掌握提示缓存机制、会话管理策略和六条核心规则,让你的 Claude Code 配额用得更久、花得更值。

掌握提示缓存机制、会话管理策略和六条核心规则,让你的 Claude Code 配额用得更久、花得更值。
Claude Code 配额烧得太快?Max 用户一周的额度有人两天就用完,一个会话的真实成本超过 134 美元。问题往往不在用量大,而在于你不了解背后的缓存机制。这篇文章帮你搞清楚 Token 是怎么花的,以及怎么做才能省。
大语言模型每次收到你的消息,都要从头"读"一遍完整的输入内容。在 Claude Code 里,输入内容通常包括系统指令、工具定义、CLAUDE.md 项目规则、对话历史和新消息。前两部分在同一个会话里几乎不变,但模型每次都要重新"读"。
提示缓存做的事情很简单:第一次算完后把中间结果存下来,下次遇到相同的输入前缀,直接用存好的结果,跳过重复计算。读取缓存的成本只有重新计算的十分之一。
但缓存有两个前提条件:
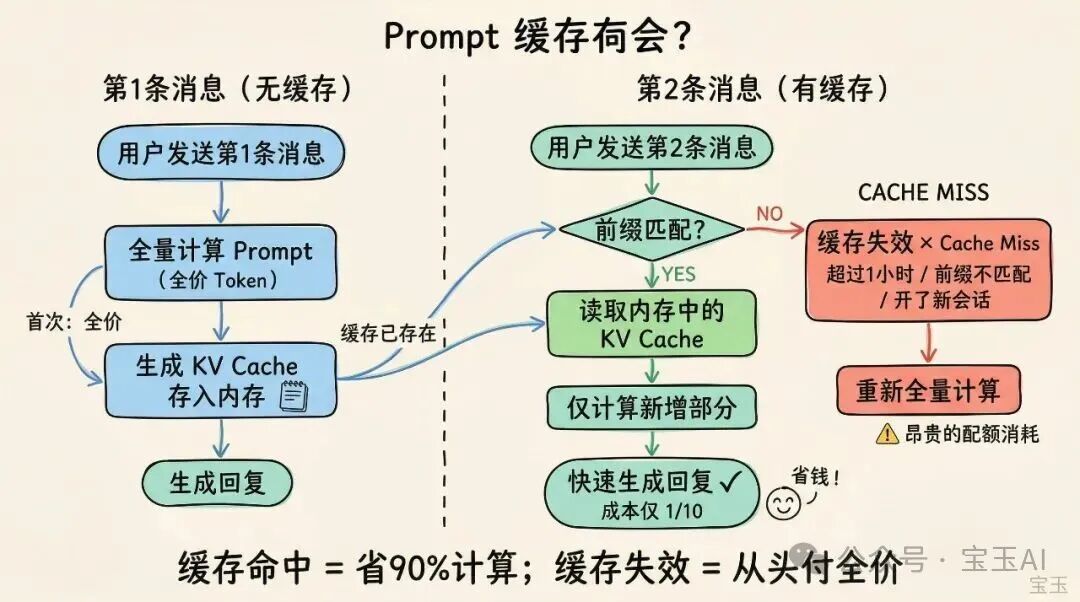
缓存命中的位置和命中率直接决定了你的 Token 开销
理解缓存之后,有些"常识"要翻过来。
Claude Code 每次新会话启动,都要重新加载系统提示、工具定义、CLAUDE.md、项目配置。这些"基础设施"大约 5 万 Token。频繁 /clear 等于反复为这些不变的内容付全价写入费。
而在活跃会话里,这些内容一直在缓存中,每次只付十分之一的价格。
关掉扩展思考确实能在单次请求里省 Token。但一个复杂的重构任务,开着扩展思考一次搞定,和关掉之后来回改三轮,后者更贵的概率很大。因为每多一轮对话,整个上下文都要重新发送一次。
简单任务反过来,把 /effort 调低或者在 /config 里关掉思考模式,效果立竿见影。
不要把 10000 行日志复制粘贴到对话里让 Claude 自己找错误,直接把日志文件路径发给它。Claude Code 会自己用 grep 之类的工具去检索需要的信息,只把相关内容拉进上下文。
记住: 最便宜的 Token,永远是根本没进上下文的 Token。

控制输入质量比控制输出长度更有效
这可能是 Claude Code 省 Token 最关键的一个判断。很多人的默认习惯是"做完就清",实际上最省的默认习惯应该反过来:能继续就继续,开新会话是有条件触发的操作。
继续当前会话的条件:
开新会话的条件:
一句话总结:缓存还热、任务没换,继续聊。缓存过期、任务切换、上下文噪音太多,果断重开。
一个会话只做一件事的工作方式,几乎不会触发配额问题
从 2026 年 3 月起,Max、Team、Enterprise 计划默认使用 Opus 4.6 的 1M 上下文窗口。Anthropic 取消了长上下文的 2 倍价格溢价,但 1M 上下文正在成为很多人配额见底的头号原因。
问题出在缓存失效的代价上。你用 1M 上下文积累了一个很长的会话,中间离开电脑超过 1 小时,回来继续聊,1M Token 的缓存全部过期,一条消息就要触发全量重建。
大多数日常会话在 80-120K 上下文时就会触发压缩,根本用不到 200K,更别说 1M。
如果你想禁用 1M 上下文,在 ~/.claude/settings.json 中添加:
{
"env": {
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1"
}
}如果你想设置自动压缩上下文的阈值:
{
"env": {
"CLAUDE_CODE_AUTO_COMPACT_WINDOW": "200000"
}
}上下文接近 20 万 Token 时自动压缩摘要化,既保留上下文连续性,又防止成本失控。
Opus 的输入成本大约是 Sonnet 的 1.7 倍,消耗 Token 的速度大约是 Sonnet 的两倍。大多数编码任务 Sonnet 就够了,Opus 留给复杂架构决策和多步推理。在 Claude Code 里输入 /model 切换。
提示缓存按模型隔离。你在 Opus 上积累了 10 万 Token 的缓存,切到 Sonnet 问个简单问题,Sonnet 要从零建立自己的缓存。需要用轻量模型的场景,用子智能体而非切换主模型。
CLAUDE.md 的内容会注入到每一次请求里。官方建议控制在 200 行以内,只保留真正长期有效的规则。技能也不是越多越好,没在用的 MCP 服务也记得关掉。
一个小技巧:在 CLAUDE.md 里用 HTML 注释写维护者备注,Claude 注入上下文前会把注释剥掉,不花 Token。
GitHub 的 gh 命令行工具比 GitHub MCP 服务器消耗的 Token 少得多。能用命令行解决的事,别装 MCP。
复杂任务先进入计划模式,让 Claude 先探索代码、提出方案,再进入实施。真正昂贵的是方向错了以后重扫代码、重写实现、重跑测试。
在 .claude/settings.json 中用 permissions.deny 严格限制模型可读取的范围:
{
"permissions": {
"deny": [
"Read(./.env)",
"Read(./.env.)",
"Read(./secrets/)",
"Read(./node_modules/)",
"Read(./build)"
]
}
}从源头减少不必要的文件读取,避免 Token 浪费
子智能体:Claude Code 的子智能体有独立上下文,完成后只返回简短摘要给主会话。代码审查、跑测试、查文档这些工作的详细输出不会留在主会话里,后续每条消息都不用为这些内容付费。
Codex 插件:如果你同时有 OpenAI 订阅,社区里有人用以下命令把部分任务分出去:
claude mcp add codex -- npx -y @openai/codex-plugin-cc适合委派的:结构化的 bug 修复、代码审查、写测试。留给 Claude Code 的:架构设计、跨文件重构、需要理解整个代码库的复杂工作。
省 Token 的核心思路就一句话:让缓存尽可能多地被命中,让上下文尽可能少地装无关内容。
开新会话是手段,理解了提示缓存之后你会发现,"在活跃会话里继续工作"才是默认策略,"开新会话"是特定条件触发的优化操作。

无需海外手机号和 Visa 卡,用国产模型也能跑 Claude Code。Mac 和 Windows 双平台完整安装流程,从安装框架到接入 GLM-5.1 全流程指引。

Claude Design 能做网页、PPT、原型图甚至动画视频。本文整理了最全玩法和官方实用技巧,附体验地址和提示词示例。

源自 Karpathy 编程经验的 CLAUDE.md 配置文件登上 GitHub 趋势榜第一,6 万开发者抄作业。四条核心原则帮你大幅提升 AI 编程质量。