天就配上。
核心教训:前四步全做对,第五步缺位,依然全废。没有反馈循环,Harness 等于没装。
Anthropic 和 OpenAI 的实验指向了智能体最常见的三种失败:
智能体写完 500 行功能就输出"已完成"。合并代码 -- CI 红屏,type check 报 12 个错,单测一个没跑过。
解法:反馈子系统。判定权交给退出码 -- 退出码 != 0,任务 != 完成。
长任务做到 70%,上下文 Token 快撑满。智能体开始赶进度 -- 跳过测试、删边界处理、写 stub 收尾。
解法:状态子系统 + 主动重启。上下文 Token 用量超 70% 时,主动停下、写完断点、开新会话。
第一个会话写了用户模块,第二个会话又写了一遍 getUserById,接口签名冲突。
解法:PROGRESS.md 维护已完成功能清单 + AGENTS.md 写明首读约定。

模型能力决定上限,Harness 决定你能用到上限的几成。
没有 Harness,Opus 4.5 跑出的代码连编译都过不去;有了 Harness,小一档的模型也能稳定交付。与其等下一个更强的模型,先把 Harness 装好。
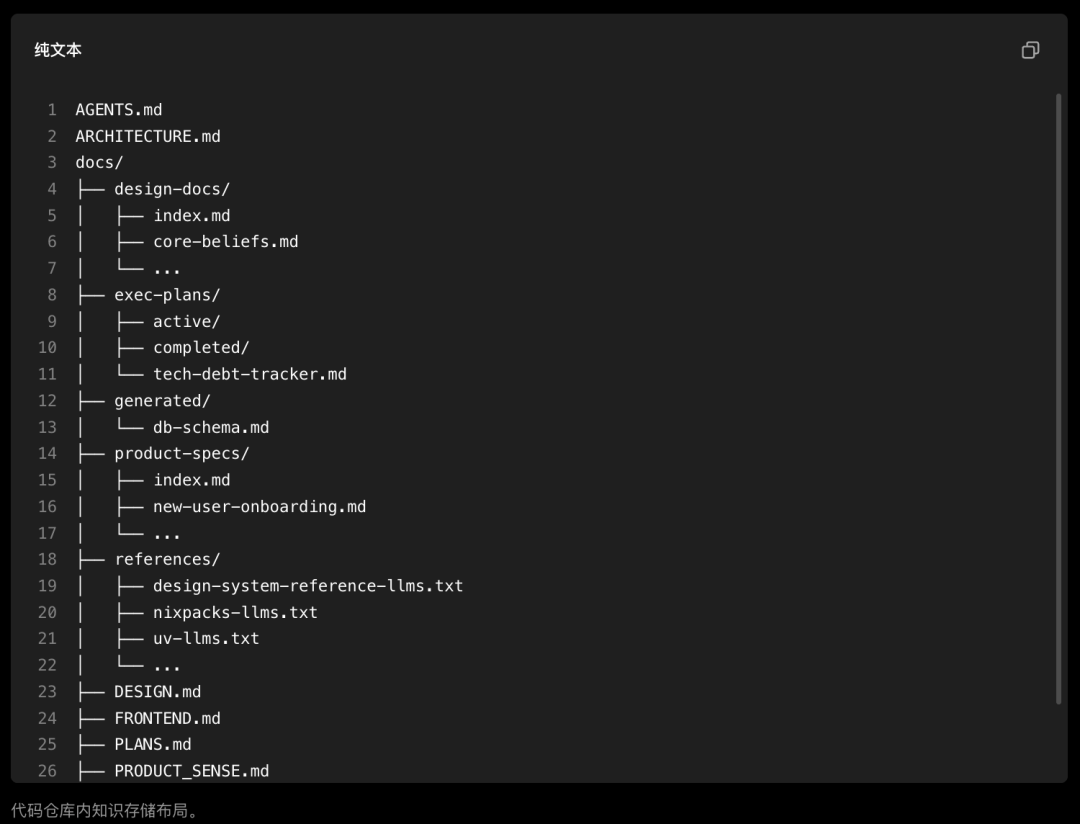
参考资源:

豆包专业版 68 / 200 / 500 元三档上线,核心是接入 2.1 Pro 的办公任务模式。这篇拆解定价、额度和值不值。

Seko 搭载 Seedance 2.0 全能模式,通过 Agent 工作流自动生成剧情、角色和分镜,720P 成本直降 50%,10 分钟出片。

DeepSeek 官方推荐的开源终端编程 Agent Deep Code,支持深度思考、推理强度调节与 Agent Skills,三步即可上手。