基于 Karpathy LLM Wiki 方法论改进的三步编译法,将 Obsidian 笔记从信息垃圾场变成持续进化的知识资产,附完整目录结构和提示词。

基于 Karpathy LLM Wiki 方法论改进的三步编译法,将 Obsidian 笔记从信息垃圾场变成持续进化的知识资产,附完整目录结构和提示词。
完整使用指南:用快捷键 Cmd+K 在几个月甚至几年前的 ChatGPT 对话里检索代码片段、方案和提示词。
你的笔记库里塞了几百篇文章,但同一个问题问 AI 两次,答案不一样。概念定义互相冲突,大量文章从来没人引用过。知识库变成了信息垃圾场。这篇文章介绍一套基于 Karpathy LLM Wiki 方法论改进的三步编译法,帮你用 Claude Code + Obsidian 把知识库变成持续进化的资产。
Karpathy(OpenAI 联合创始人)在 2026 年 4 月公开了他的知识管理方案 LLM Wiki。核心思路一句话:别在提问时才去翻原始文档,让 LLM 提前把所有资料编译成一个持久的 Wiki。
典型的 2.0 系统是"提问时才翻":200 篇资料扔在那里,写文章时让 AI 现搜现读现拼。每次从零开始,同一个问题换个对话窗口问就可能得到不同答案。
3.0 反过来:原始文档先经过 LLM "编译",变成结构化的概念条目、方法论页面、交叉引用网络。编译完之后,知识是一个持久资产 -- 矛盾已经标记了,交叉引用已经建好了,新资料加入时增量更新。
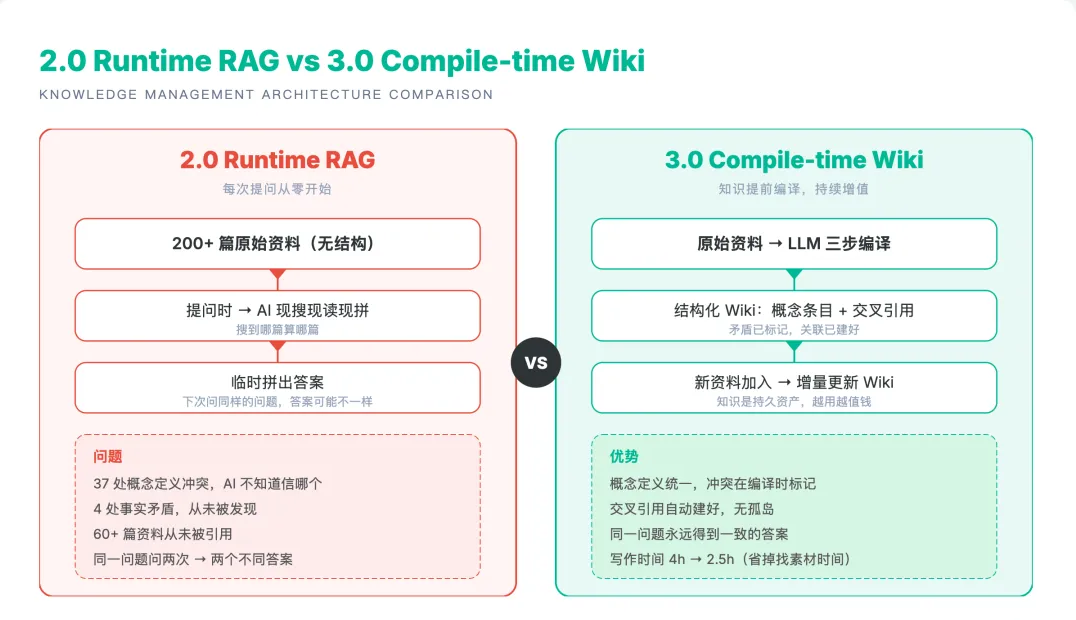
2.0 Runtime RAG vs 3.0 Compile-time Wiki 架构对比
预计搭建时间 1-2 小时。
核心就两个文件夹:raw/ 存原始资料只读不改,wiki/ 存 LLM 编译产物。你负责往 raw/ 塞文章,LLM 负责编译到 wiki/。
直接复制以下结构:
你的Obsidian仓库/
├── 02_Research/
│ ├── raw/ # 原始资料(只读)
│ │ ├── articles/ # Web Clipper 剪藏的文章
│ │ ├── reports/ # 行业报告
│ │ └── competitors/ # 竞品分析
│ └── wiki/ # 编译产物(LLM 维护)
│ ├── summaries/ # 逐篇编译摘要
│ ├── concepts/ # 概念条目(核心)
│ ├── methods/ # 方法论页面
│ └── indexes/
│ ├── index.md # 全局索引
│ └── log.md # 操作日志
└── CLAUDE.md # 编译规则写在这里在 CLAUDE.md 里添加编译规则:
### 知识编译规则
当用户说「编译 {文件路径}」时,执行以下步骤:
1. 读取 raw/ 下的指定文件
2. 执行三步编译法(浓缩 → 质疑 → 对标)
3. 在 wiki/summaries/ 写编译摘要
4. 在 wiki/concepts/ 创建或更新相关概念条目
- 如果概念已存在,合并新信息,标注来源差异
- 如果两篇文章观点矛盾,在条目中显式标记冲突
5. 更新 wiki/indexes/index.md(追加来源 + 关联概念)
6. 更新 wiki/indexes/log.md(追加操作记录)
概念条目模板:
---
concept: {概念名}
sources: [{来源文章1}, {来源文章2}]
last_updated: {日期}
---
Karpathy 的编译流程是读原文、写摘要、提取概念、更新索引。但这有一个盲区:摘要只压缩信息,不生成新知识。两篇观点相反的文章,分别编译后的摘要可能结论一样。
我在此基础上加了两个步骤:
砍到只剩核心结论(不超过 3 条)+ 关键证据。用剃刀法则:删掉这条信息会影响理解吗?不会就删。
这是跟 Karpathy 方案的关键差异。针对每条核心结论,回答四个问题:
跨领域找类似现象。其他领域有没有类似现象?这个知识可以迁移到哪些场景?如果有跨域关联,创建或更新对应的概念条目。
完整编译提示词:
请对以下文章执行三步编译法:
### 第一步:浓缩
- 用剃刀法则:删掉这条信息会影响理解吗?不会就删
- 输出:核心结论(不超过 3 条)+ 支撑每条结论的关键证据
- 格式:每条结论一行,证据缩进在下方
### 第二步:质疑
针对每条核心结论,回答:
1. 这个结论依赖哪些前提假设?
2. 如果这些前提不成立,结论还成立吗?
3. 作者的数据来源可靠吗?样本量、时间范围、地域限制?
4. 有没有作者没提到的反例或边界条件?
### 第三步:对标
1. 其他领域有没有类似现象?
2. 这个知识可以迁移到哪些场景?
3. 如果有跨域关联,创建或更新对应的概念条目
用 Obsidian Web Clipper 剪一篇文章到 raw/articles/,然后对 Claude Code 说:
编译 02_Research/raw/articles/2026-04-tiktok-shop-选品策略.mdClaude Code 会执行 6 个动作:
wiki/summaries/ 写编译摘要wiki/concepts/ 下创建或更新相关概念条目wiki/indexes/index.mdwiki/indexes/log.md 追加操作记录一篇原始文章,涉及 7 个 Wiki 文件的创建或更新。
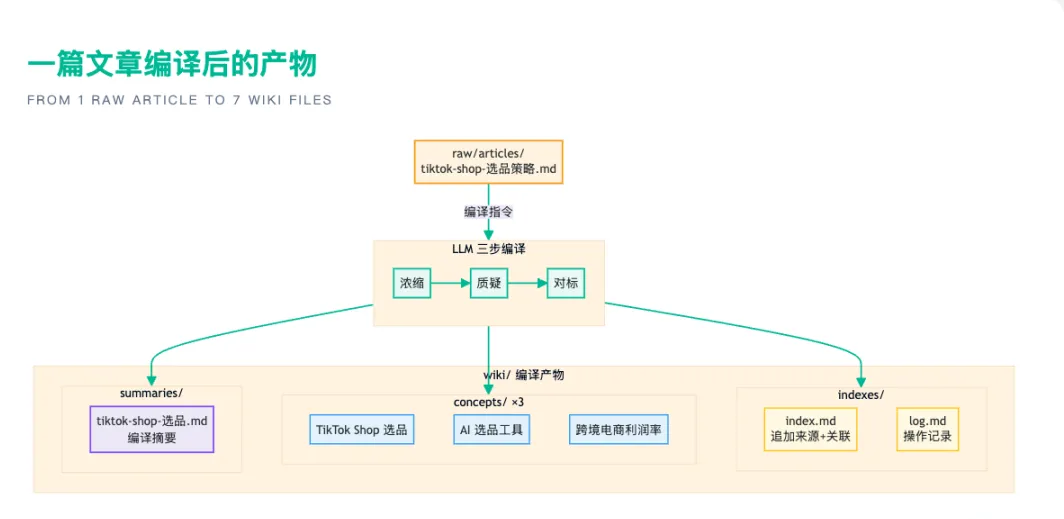
一篇文章编译后的产物:1 篇原始文章变成 7 个 Wiki 文件
关键在于:下次再编译一篇相关的文章时,AI 不是从零开始。它会读取已有的概念条目,把新信息跟旧信息合并,标注异同。如果有矛盾,直接在条目里标记。
参考以下提示词定期检查知识库状态:
对 wiki/ 目录执行健康检查,生成报告:
### 1. 一致性检查
扫描所有 concepts/ 下的条目,检查:
- 同一个概念在不同条目中的定义是否一致
- 如果不一致,列出冲突位置和建议统一方向
### 2. 完整性检查
检查每个概念条目是否包含所有必填字段:
- 定义、关键数据点、前提与局限性、关联概念
- 缺失字段标记为待补充
### 3. 孤岛检测
找出入链和出链都少于 2 的页面
- 这些页面要么需要跟其他概念建立关联
- 要么说明它不够重要可以考虑合并
### 4. 跨目录一致性(多账号场景)
扫描各账号的 _style-guide.md 和 CLAUDE.md
检查风格规则有没有遗漏或冲突
维护知识库最繁琐的部分 -- 更新交叉引用、保持定义一致、标注矛盾 -- 这些活的成本增速超过了它带来的价值。LLM 把这个成本打到了接近零。它可以在一次操作中同时修改 15 个文件,不会忘,不会烦。
这不是方法论多先进,是维护成本终于低到可以忽略了。
LLM 可以一次操作中同时修改多个文件,自动化完成交叉引用和冲突标记


