微软开源的文本空间优化框架,让Agent的技能文档自动进化,52项评测全部达到最优。

微软开源的文本空间优化框架,让Agent的技能文档自动进化,52项评测全部达到最优。
你有没有发现,写Agent技能文档(CLAUDE.md、Codex skill文件、system prompt)本质上就是一场手工试错?写一版,跑几个任务,效果不好再改,改完再跑。微软开源的 SkillOpt 把这个过程自动化了——它把技能文档当作「可训练参数」,用类似训练神经网络的循环来优化你的Agent技能文档。
在7个模型、6个基准测试、3种执行环境的全部52个评测组合中,SkillOpt训练出的技能文档全部达到最优或并列最优。GitHub上线一周收获3.3k star。
SkillOpt 是微软开源的文本空间优化框架。核心思路:不训练模型权重,只训练那份指导Agent行为的自然语言技能文档。把技能文档当成Agent的「外部权重」,既然内部权重可以用梯度下降来优化,外部权重也应该有一套系统化的训练方法。

关键资源:
SkillOpt 的训练循环直接对标深度学习的「前向传播-反向传播-参数更新」,但在文本空间中执行。
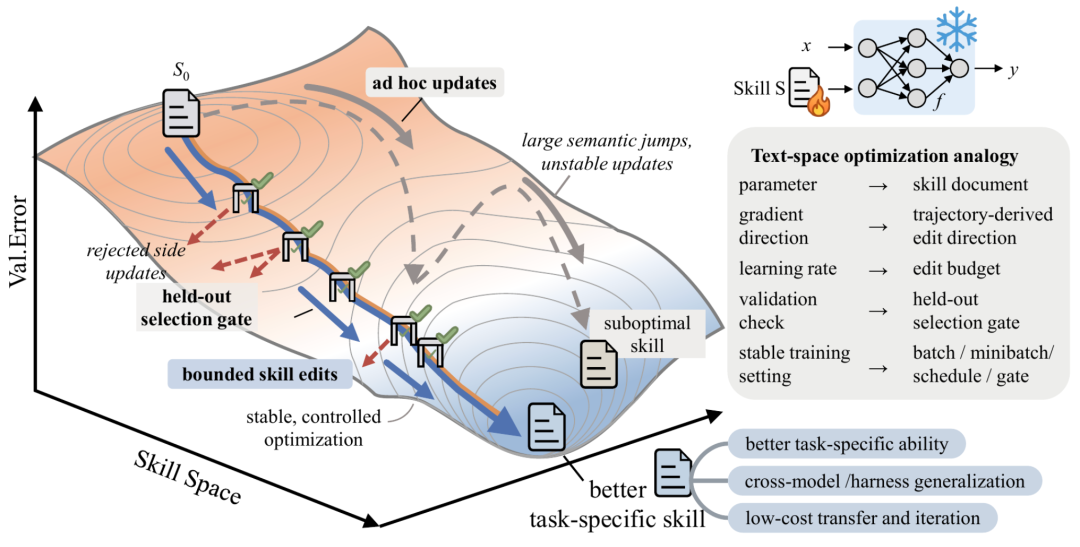
冻结的目标模型拿着当前版本的技能文档去执行一批任务,记录完整的执行轨迹——包括消息、工具调用、验证反馈和最终得分。这一步产出的是「证据」,相当于神经网络的前向传播结果。
一个独立的优化器模型分析这批执行轨迹。关键设计:失败案例和成功案例被分开反思。失败的minibatch用来发现「哪些操作规则需要修正」,成功的minibatch用来确认「哪些现有规则在起作用,不能动」。这相当于计算「文本空间的梯度」。
优化器模型基于反思结果,提出对技能文档的结构化编辑操作:添加新规则(add)、删除失效规则(delete)、替换需要修正的规则(replace)。
候选的新技能文档必须在一个held-out验证集上跑一遍,只有性能严格提升时才被接受。这防止过拟合,确保每次更新都是真正的改进。
整个循环跑多个epoch,每个epoch内跑多个step,和训练神经网络的节奏完全一致。
训练神经网络时,学习率太大会导致灾难性遗忘。SkillOpt在文本空间遇到完全相同的问题——一次编辑改动太大,可能把之前学到的有效规则覆盖掉。
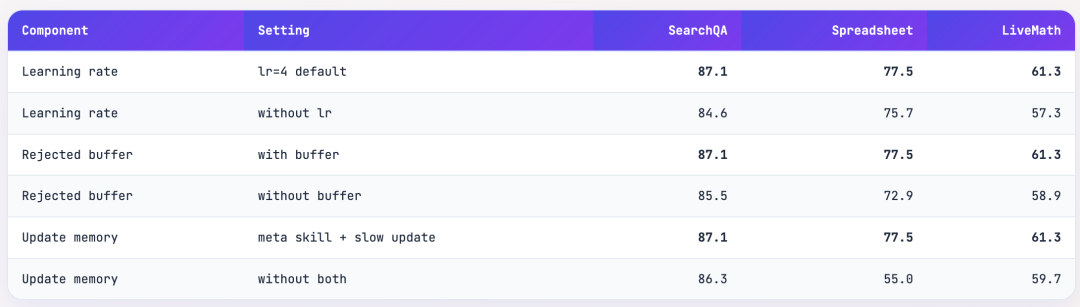
解决方案是「文本学习率」:每一步允许的编辑操作数量有上限,默认 lr=4,即每步最多4个add/delete/replace操作。消融实验验证了这个设计的必要性:去掉学习率约束后,SearchQA性能从87.1%降到84.6%,SpreadsheetBench从77.5%降到75.7%。
当一个编辑提案被验证门控拒绝时,它不会被简单丢弃,而是进入一个缓冲区。优化器在后续的反思阶段可以看到这些「失败的尝试」,避免重复提出类似的无效编辑。这相当于给优化器提供了负梯度信息。去掉这个缓冲区后,SpreadsheetBench从77.5%骤降到72.9%。
SkillOpt的评测覆盖面相当全面:
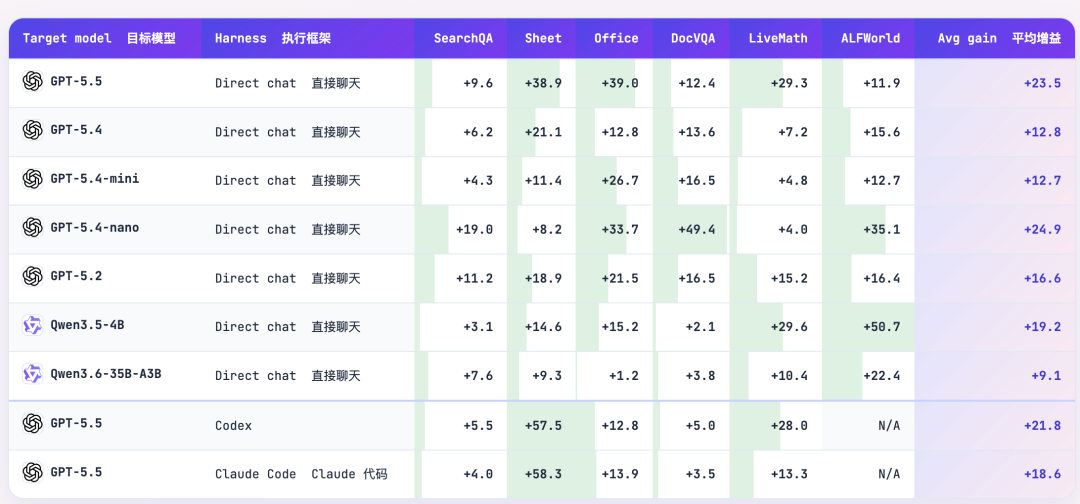
几个亮点数据:
| 模型 + 环境 | 基准 | 提升幅度 |
|---|---|---|
| GPT-5.5 直接对话 | SpreadsheetBench | +38.9 |
| GPT-5.5 直接对话 | OfficeQA | +39.0 |
| GPT-5.4-nano(最小模型) | DocVQA | +49.4 |
| GPT-5.5 + Codex | SpreadsheetBench | +57.5 |
| GPT-5.5 + Claude Code | SpreadsheetBench | +58.3 |
小模型的提升幅度反而更大——一份好的操作手册,对新手的帮助远大于对专家。
SkillOpt训练出的技能文档表现出很强的迁移能力:
部署极简:最终只需要一个 best_skill.md 文件,不需要优化器模型、不需要记忆模块、不需要任何额外的推理开销。
SkillOpt 的使用流程可以概括为以下几步:
best_skill.md,直接部署到你的Agent中详细使用方法请参考 GitHub 仓库中的文档和示例。
SkillOpt 告诉我们一个关键洞察:Agent的一切都是可以自我学习的,包括指导它行为的技能文档本身。

百度秒哒 Miaoda App Builder 上架 ClawHub,支持一键生成带支付功能的网页、小程序,自动修复 Bug,真正实现从对话到产品的闭环
阿里ATH事业群发布悟空WuKong,全球首个企业智能体AI原生工作平台,支持CLI化操作、RealDoc文件系统、十大行业OPT技能套件,解决OpenClaw企业落地难题

智谱GLM-5-Turbo龙虾专用模型实测,6个开源Skill全解析:听歌、海报生成、信息图制作、飞书自动化等,工具调用稳定,成本远低于Claude Opus