用 Doubao Seed 2.0 Lite 全模态模型配合 Agent,实现视频自动转图文博客的四步工作流,解决传统 ASR+LLM 流水线丢失画面信息的问题。

用 Doubao Seed 2.0 Lite 全模态模型配合 Agent,实现视频自动转图文博客的四步工作流,解决传统 ASR+LLM 流水线丢失画面信息的问题。
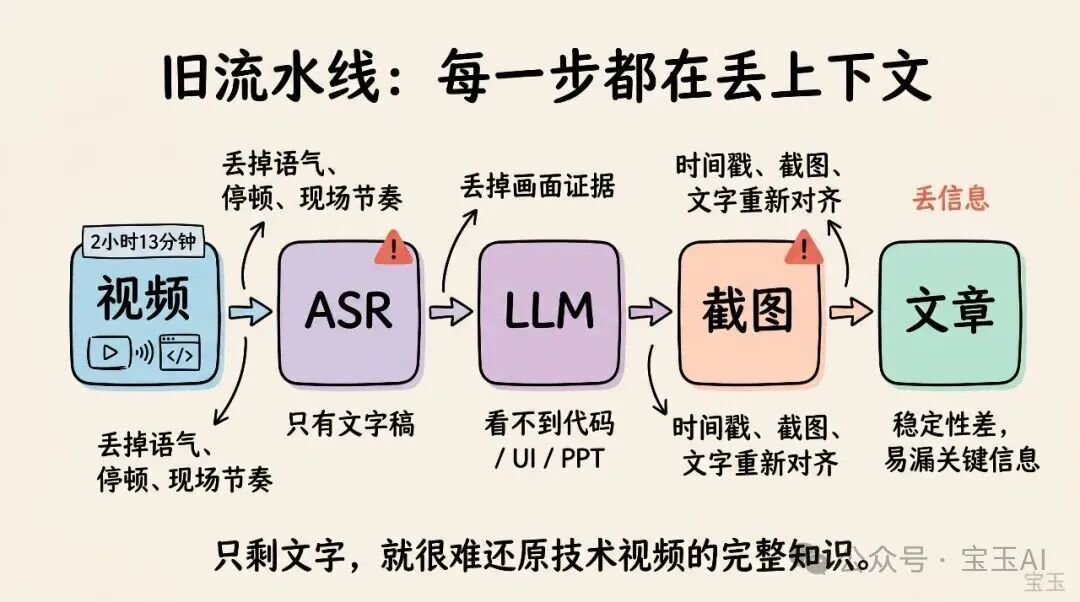
两年前,Andrej Karpathy 想把自己 2 小时 13 分钟的 tokenizer 教学视频自动转换成一篇博客。当时的方案(Whisper 转写 + LLM 改写 + 手动配图)效果不稳定,因为每一步都在丢信息。现在,借助全模态理解模型 Doubao-Seed-2.0-lite 和 Agent 工作流,这件事终于可以工程化地做完了。
这篇文章会带你完整走一遍"视频转图文博客"的四步实操流程。
传统的 ASR + LLM 流水线有一个根本缺陷:转录这一步会丢掉大量信息。
技术视频里的关键信息很多不在语音里,而在画面里:slide 上的架构图、终端里跑出的命令、IDE 里被修改的代码行、GitHub PR 的状态变化。
全模态模型的价值是把"音频""画面""屏幕文字""上下文文本"放到同一个理解空间里,同时回答:讲者说了什么?画面出现了什么?两者合在一起表达的技术含义是什么?
doubao-multimodal(https://github.com/JimLiu/doubao-multimodal-skill)doubao-multimodal 是一个 Bun + TypeScript 编写的 CLI 工具,封装了 Doubao-Seed 的多模态 chat completion endpoint。它接收本地文件或远程 URL,自动处理下载、视频切片、并发调用、结果合并等工程细节。
| Task | 用途 | 是否保留画面 |
|---|---|---|
asr | 纯语音转写 | 否 |
asr-timestamp | 每个字符带时间戳 | 否 |
multispeaker-asr | 多说话人转写 | 否 |
diarize | 说话人 + 时间段日志 | 否 |
caption | 音视频整体描述报告 | 是 |
video-timeline | 输出视频事件时间轴 JSON | 是 |
keyframe-extract | 为技术博客挑配图关键帧 | 是 |
understand | 自定义 prompt 的通用音视频理解 | 是 |
这些 task 是原子化的,可以自由组合。不只是博客写作,换一套 prompt 和输出格式,同一个 Skill 就可以用在转写报告、竞品分析、课堂记录等场景。
模型单次输入有时长和大小限制。Skill 会先检查视频:如果超过 20 分钟或 50 MB,就用 ffmpeg 自动切片;如果分辨率高于 720p,就下采样到 720p。切片后并发调用模型,再按时间顺序合并结果。
关键点:切片不是转写。每个切片仍然保留视频、画面和音频信息,模型仍然可以看到 slide、代码、UI 和听到讲者声音。
# Skill 自动执行的切片逻辑(无需手动操作)
ffmpeg -i input.mp4 -c copy -map 0 -segment_time 600 -f segment output%03d.mp4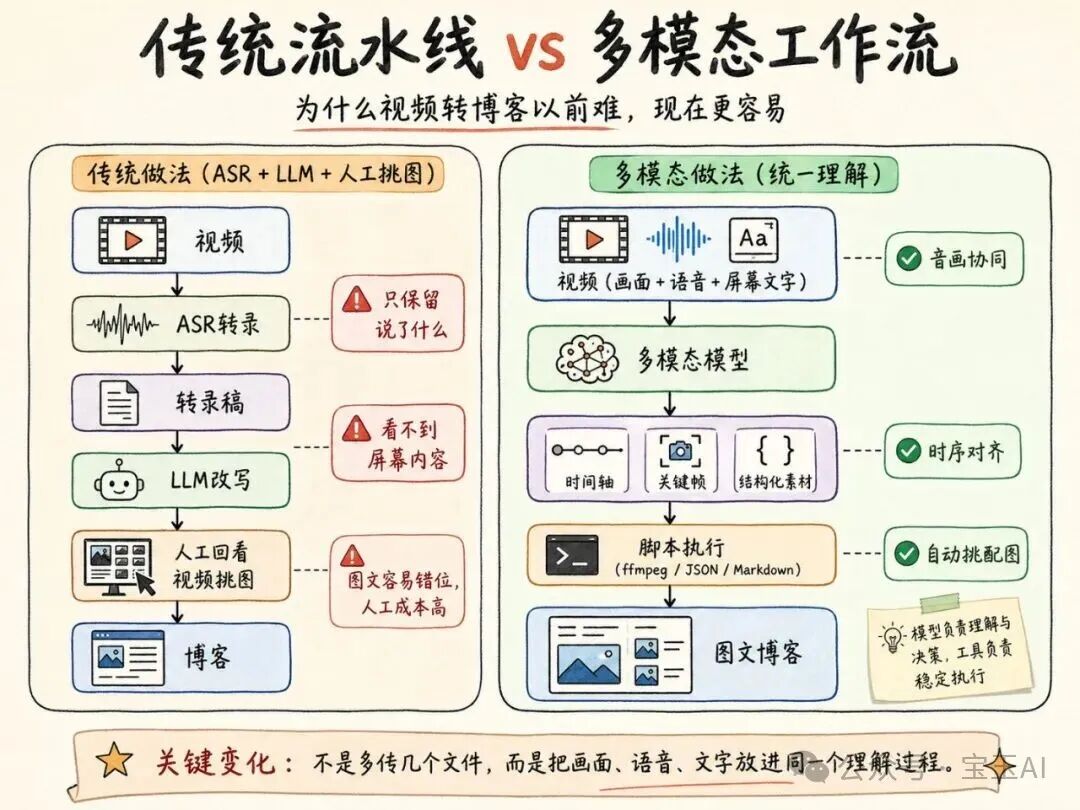
长视频不建议让模型一次输出完整文章。更稳的做法是先输出结构化素材,再基于素材写作。
给 Agent 的提示词:
请基于这段技术演讲视频,输出一份用于撰写中文技术博客的结构化素材。
请同时利用画面、语音和屏幕文字,不要只总结语音。
请至少包含:
- 视频主题和一句话摘要
- 按时间顺序拆分的章节
- 每一章的讲解重点
- 画面中出现的关键证据(代码、架构图、命令、UI 状态)
- 需要原样保留的英文术语、命令、文件名、API 名称
- 不确定或需要人工复核的点这一步让模型先当"研究助理"而不是"作者",把事实边界整理清楚。
提示:拿到结构化素材后,Agent 再进入写作阶段,把素材改写成中文博客初稿。这样写出来的文章比一步到位更稳定,也更容易检查。
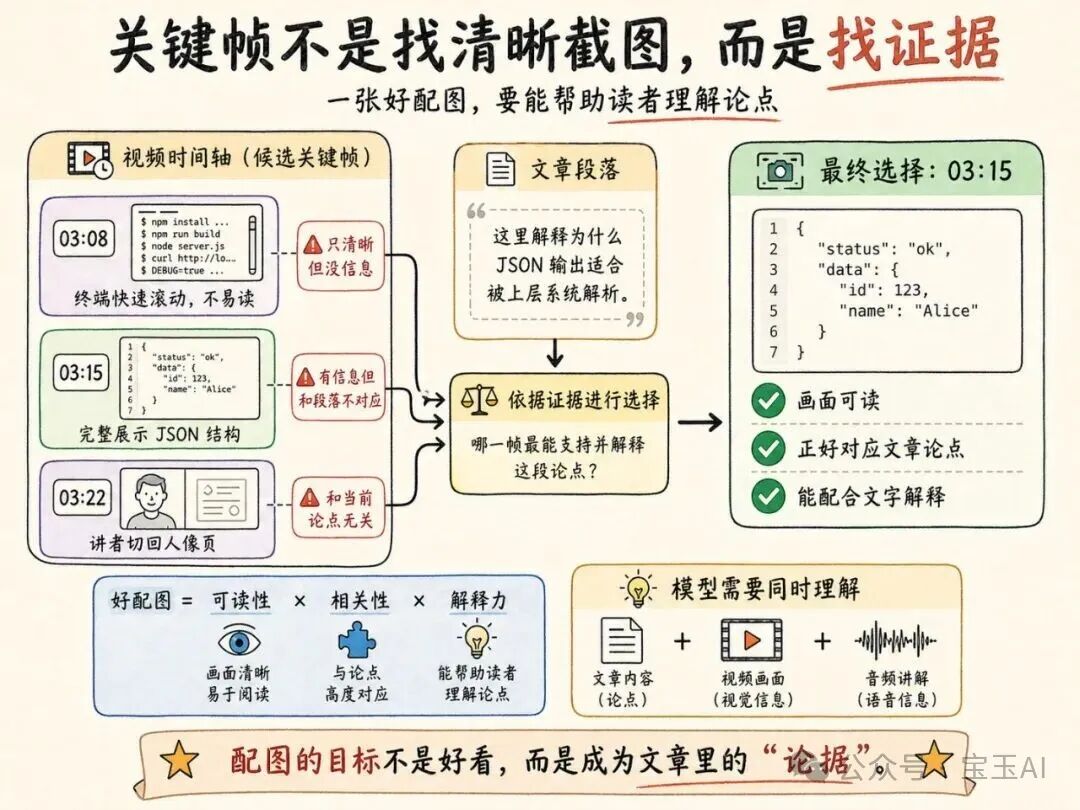
文章初稿出来后,让 Agent 把"文章内容"和"原视频"一起交给多模态模型,让它为博客挑选配图。
输出的结构化 JSON:
{
"keyframes": [
{
"timestamp": "03:15",
"timestamp_sec": 195.0,
"description": "VS Code 中出现完整命令行输出,展示 JSON 结构",
"suggested_caption": "图:结构化输出示例",
"reason": "对应文章中关于 JSON 可被上层系统解析的论点"
}
]
}最重要的字段是 reason。模型必须同时回答三件事:
这正是传统 ASR + LLM 流水线做不到的地方。
拿到关键帧 JSON 后,用确定性工具(而非模型)完成截图和插入:
mkdir -p imgs
i=0
jq -r '
(.segments[0].text | fromjson | .keyframes[]) |
[.timestamp_sec, .suggested_caption] | @tsv
' out/keyframe-extract.json |
while IFS=$'\t' read -r ts caption; do
i=$((i + 1))
file=$(printf "%02d.jpg" "$i")
ffmpeg -hide_banner -loglevel error \
-ss "$ts" -i talk.mp4 \
-frames:v 1 -q:v 2 "imgs/$file"
printf "%s[%s](imgs/%s)\n\n" "!" "$caption" "$file" >> frames.md
done注意:如果视频被切成了多段,模型返回的
timestamp_sec可能是分段内的局部时间戳。Skill 在合并结果时需要把segment.start_sec加回去,统一转换成原视频的全局时间戳。
使用一条简短的 Agent 指令即可跑通整个流程:
/doubao-multimodal 帮我基于 <~/downloads/xxx.mp4> 这个视频写一篇中文技术博客,
内容翔实,要图文并茂,保存到 out 下,新建一个目录,包括 markdown 和 imgs。最终生成的文章包含:结构化的正文内容、自动挑选的视频关键帧截图、对应的时间戳引用。
timestamp_sec 前后多取几张候选帧做二次筛选。这套模式不局限于视频转博客,还可以迁移到:

小米开源全屋智能 AI 方案 Xiaomi Miloco 2.0,多模态感知、主动智能、家庭记忆,把 Agent 带进智能家居生态。

Agnes AI 无限期免费开放文本、图片、视频全模态模型API,本周升级1M超长上下文和4K超高清文生图能力。

AI 不是不会用,是你不会拆。从目标到动作到判断,一篇讲透如何把脑中经验变成 AI 能执行的结构化 Skill。