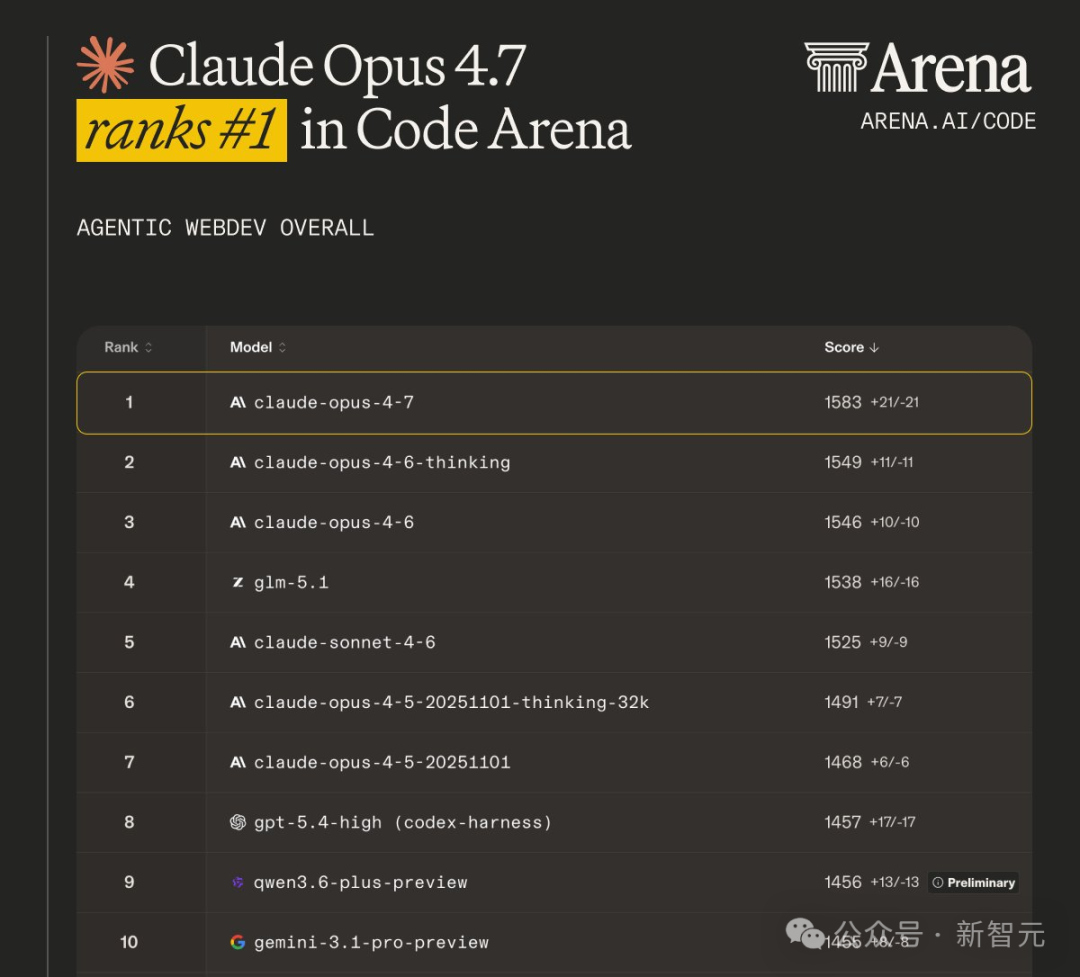
Claude Opus 4.7在综合榜和代码榜同时登顶,长任务执行、工具调用稳定性大幅提升,更适合企业级生产环境。

Claude Opus 4.7在综合榜和代码榜同时登顶,长任务执行、工具调用稳定性大幅提升,更适合企业级生产环境。
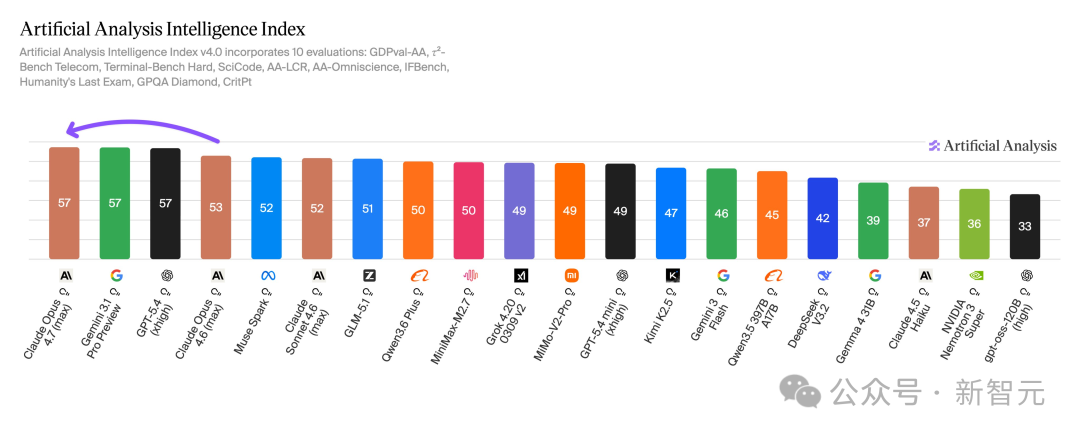
Anthropic 发布了 Claude Opus 4.7,它在两份最受关注的公开评测中同时登顶。但比排名更重要的,是它真正变强的方向:长任务执行、工具调用稳定性和工程工作流完成率。如果你在用 AI 做代码开发或多步骤自动化任务,这次升级值得认真关注。
Claude Opus 4.7 是 Anthropic 旗舰模型 Opus 系列的最新版本。它不是一个"全能型"的升级,而是针对企业级工作流做了定向优化——特别是需要模型持续执行数十个步骤、调用多个工具、在出错后自动恢复的场景。
在 Anthropic 自建的93项编码基准测试中,Opus 4.7 相比上一代 Opus 4.6 的任务解决率提升了13%。在 CursorBench(代码编辑器场景评测)上,成绩从58%提升到70%。
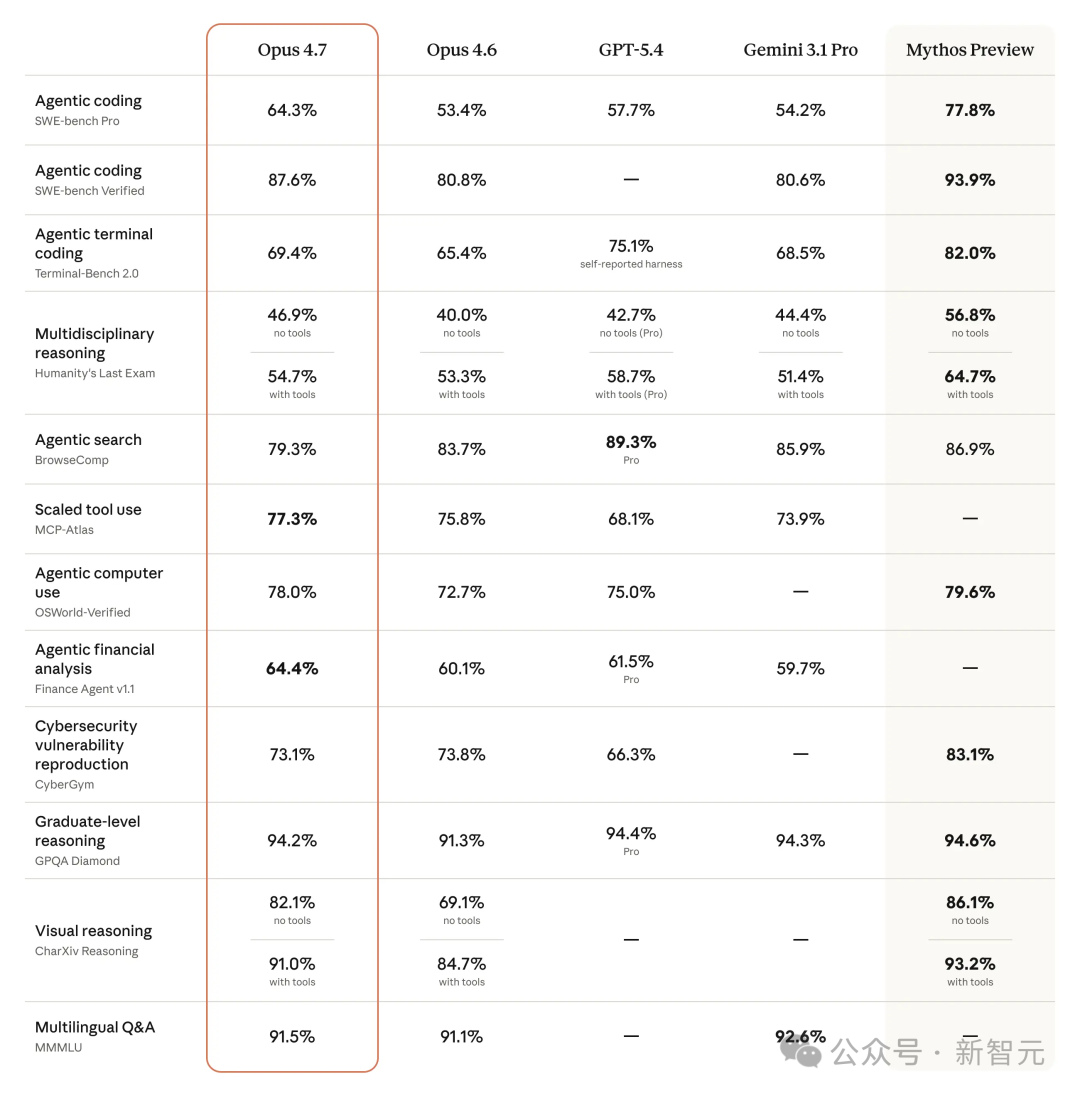
在 Notion 的多步工作流测试中,Opus 4.7 整体效果提升14%,工具调用错误下降到原来的三分之一。这意味着模型在连续执行任务时更少中断、更少需要人工介入。
人大开源Claw Agent数据+训练+评测全链条框架,13.5K可执行任务,支持沙盒并行强化学习
| 场景 | Opus 4.7 的优势 |
|---|---|
| 代码开发(Cursor等IDE) | 编码基准提升13%,CursorBench 58%->70% |
| 多步工作流自动化 | 工具调用错误降至1/3,整体提升14% |
| 代码仓库级重构 | 长链路任务稳定性显著提升 |
| 文档审阅/法律研究 | 遇到工具失败时可自动恢复执行 |
Opus 4.7 已通过 Anthropic API 和 Claude 官网开放使用。企业用户可通过 AWS Bedrock、Google Cloud Vertex AI 等平台接入。


