拆解 Claude Code、Codex CLI 等 AI 编程智能体的核心架构,涵盖代码仓库上下文、提示词缓存、工具调用、上下文瘦身、会话记忆和子智能体委派。

拆解 Claude Code、Codex CLI 等 AI 编程智能体的核心架构,涵盖代码仓库上下文、提示词缓存、工具调用、上下文瘦身、会话记忆和子智能体委派。
Claude Code 和 Codex CLI 为什么比直接在聊天框里用同款模型强那么多?答案不在模型本身,而在包裹在模型外面的那层「Coding harness」(编程运行框架)。本文拆解编程智能体的六大核心组件,帮你理解 Agent 为什么比裸模型好用,以及如何构建自己的编程智能体。
先厘清三个关键概念:
一个类比:LLM 是普通发动机,推理模型是爆改后的高马力发动机,Agent harness 则是帮你驾驭发动机的整车系统。

基础模型、推理模型与 Agent 之间的关系。Agent 在特定环境里不断循环调用模型,处理真实开发中的复杂任务。
这是最关键也最基础的组件。当你说「修一下测试代码」时,模型不能两眼一抹黑。它需要知道:
AGENTS.md、README)Coding harness 在收到指令后,会先收集这些信息,生成一份「工作区摘要」。这样模型面对每次提示时,都不是从零开始。
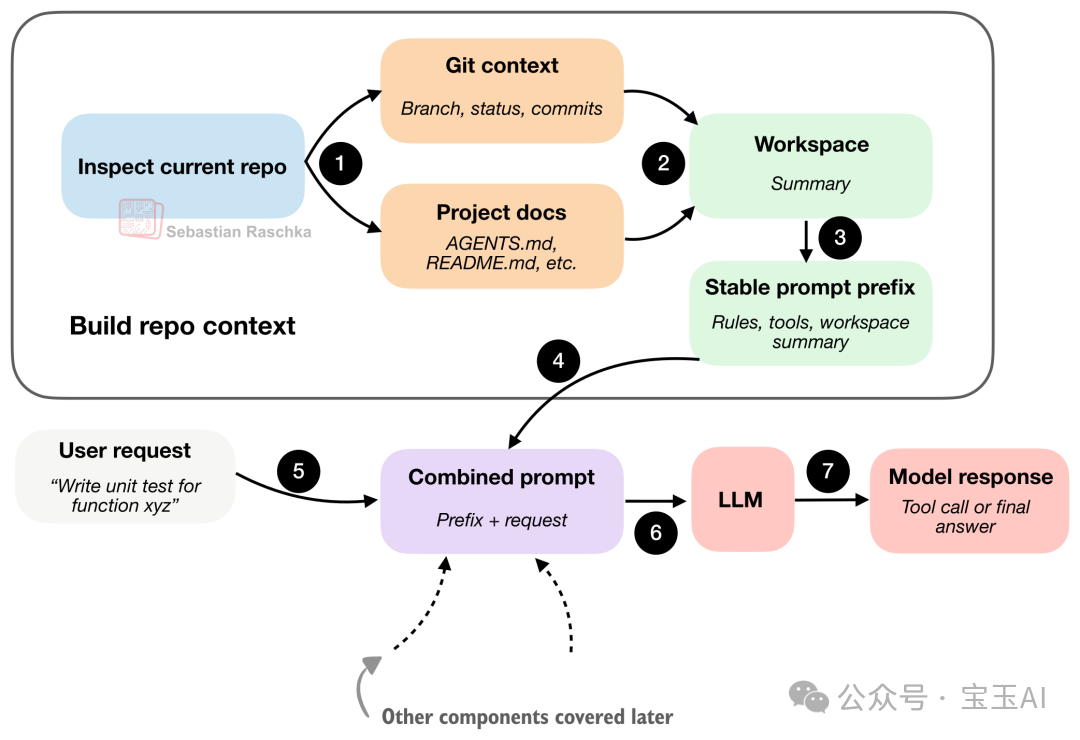
Coding harness 先生成工作区摘要,再与用户请求合并,为模型提供充分的上下文。
收集了上下文后,怎么高效地喂给模型?如果每次都把全部信息重新拼一遍,算力和成本浪费巨大。
核心策略:把提示词拆成「稳定的」和「变化的」两部分:
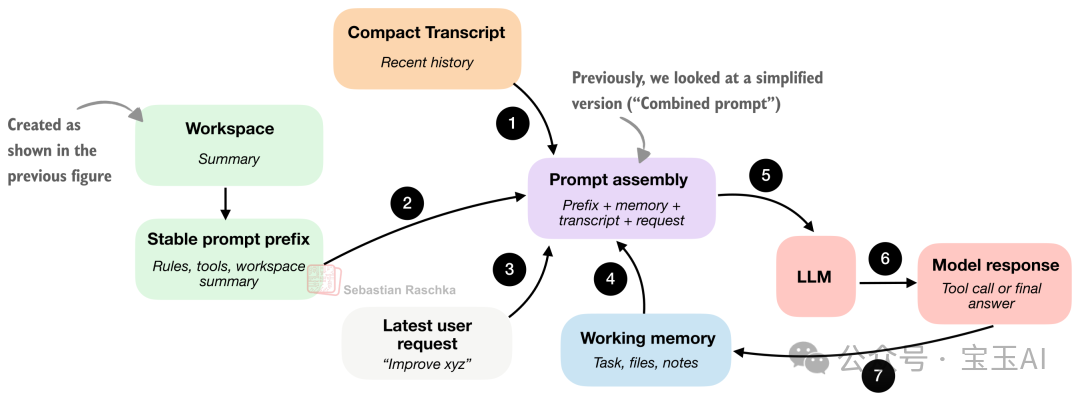
提示词分为稳定前缀和变化部分。主流 LLM API 都支持 Prompt Cache,缓存稳定前缀可以大幅降低成本。
装在 Coding harness 里的 LLM 不只是提建议,它还能实打实地执行命令。但不是随意执行 -- Harness 提供预定义的工具箱,每个工具都有明确的输入要求和边界。
完整的工具调用流程:
# Harness 的安全检查逻辑
def validate_tool(action):
if action.tool not in KNOWN_TOOLS:
return reject("未知工具")
if not action.params_valid():
return reject("参数非法")
if action.is_dangerous() and not user_approved():
return reject("需要人工批准")
if action.path_outside_repo():
return reject("路径越界")
return execute(action)编程智能体比普通聊天更容易「吃撑」上下文窗口,因为它频繁读取文件,工具输出往往又臭又长。优秀的 Harness 至少用两招应对:
核心秘诀:越近的事情保留细节越多,越久远的压缩越狠。早期读取的重复文件要做去重处理。
编程智能体把状态分为两层:
| 层级 | 存储内容 | 大小 | 用途 |
|---|---|---|---|
| 工作记忆 | 核心关键点、当前任务、重要文件 | 小 | 保持任务连贯性 |
| 完整记录 | 所有请求、工具输出、模型回答 | 大 | 支持会话恢复 |
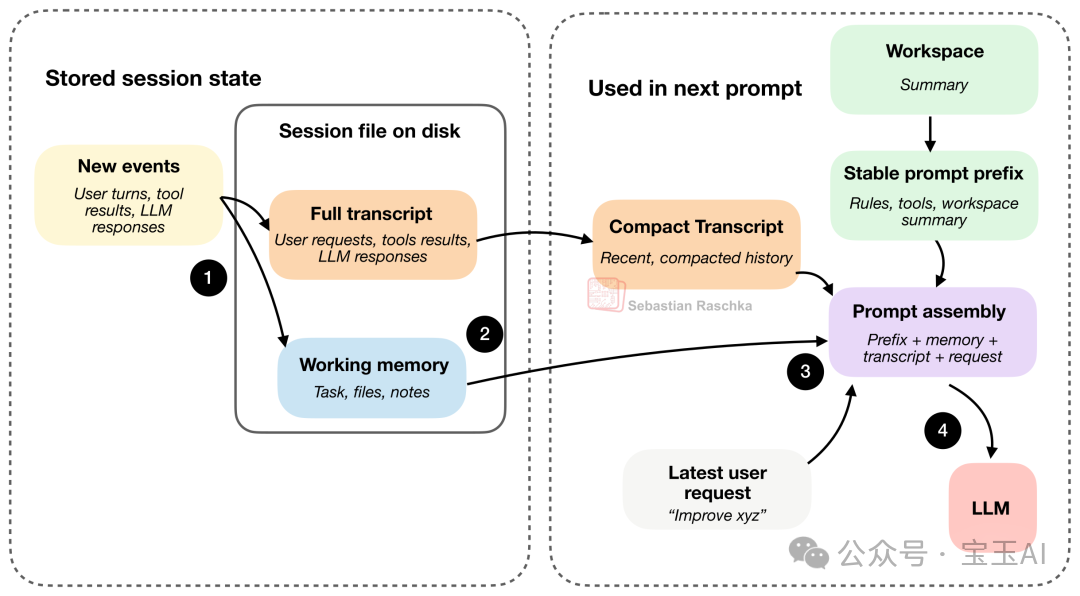
工作记忆和完整记录通常以 JSON 格式存储在硬盘上,关闭智能体后下次打开可以无缝恢复。
把某些子任务分给子智能体并行处理,可以大幅加速主线任务。但关键在于约束:
子智能体既要继承足够的上下文来干活,又必须受到严格约束,这是设计上最考验功力的地方。
Sebastian Raschka 用纯 Python 从零构建了一个 Mini Coding Agent,把上述六大组件全部实现,没有任何外部依赖。
mini_coding_agent.py,代码中用注释标注了六大组件的对应位置如果你想深入理解编程智能体的内部机制,阅读这个项目的源码是最好的起点。
![]()
Mini Coding Agent 是一个极简但功能完整的编程智能体实现。

Anthropic 推出面向科研的 AI 工作台 Claude Science,内置 60+ 技能、可复现。另有开源平替 OpenScience 支持 DeepSeek/GLM。

Seko 搭载 Seedance 2.0 全能模式,通过 Agent 工作流自动生成剧情、角色和分镜,720P 成本直降 50%,10 分钟出片。

阿里巴巴发布 HappyHorse 1.1 视频生成模型,动态表现力、主体一致性等五大维度提升,1080P 价格下调 25%,已上线百炼平台。