Andrej Karpathy
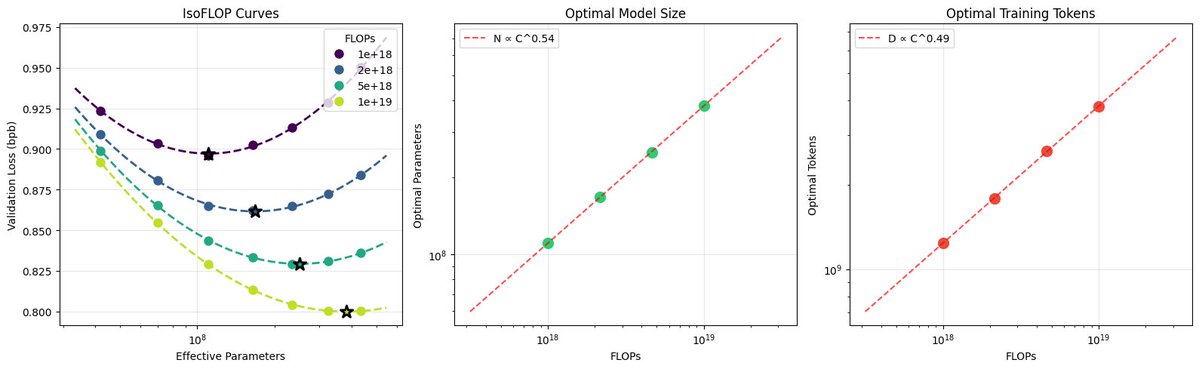
nanochat 现在可以用远低于 100 美元(约 73 美元,在单台 8xH100 节点上耗时 3 小时)的成本训练出 GPT-2 级别的 LLM。 GPT-2 是我最喜欢的 LLM,因为它是 LLM 技术栈首次以公认的现代形式呈现。因此,利用过去 7 年的进步,以更低的成本训练出一个具备 GPT-2 能力的模型,已经成了我的一种奇特且持久的执念。特别是我怀疑,在今天应该可以用远低于 100 美元的成本训练出一个。 最初在 2019 年,OpenAI 在 32 个 TPU v3 芯片上训练 GPT-2 耗时 168 小时(7 天),当时的单价是 8 美元/小时/TPUv3,总成本约为 4.3 万美元。它达到了 0.256525 的 CORE 评分,这是 DCLM 论文中引入的一项综合指标,涵盖了 ARC/MMLU 等 22 项评估。 随着最近合并到 nanochat 的几项改进(许多源自 modded-nanogpt 仓库),我现在可以在单台 8xH100 节点上用 3.04 小时(约 73 美元)达到更高的 CORE 评分。这在 7 年内实现了 600 倍的成本缩减,也就是说,训练 GPT-2 的成本每年大约下降 2.5 倍。我认为这可能还是低估了,因为我仍然在相对定期地发现更多改进,而且我还有一堆新想法等着去尝试。 关于优化细节的长文和复现指南请见:https://t.co/vhnK0d3L7B 受 modded-nanogpt 启发,我还创建了一个“GPT-2 训练时长”排行榜,这个首个“Jan29”模型以 3.04 小时位列第一。继续迭代会很有趣,欢迎大家帮忙!我希望 nanochat 能成长为一个非常优雅、简洁且经过调优的实验性 LLM 框架,用于原型设计、寻找乐趣,当然还有学习。 在那些开箱即用且能立即产生收益的改进中,最显著的是:1) Flash Attention 3 算子(速度更快,并允许通过 window_size 参数实现交替注意力模式);Muon 优化器(我曾尝试花一天时间删掉它只用 AdamW,但没成功);由可学习标量控制的残差路径和跳跃连接;以及值嵌入(value embeddings)。还有许多其他的小改进累积在一起。 配图:与推文半相关的“视觉享受”——推导当前 nanochat 模型系列的缩放法则,既漂亮又治愈!