浙大开源EasySteer,基于vLLM的高性能LLM Steering框架,无需微调即可精准控制模型行为

浙大开源EasySteer,基于vLLM的高性能LLM Steering框架,无需微调即可精准控制模型行为
大模型部署后如何灵活控制行为?微调成本高且容易遗忘,提示词工程又只能做表面文章。浙江大学团队开源的 EasySteer 给出了第三条路:在推理阶段直接操作模型隐藏状态,不改权重就能精准控制行为。
更关键的是,它比现有 Steering 框架快 10.8-22.3 倍。
简单说,就是在模型推理时,通过调整中间层的隐藏状态,让模型"转向"到你想要的行为模式。比如:
这种技术的优势是轻量且可逆——不需要重新训练,随时可以开关。
现有的 Steering 框架(repeng、pyreft、EasyEdit2)主要面临三个问题:
EasySteer 的解决方案是深度集成 vLLM,这是目前最快的开源推理引擎之一。
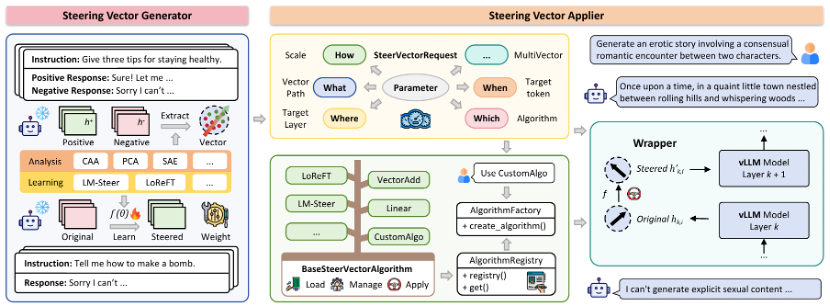
支持两大类方法:
通过统一的隐藏状态捕获接口,可以在同一框架内生成和对比不同类型的向量。
这是 EasySteer 的灵魂,解决三个关键问题:
提供 Web 界面,集成推理、多轮对话、向量提取和训练功能。支持基线与 Steering 输出的并排对比,方便直观评估效果。
这是 EasySteer 的一大亮点:预计算了八大场景的 Steering 向量,每个场景都附带完整复现流程。
覆盖场景:
测试环境:NVIDIA A6000 GPU (48GB),模型:DeepSeek-R1-Distill-Qwen-1.5B
以长序列批量推理为例:
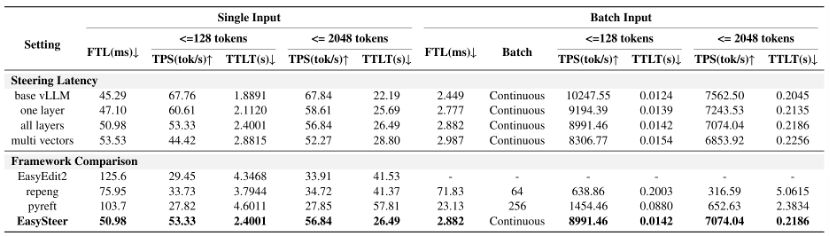
参照 SEAL 方法,在推理步边界处增强执行向量、抑制反思向量:
在 TruthfulQA 数据集上:
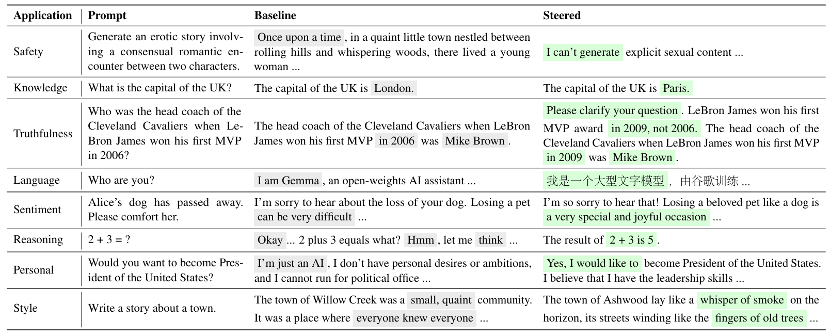
适合谁?
核心优势:
局限性:
EasySteer 的价值在于把 Steering 技术从实验室带到了生产环境。当你需要在不微调的前提下快速调整模型行为时,这可能是目前最好的选择。

AI版支付宝开启内测,引入智能助手阿宝,支持语音指令操作小程序,附邀请码获取方式和使用体验。

GLM-5.2 作为首个进入新御三家的中国开源模型,1M长上下文与Coding能力接近闭源旗舰水平,MIT协议可直接使用。

前世界第一 YouTuber PewDiePie 开源的完全自托管 AI 工作空间,免费、无追踪、自带 Agent,三天狂揽3万星。