Claude Opus 4.6 上下文从 200K 升级到 1M,实际可用空间从 118K 提升至 923K,长文本检索领先,API 取消长度溢价

Claude Opus 4.6 上下文从 200K 升级到 1M,实际可用空间从 118K 提升至 923K,长文本检索领先,API 取消长度溢价
Anthropic 刚刚为 Claude Opus 4.6 开放了 100 万 token 的上下文窗口。但这次更新的真实价值,远比"5倍提升"这个数字更夸张。
大多数人会认为从 200K 到 1M 是 5 倍提升。但实际情况是:你真正可用的项目上下文空间提升了 7-8 倍。
原因很简单:200K 上下文中有大量空间被系统提示词、记忆、skills 和预留的 compact buffer 占据。真正留给你的项目上下文只有 100K 出头。
看两组实测数据对比:
Sonnet 4.6(200K 上下文)
Opus 4.6(1M 上下文)
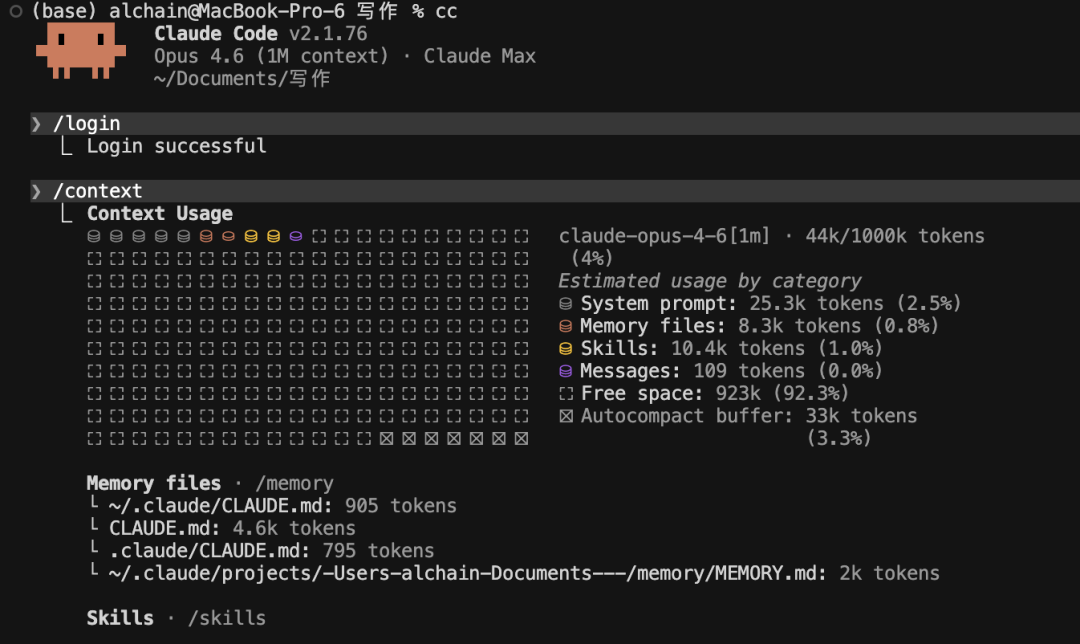
923 ÷ 118 ≈ 7.8 倍。对于 skill 配置越重的用户,这个倍数会更夸张。
上下文不是存储容量,是模型的草稿纸。
想象你在解一道复杂数学题,做到一半草稿纸被拿走了。你的智商没变,但你解不出这道题了。
模型也一样。很多时候它出错不是因为不够聪明,而是看不见关键信息:
上下文越小,这类"残缺"越多,判断越差。
Anthropic 用 MRCR v2(8-needle)测试了长上下文检索能力——在超长文本中同时找多个关键信息:
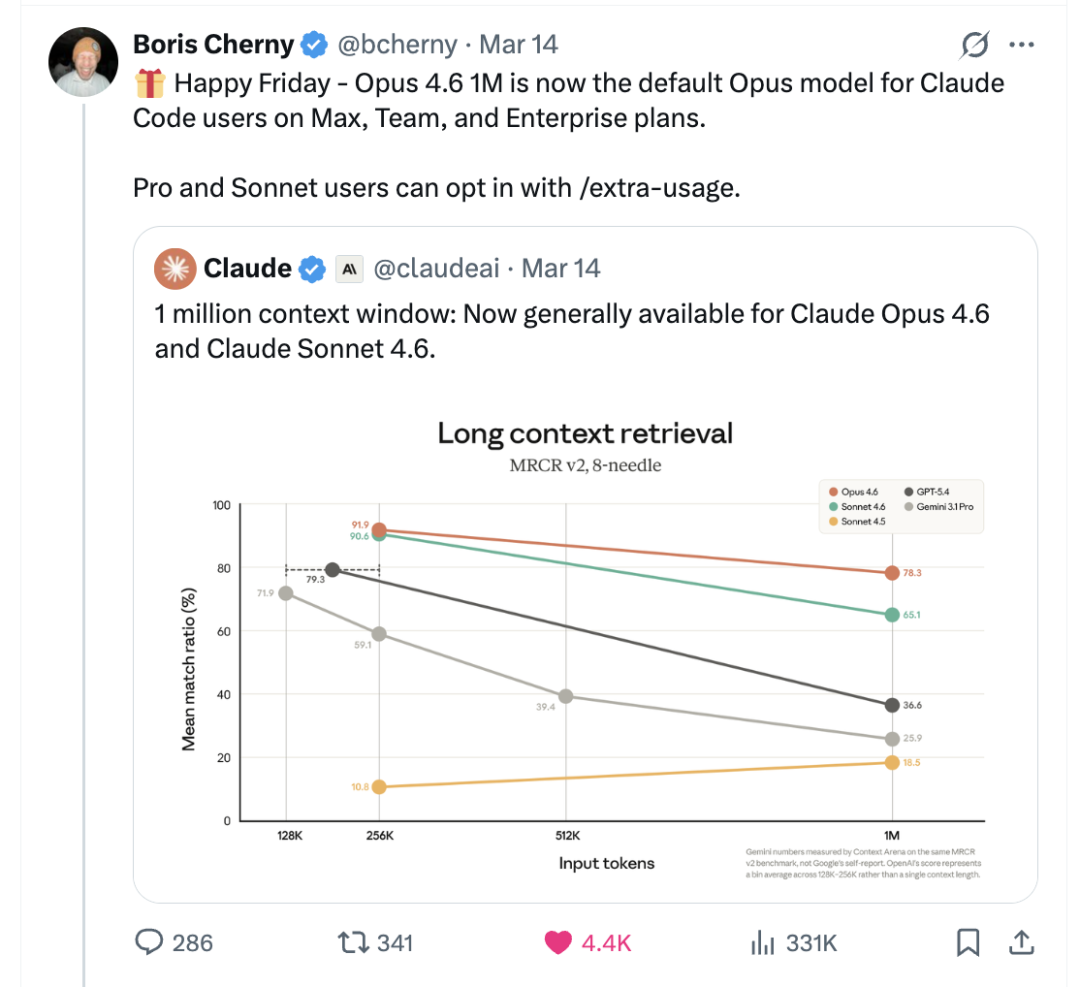
| 模型 | 256K | 1M |
|---|---|---|
| Claude Opus 4.6 | 91.9% | 78.3% |
| Claude Sonnet 4.6 | 90.6% | 65.1% |
| GPT-5.4 | 79.3% | 36.6% |
| Gemini 3.1 Pro | 59.1% | 25.9% |
上下文越长,差距越大。256K 时几个模型还挤在一起,拉到 1M 后,GPT-5.4 掉到 36.6%,Gemini 3.1 Pro 只剩 25.9%,Claude Opus 4.6 还保持在 78.3%。
以前 OpenAI 对长上下文收"长度税":超过 272K 输入收 2 倍单价,输出 1.5 倍。
现在 Anthropic 取消了这个溢价:900K token 的请求和 9K token 一个价。
长上下文终于从"高级功能"变成了模型的标配能力。
1. 图片/PDF 上限:100 → 600
以前处理一堆 PDF 要手动拆批,现在一次喂进去。写文章整理十几张截图和参考资料,直接省了好几步。
2. Adaptive Thinking 转正式版
模型自己判断什么时候需要深度思考、什么时候直接回答,不用你手动配置推理深度。
/extra-usage 手动开启根据 Claude Code PM Boris Cherny 的说法,使用 1M 上下文后,自动压缩事件减少了 15%。对长期迭代的复杂项目,这个价值至少等于模型能力提升 10%-20%。
这次更新的核心价值不在"更大",而在让你不用再做减法。
以前你得精心挑选哪些信息放进上下文,每次删减都是在赌"这段不重要"。赌错了,模型就会在某个看不见的地方犯错。
现在你可以放心把所有相关信息都喂给模型。对于需要处理大型代码库、长文档、多轮复杂对话的场景,这是质的飞跃。
适合谁?
不适合谁?

Andrej Karpathy 分享了他的 LLM Wiki 工作流,用 Markdown 文件 + Claude Code 替代复杂的 RAG 架构,构建可演化的个人知识库。

OpenAI 发布 GPT-Rosalind 生命科学模型系列,RNA 预测超越 95% 人类专家,同时开源 Life Sciences Research 插件连接 50+ 科研数据库。

从 200+ 篇文章数据中提炼的好内容标准、去 AI 味检查清单,以及从 1.0 到 3.0 的 AI 内容创作进阶路径。