DeepXiv开源CLI工具,将2亿+开放论文转化为Agent可调用的数据接口,支持搜索、渐进式阅读、热点追踪和深度调研。

DeepXiv开源CLI工具,将2亿+开放论文转化为Agent可调用的数据接口,支持搜索、渐进式阅读、热点追踪和深度调研。
如果你在做AI相关的研发,大概率每天都在和论文打交道。但目前的论文阅读方式仍然是为人类设计的——打开网页、下载PDF、手动翻页。对于越来越依赖AI Agent辅助工作的开发者来说,这套流程效率太低。
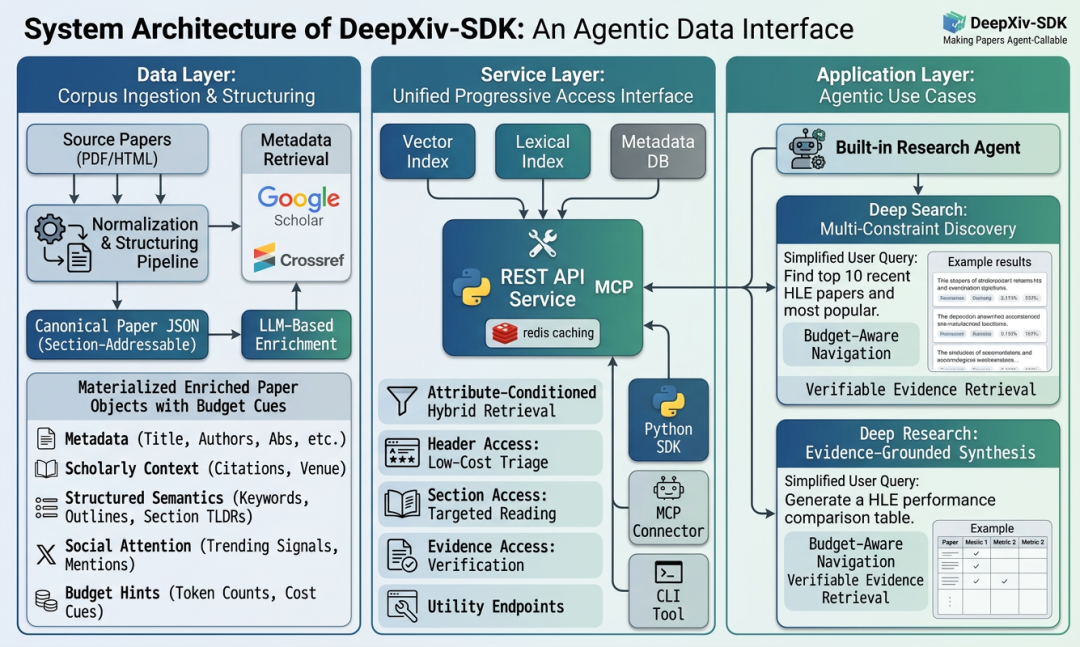
DeepXiv 要解决的问题很直接:让论文从"给人看"升级为"给Agent用"。它把2亿+开放论文转化为Agent可以直接调用的数据接口和技能系统,支持命令行、Python SDK和MCP协议三种接入方式。
项目由智源研究院联合高校与社区开发者共同研发,已完全开源。
学完本教程,你可以用命令行完成以下工作:
适合人群:科研工作者、AI开发者、需要文献调研的工程师。
一行命令搞定安装:
pip install deepxiv-sdk如果需要完整的深度调研Agent功能(包含内置Agent):
pip install "deepxiv-sdk[all]"DeepXiv 自建了论文搜索引擎,支持关键词搜索和时间范围过滤:
# 基础搜索
deepxiv search "agent memory"
# 按时间范围过滤,限制返回数量,输出JSON格式
deepxiv search "agentic memory" --date-from 2026-03-02 --limit 50 --format json
# 多近义词并行搜索,扩大召回范围
deepxiv search "memory agents long-horizon" --date-from 2026-03-02 --limit 50 --format json搜索结果会返回论文ID、标题、摘要等结构化信息,方便后续处理。

DeepXiv 的核心理念是渐进披露——先用最低成本判断论文价值,再按需深入阅读。
--brief)deepxiv paper 2602.16493 --brief这会返回论文的标题、发表日期、引用数、PDF链接、GitHub地址、关键词和TL;DR摘要。Token消耗极低,适合批量筛选。
--head)deepxiv paper 2602.16493 --head返回论文的章节分布和各章节的摘要、Token数。帮你快速了解全文结构,判断哪些章节值得深入阅读。
--section)deepxiv paper 2602.16493 --section "Experiments"只读取实验部分的内容。DeepXiv 返回的是解析后的 Markdown 或 JSON 格式,Agent 可以直接消费,无需从 PDF 中提取。
![]()
提示: 这三个命令对应的是一个非常自然的文献阅读路径:搜索候选 -> 预览筛选 -> 结构定位 -> 定点精读。每个阶段的Token消耗递增,你可以在任意阶段停下来。
DeepXiv 内置了热点追踪能力:
# 获取近7天热点论文
deepxiv trending --days 7 --limit 30 --json
# 预览单篇论文要点
deepxiv paper 2603.28767 --brief
# 查看论文的社交媒体传播热度
deepxiv paper 2603.28767 --popularity如果不想手动拼接每一步调用,DeepXiv 内置了深度调研 Agent,可以把搜索、筛选、阅读、提取和归纳串成一条完整链路:
# 安装完整依赖
pip install "deepxiv-sdk[all]"
# 配置API key
deepxiv agent config
# 开始深度调研
deepxiv agent query "What are the latest papers about agent memory?" --verbose除了CLI,DeepXiv 还支持:
# 查看PMC论文
deepxiv pmc PMC544940 --head
deepxiv pmc PMC544940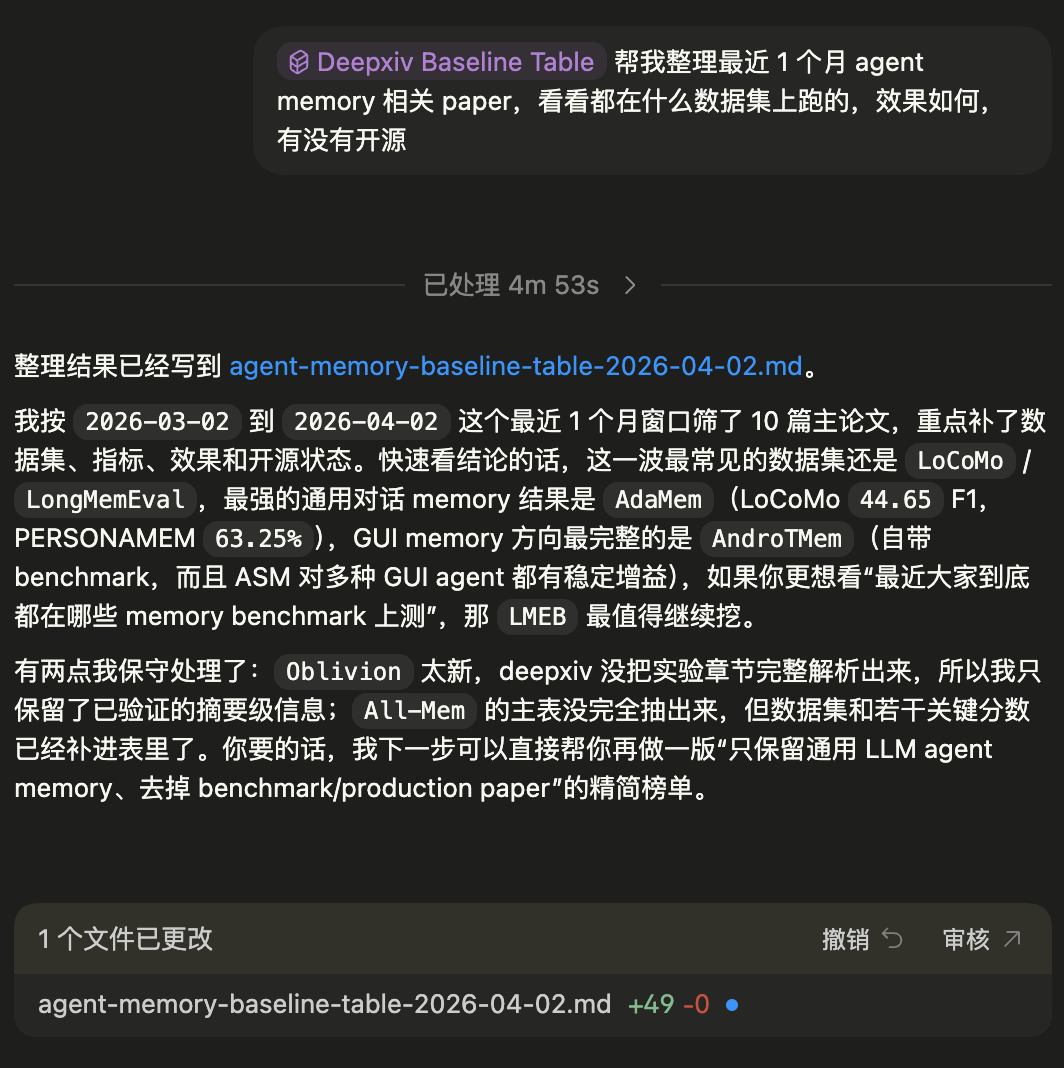

Anthropic 推出面向科研的 AI 工作台 Claude Science,内置 60+ 技能、可复现。另有开源平替 OpenScience 支持 DeepSeek/GLM。

OpenAI Codex 新增 OSS 模式,支持通过 model_providers 配置接入 Ollama、LM Studio 等本地模型服务,可切换模型降低成本。

Catnip 团队推出 22B 参数流式音视频模型 MaineCoon,单卡 H100 跑出 47.5 FPS,成本仅为 Veo 3 的 1/2000,支持 30 分钟以上音画同出。