清华大学开源的自适应图像生成框架,通过强化学习为每个样本量身定制最优策略,在四大主流生成范式上实现最高54%性能提升

清华大学开源的自适应图像生成框架,通过强化学习为每个样本量身定制最优策略,在四大主流生成范式上实现最高54%性能提升
你可能没意识到一个问题:当前的 AI 图像生成模型(Stable Diffusion、Midjourney 等)在生成每张图片时,都在用完全相同的策略。生成一张简单的风景图和一张复杂的人物肖像,模型执行的是同样的步骤、同样的参数配置。
这就像让厨师用完全相同的火候和时间烹饪牛排和蔬菜——显然不够合理。
AdaGen 是清华大学开源的通用框架,它通过强化学习训练一个轻量级"策略网络",让图像生成模型学会观察当前状态,为每个样本自动选择最优参数。简单说:从"一刀切"升级为"量身定制"。
当前主流的图像生成模型(扩散模型、自回归模型、掩码生成模型、流模型)都需要配置大量超参数:噪声水平、采样温度、引导尺度等。现有方法存在两个致命缺陷:
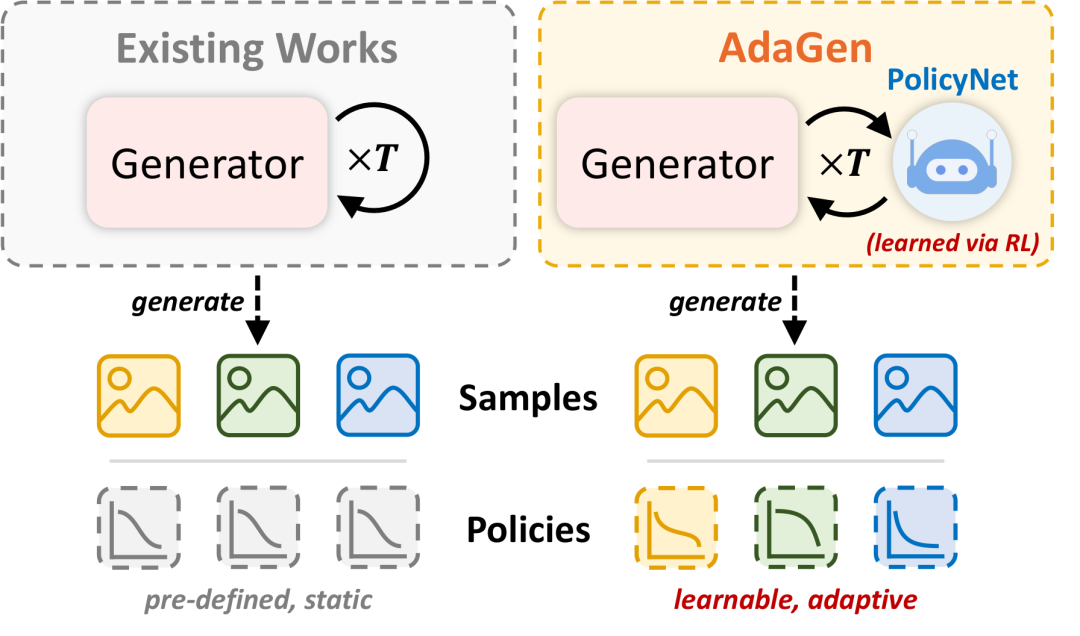
左侧是传统方法:所有样本共享预定义的静态策略;右侧是 AdaGen:通过策略网络为每个样本动态生成定制化策略
AdaGen 将不同的生成模型统一建模为马尔可夫决策过程(MDP),涵盖扩散模型(DiT)、自回归模型(VAR)、掩码生成模型(MaskGIT)、流模型(SiT)。这意味着你不需要为每种模型重新设计策略。
MDP 的核心组件:
关键是:预训练的生成模型始终保持冻结,AdaGen 只训练一个极轻量的策略网络(仅增加 0.07%-0.40% 计算量)。
训练策略网络最大的挑战是:如何设计有效的奖励信号?论文测试了三种方案:

(a)用 FID 作奖励:指标虽低但图像质量差;(b)用预训练奖励模型:保真度好但多样性不足;(c)AdaGen 的对抗奖励:保真度与多样性兼顾
最终方案:引入一个判别器作为奖励模型,与策略网络进行对抗训练。策略网络试图最大化奖励,判别器不断提高区分真假图像的标准,类似 GAN 的博弈过程。

训练算法简洁优雅:策略网络控制生成 → 奖励模型评估 → 两者交替进化
当生成步数增加时(如从 8 步增加到 32 步),策略网络需要探索的参数空间急剧扩大,训练容易崩溃。
问题根源:强化学习探索时对每步独立添加随机噪声,导致策略序列剧烈抖动(像心电图的异常波形)。
解决方案:对策略输出施加指数移动平均(EMA)滤波,让参数变化更平滑。这个操作满足低通滤波(抑制高频波动)和因果性(不依赖未来信息)。
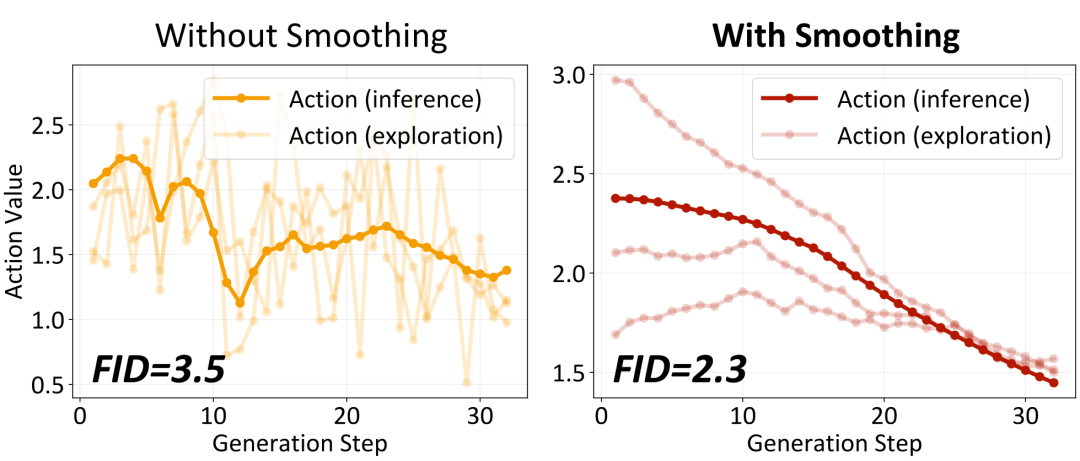
左侧未平滑时策略剧烈抖动(FID=3.5);右侧平滑后策略合理稳定(FID=2.3)
在 ImageNet 256×256 数据集上,AdaGen 在四大生成范式、六个模型上进行了验证:
性能提升:
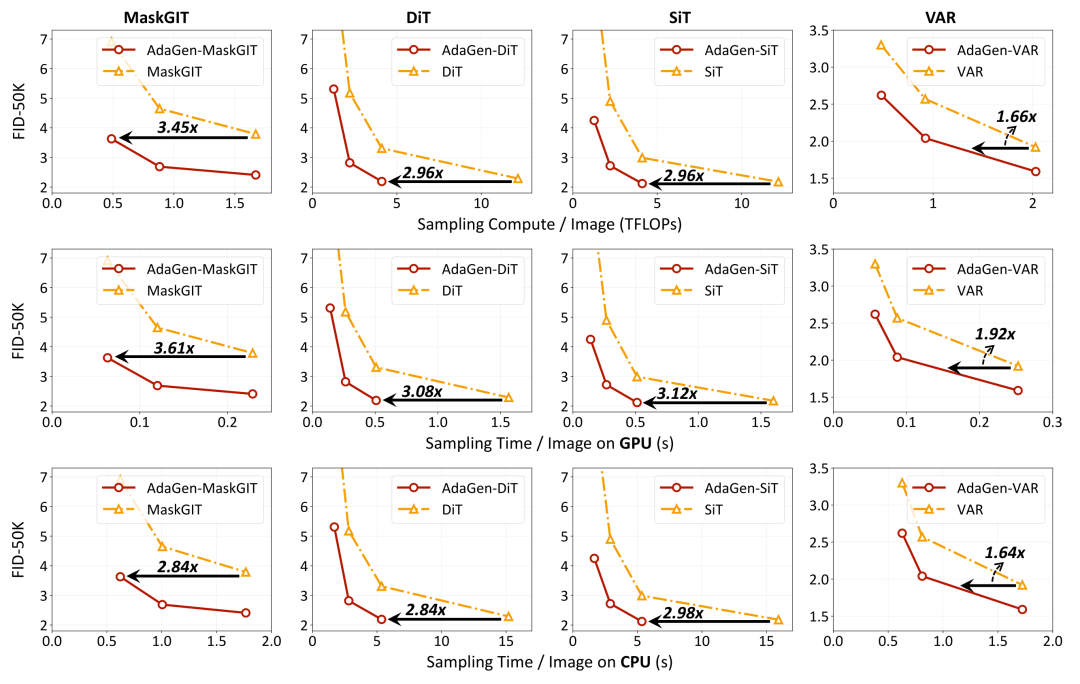
无论是理论计算量(TFLOPs)还是实际 GPU/CPU 推理时延,AdaGen 均能推进质量-效率前沿
额外开销:策略网络仅为生成器增加 0.07% - 0.40% 的计算量,几乎可以忽略不计。
适合你,如果你:
不适合你,如果你:
论文地址:https://arxiv.org/abs/2603.06993
GitHub 仓库:https://github.com/LeapLabTHU/AdaGen
技术栈:
核心要点:
AdaGen 将生成策略的设计从"手工艺术"转变为"数据驱动的优化问题"。它的核心洞察是:好的调度策略和模型架构本身同样重要。
对于研究者和开发者,这意味着你不需要重新训练庞大的生成模型,只需在现有模型基础上加一个"智能调度器",就能获得显著的性能提升。这种"即插即用"的设计理念,可能会成为未来优化生成模型的标准范式。

Anthropic 发布 Claude Sonnet 5,默认开启自适应思考、引入新分词器,定价维持 $3/$15,8月31日前享 $2/$10 限时价。

输入一句话或画张草图,CADDesigner 自动生成 3D 模型。浙大开源的 LLM 驱动 CAD 智能体,附使用流程与避坑要点。
:国内首个纯中文 AI 音乐模型实操解析")
专为华语优化,单卡 10 秒生成一首中文歌,已接入抖音、剪映等七大平台。歌歌AI 模型能力、接入方式与创作者变现路径。