字节跳动开源Lance,仅3B激活参数的原生统一多模态模型,同时覆盖图像视频的理解、生成和编辑,开源即登Hugging Face Trending第一。

字节跳动开源Lance,仅3B激活参数的原生统一多模态模型,同时覆盖图像视频的理解、生成和编辑,开源即登Hugging Face Trending第一。
字节跳动Intelligent Creation Lab开源了Lance——一个激活参数仅3B的原生统一多模态模型。它把图像和视频的理解、生成、编辑全部塞进了同一个模型里,开源即登Hugging Face Trending第一。
在动辄几十B、上百B参数的多模态模型里,3B的Lance是一股清流。但它不是在某个单项上刷分,而是把"看、画、改"放到同一张考卷上一起考。
Lance覆盖6类任务:
| 任务类型 | 能力 |
|---|---|
| 图像/视频理解 | OCR、知识问答、多图理解、视频问答 |
| 文生图 | 复杂文本指令下的图像生成 |
| 文生视频 | 自然运动、时序一致的视频生成 |
| 图像/视频编辑 | 主体增删、局部替换、风格迁移 |
Lance不只是改一张关键帧。比如可以连续操作:先把短直发改成法式卷发,再加红白花朵发箍,最后把背景换成湖边童话城堡。关键是人物还是同一个人,动作不乱,前后帧不闪。
覆盖背景改变、材质修改、动作改变、人像美化、主体移除、替换和色调迁移。核心要求是听懂自然语言指令,同时保持主体身份和画面一致性。
豆包上线专业版,搭载豆包 2.1 Pro 的 Agent 驱动办公任务模式,能操作本地电脑、分析财报、自建 Skill,实测交付质量对标 Claude Opus。
Lance的核心思路是两件事:
1. 统一上下文 把文本、图像、视频都放进同一个交错多模态上下文里。
2. 双流解耦 理解和生成的能力路径拆开,避免互相打架:
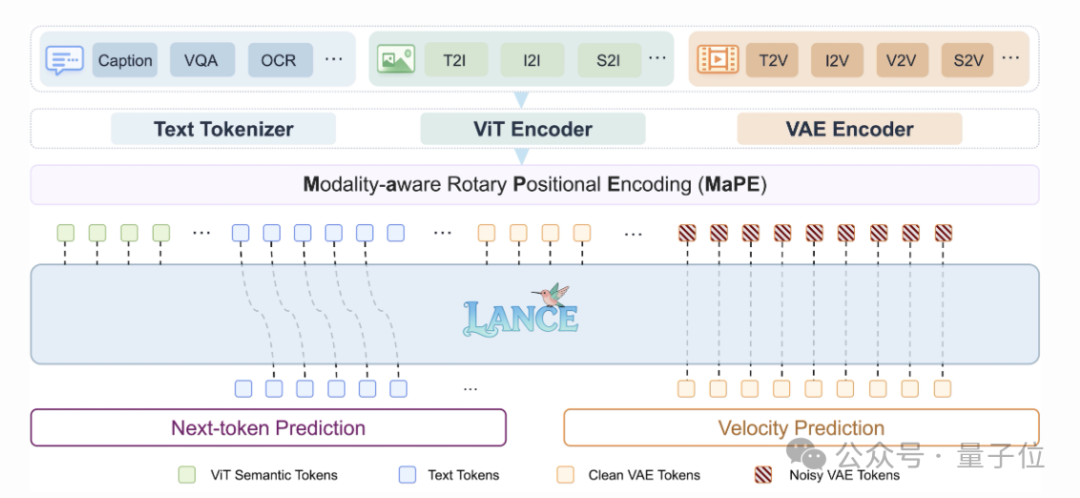
还有一个关键设计叫MaPE(Modality-Aware Rotary Positional Encoding),在时间维度里加入模态/功能组信息,让模型区分哪些token是用来理解的,哪些是生成条件,哪些是生成目标。
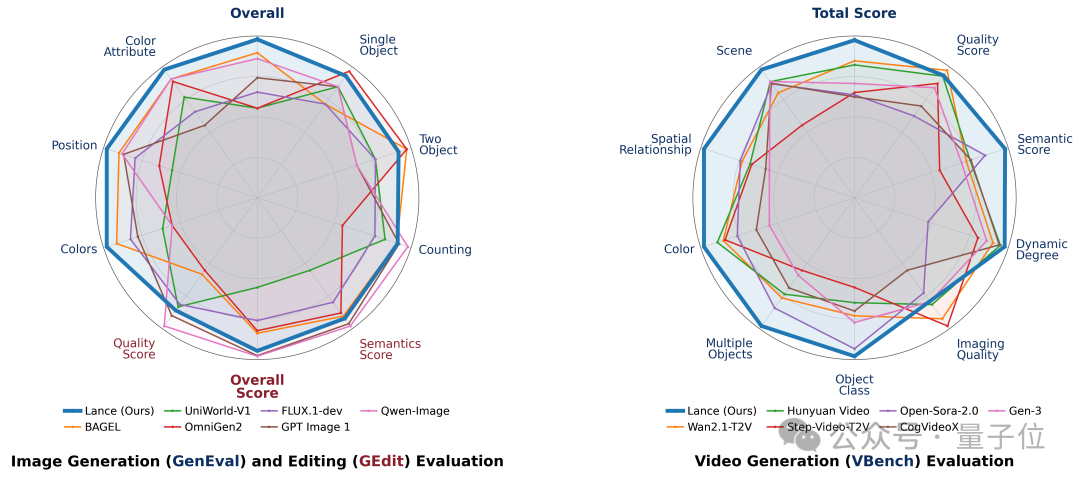
| 基准 | 分数 | 说明 |
|---|---|---|
| VBench(视频生成) | 85.11 | 统一模型中领先 |
| MVBench(视频理解) | 62.0 | 统一模型中最佳,比第二名高11.3% |
| GenEval(图像生成) | 0.90 | 与最佳总体分数持平 |
| GEdit-Bench(图像编辑) | 7.30 | 统一模型中最佳平均表现 |
一个有意思的发现:加入视频生成和编辑能力后,视频理解能力并没有被拖垮,反而多任务数据可能帮助模型学到更强的跨任务迁移。
提示: 3B的参数量意味着可以在消费级GPU上运行,不需要A100或H100级别的硬件。但视频生成和编辑的质量与顶级闭源模型仍有差距,适合作为基线和原型验证。


