华中科大×小红书开源的 MOCR,不只识别文字,还能把文档里的图表、公式、流程图全部解析为结构化代码

华中科大×小红书开源的 MOCR,不只识别文字,还能把文档里的图表、公式、流程图全部解析为结构化代码
你用 OCR 扫描一份技术报告,文字识别得很准,但报告里最重要的那张柱状图呢?被裁成一张图片,丢掉了。
传统 OCR 的处理方式:
问题在于:文档里大量的结构化语义信息在解析环节就被永久性地丢弃了。一张精心绘制的柱状图,可能浓缩了整份报告的核心结论;一个化学分子结构式,承载着关键的实验信息。
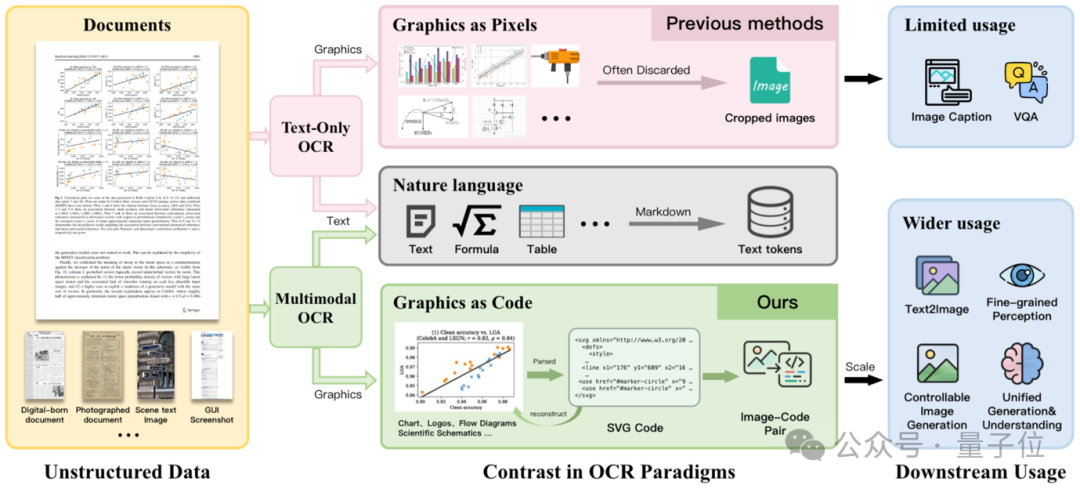
华中科技大学与小红书 hi lab 联合推出的 MOCR(Multimodal OCR) 提出了一个大胆的新范式:
不只识别文字,而是「解析一切」——文字、表格、图表、公式、流程图、化学结构式、UI 组件……通通变成可编辑、可渲染的结构化代码。
1. 文档解析
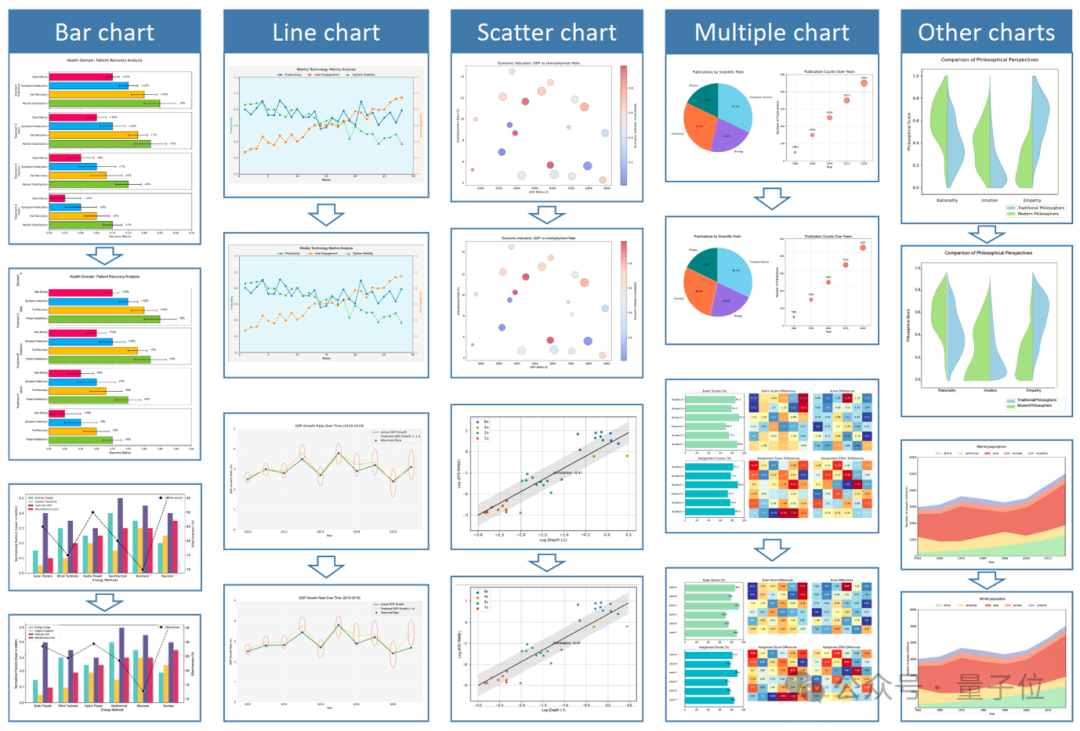
2. 图形重建
大多数视觉-语言模型会直接复用 CLIP 或 SigLIP 等预训练视觉编码器,但这些编码器是为自然图像设计的,对文档场景中的精细文字和几何图元感知能力不足。
MOCR 的 1.2B 参数视觉编码器完全从零训练,支持约 1100 万像素的原生高分辨率输入,不做降采样。
阶段一:建立视觉-语言接口 让语言模型学会可靠地消费视觉 token
阶段二:广泛预训练 混合通用视觉数据与纯文本文档解析监督
阶段三:MOCR 专项强化 降低通用视觉数据比例,加大多模态文档解析权重,重点强化图形转 SVG 的能力
传统方式:
用 MOCR:
痛点:
MOCR 方案:
需求:
MOCR 能力:
传统的 OCR 评估指标(如 WER、NED、TEDS)依赖规则化的字符串匹配,但对于复杂的 Markdown 输出来说过于脆弱。
OCR Arena 框架:
核心价值:
适合谁:
局限性:
论文地址:https://arxiv.org/abs/2603.13032 代码仓库:https://github.com/rednote-hilab/dots.mocr 研究团队:华中科技大学 × 小红书 hi lab

微信原生 AI 助手小微开放灰测,基于腾讯自研 WeLM 模型,支持发消息、查账、分析朋友圈,但暂不支持定时发送和批量操作。

港大阿里联合开源 FineVLA 可控 VLA 框架,支持通过语言指定执行臂、接触区域等细节,RoboTwin 仿真成功率 86.8%。

阿里发布视频生成模型 HappyHorse 1.1,五大维度升级,1080P 每秒 1.2 元降为 0.9 元,附实测对比与体验地址。