京东开源的AI长视频生成框架,一次生成长达5分钟的跨镜头音视频,支持局部修改,告别盲盒式抽卡。

京东开源的AI长视频生成框架,一次生成长达5分钟的跨镜头音视频,支持局部修改,告别盲盒式抽卡。
AI 视频生成一直卡在"短视频"这道坎上。市面上的模型大多只能生成 20 秒以内的片段,一旦拉到分钟级,角色跨镜头变脸、声音漂移、改一个镜头就要全部重来,让 AI 长视频始终停留在 demo 阶段。
京东近期开源的 JoyAI-Echo 框架试图打破这个瓶颈。它能够一次生成长达 5 分钟的跨镜头音视频,保证角色面部和说话音色全程一致,支持通过自然语言进行局部修改,代码和权重均已公开。
JoyAI-Echo 是京东开源的长音视频生成框架。和市面上常见的短视频生成模型不同,它专注于解决"长时一致性"这个核心问题——让同一个角色在五分钟内、十几个镜头切换中始终保持同一张脸、同一把声音。
目前代码和权重文件均已在 GitHub 公开,可免费下载使用。
传统 AI 视频最大的痛点是"变脸"。JoyAI-Echo 通过"槽位配对"音视频记忆交互机制,将每个角色的面部特征和声音进行绑定。生成新镜头时,系统从记忆库中检索对应角色的视觉和音频标记,确保跨镜头一致性。
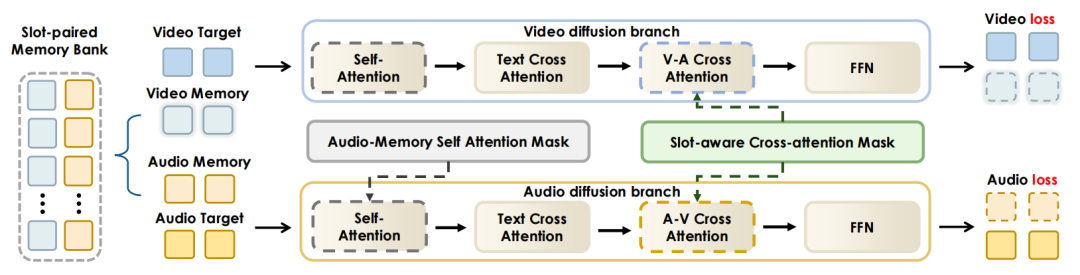
槽位配对视听记忆交互机制:每个历史事件包含对齐的视觉和音频记忆标记,配对的视觉与音频记忆槽位之间一一对应交互,防止跨事件的人脸与声音混淆。
过去修改一个镜头,需要重新生成整条视频。JoyAI-Echo 引入了 Director Agent(导演智能体),支持用自然语言指挥 AI 进行局部修改。不满意某个镜头?直接告诉它"把这段追逐场景的背景改成雨天",系统会自动定位该镜头并重绘,其他镜头不受影响。
Director Agent 将长视频生成划分为规划、生成和评审三个阶段,支持利用局部反馈进行非线性修改。
通过联合单步超分架构(Unified One-Step SR),JoyAI-Echo 支持流式延迟约束下的两档实时超分,最高可直接输出 1472x2560 分辨率的高清视频。单个扩散流前向步骤即可将 720p 扩展至 2K 画质。
传统 AI 视频训练依赖优化单镜头质量的平铺式数据集,模型只学过短时间内画面怎么画,但没理解过同一角色在不同时空下的视觉连贯性。JoyAI-Echo 构建了全新的身份向心型视频语料库(Identity-Centric Video Corpus),从电影、电视剧和长视频中提取了超过 100 万个角色身份原型,确保生成内容的一致性。
放弃端到端生成,采用基于渐进演化记忆库(Evolving Memory Bank)的迭代分镜合成机制。在生成阶段,目标视频和音频标记由两个扩散分支处理,记忆标记仅作为条件上下文使用,不参与损失计算。
在包含 100 个剧本故事、3000 个顺序镜头的超长生成基准评测集上,JoyAI-Echo 的台词准确率达到 0.8646,视听一致性各项指标均位列前茅。
提示: 该项目需要一定的 GPU 算力支撑。如需生成 2K 分辨率视频,建议使用显存 24GB 以上的显卡。

GPT Image 2 上线即登顶 Arena 文生图榜,领先第二名 241 分,具备原生思考能力,文字渲染准确率 99%,API 出图仅 $0.21。

Meshy AI 发布新一代 3D 模型生成模型 Meshy 6,支持单图生成高精度雕塑级模型,覆盖游戏、3D打印等场景,累计用户已破千万。

Anthropic为Claude新增交互式图表和流程图功能,免费用户可用,支持生成可点击的周期表、时间线、决策树等可视化内容。