darwin-skill 2.0 是一个开源的 Skill/Prompt 自动优化工具,吸收了微软两篇论文精华,用多评委独立审查 + 人工卡口机制帮你把 AI 技能文档从 80 分拉到 90 分以上。

darwin-skill 2.0 是一个开源的 Skill/Prompt 自动优化工具,吸收了微软两篇论文精华,用多评委独立审查 + 人工卡口机制帮你把 AI 技能文档从 80 分拉到 90 分以上。
微信官方推出 ClawBot 插件,支持直接在聊天界面调用 OpenClaw。本文提供完整配置教程,涵盖多平台接入方案。
如果你维护过多个 AI Skill 或 Prompt,一定知道人工审稿有多痛苦:每个 Skill 都要通读、找问题、改完再读,人力上根本不可持续。但放任不管,Skill 会慢慢「漂移」,效果越来越差。
darwin-skill 2.0 是一个开源的 Skill 自动优化工具。它做的事情很简单:给你的 Skill 打分、提改进方案、改完再打分,分数没涨就回滚。整个流程像生物进化,一代代变异、选择、淘汰,留下来的都是更强的版本。
1.0 时代跑了一个月,平均涨 13.5 分,0 次回滚。看起来不错,但作者意识到 0 回滚不完全代表算法精准——评分标准定得多严,结果就有多严。
转折点是 2025 年 5 月 22 日微软研究院同一天挂出的两篇论文:
2.0 直接吸收了这两篇论文的精华,做了四项核心升级。
直接吸收 SkillLens 论文里把准确率从 46.4% 拉到 73.8% 的「药方」:
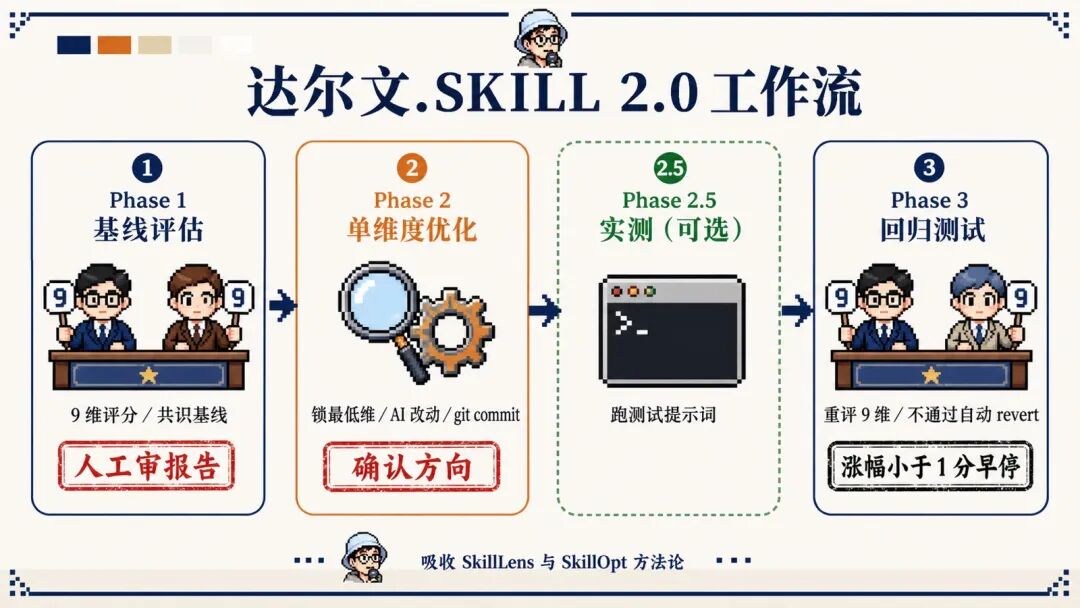
不再依赖单个 AI 评委。每轮启动两个独立评委(彼此不知道对方存在),共识分数才算数。下一轮启动两个全新评委,避免锚定效应。
如果分数进入平台期(单轮涨幅 < 1 分),早停机制自动停手。
这是达尔文跟 SkillOpt 最大的区别。SkillOpt 是 benchmark-driven 的全自动流程,适合企业级场景。但对个人开发者,benchmark 本身就难定义——「我自己读着顺不顺」这种主观维度没法塞进自动循环。
达尔文 2.0 在每个阶段都设了显性的人工介入点:
新增 8 条来自 40 次实战优化的反模式,包括:同一个 AI 又改又评、用 git reset --hard 当回滚手段、为凑分塞冗余、跳过测试直接评分、一轮改多个维度等。
用一个 368 行的真实 Skill(huashu-gpt-image)做测试:
| 阶段 | 分数 | 变化 |
|---|---|---|
| 基线 | 80.8 | 两个独立评委共识 |
| Round 1 | 91.5 | +10.7,只改了失败模式 |
| Round 2 | 91.65 | +0.15,早停触发 |
关键发现:只改了「失败模式」一维,「工作流」那一维居然从 7.5 跳到 9.0——因为失败模式要求写出明确分支,写出来后流程自动变清晰。这叫「维度相关簇」。
用 2.0 扫了整个 Skill 库,总共近 30 个 Skill。每个都跑两轮独立评委、9 维评分、validation-gated 回滚:
平均涨幅 +15 分。每个 Skill 的优化都有完整 git commit 链可回溯。
把仓库链接丢给你的 Agent,让它帮你安装:
帮我安装这个 Skill:https://github.com/alchaincyf/darwin-skill然后在 Agent 里说「跑达尔文优化 XX skill」即可。跑一轮基线评估 + 一轮优化大约 15-30 分钟,主要时间在等评委 Agent 返回。


