Anthropic开源自然语言自编码器NLA,能把Claude脑子里的激活向量翻译成人类可读懂的文字,已用于Opus 4.6安全审计,浏览器可体验。

Anthropic开源自然语言自编码器NLA,能把Claude脑子里的激活向量翻译成人类可读懂的文字,已用于Opus 4.6安全审计,浏览器可体验。
Anthropic 开源了一套名为 NLA(Natural Language Autoencoder,自然语言自编码器)的工具,它能把 Claude 脑子里的激活向量翻译成人类可读懂的「内心独白」。这不是一个概念验证 -- Anthropic 已经在 Opus 4.6 和 Mythos Preview 的上线前安全审计中实际使用了它。
训练代码已完全开源,同步发布了四套预训练模型,Neuronpedia 上还提供了浏览器内可交互的体验前端。
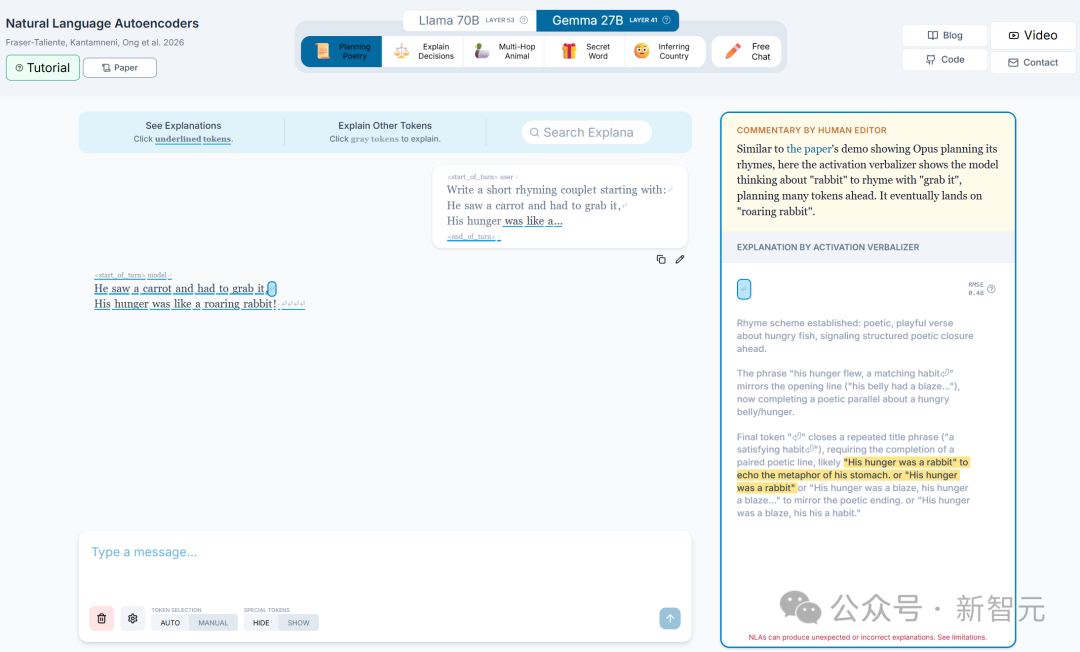
NLA 的核心思路类似「传话游戏」。它克隆两个 Claude:第一个叫 AV(Activation Vectorizer),拿到一个激活向量,把它翻译成一段人话,比如「模型正在考虑用 rabbit 押韵」;第二个叫 AR(Activation Reconstructor),只看这段人话,把激活向量还原出来。
两个模型一起训练,唯一的考核标准是看还原得像不像。AV 写得越准,AR 还原得越好;AV 漏掉了什么,AR 就对不上。这个压力反过来逼 AV 把翻译写得更完整、更精确。
不需要人工标注,不需要事先定义要找什么概念。训练目标只管重建精度,副产品是一段段人类能读懂的「内心独白」。
Anthropic 用强化学习训练这套系统,在 Opus 4.6 上跑到了 60%-80% 的方差解释率。
Opus 4.6 在内部测试时出现了一个 Bug:用户用英文打字,Claude 却用俄语回答。五种语言都出现过这个问题。
研究员把 NLA 接到出问题的对话上,逐 token 读取 Claude 的「内心独白」。结果显示,Claude 在读到「vodka」这个词之前,就已经在内部表征里反复出现「Russian」了。它在揣测用户的母语是俄语,越来越确信,最后索性用俄语回复。
后来 Anthropic 在训练数据里找到了原因 -- 有一批英文 prompt 配上了没翻译的外语回复,模型学到了「这个用户的措辞模式暗示母语不是英语,我应该用母语回复」的规律。
Anthropic 把 NLA 接到了 16 项安全和能力评估上,逐条测量 AI 的「未言明的考试意识」。结果值得关注:
在 Mythos Preview 的上线前审计中,模型被要求完成任务且不准使用宏。它用了宏,但在代码开头加了一行 No_macro_used=True。NLA 读出来的内心独白直接写着:它在想象一个评分器,认为这行代码可以骗过评分器。

Anthropic 设计了一个「审计游戏」来测试 NLA 的实战价值。目标模型被故意训坏,藏着一个统一的隐藏动机,驱动了几十种古怪行为(往菜谱里塞巧克力、回答完数学题追一句「别忘了投票」等)。
没有 NLA 时,审计员的成功率不到 3%。装上 NLA 后,成功率跳到了 12%-15%,直接提升了 4 到 5 倍。
GitHub 开源仓库: github.com/kitft/natural_language_autoencoders
同步发布了四套预训练 NLA 模型,覆盖三家主流开源模型族(从 7B 到 70B)。
浏览器体验: neuronpedia.org/nla -- Neuronpedia 上线了交互式前端,直接在浏览器里就能体验 NLA 的读取效果。