蚂蚁集团ACL 2026新作FuseSearch-4B,通过自适应并行搜索策略,在代码定位任务上匹配Claude Haiku 4.5,速度快93.6%,Token省68.9%

蚂蚁集团ACL 2026新作FuseSearch-4B,通过自适应并行搜索策略,在代码定位任务上匹配Claude Haiku 4.5,速度快93.6%,Token省68.9%
在 AI 编程的实际应用中,超过 50% 的计算资源消耗在代码搜索与定位环节。蚂蚁集团的 FuseSearch-4B 提出了一个反直觉的解决方案:不需要堆参数,只需要让模型学会"什么时候该搜多少"。这个仅 40 亿参数的开源模型,在 SWE-bench Verified 上达到了 84.7% 的文件级 F1,匹配 Claude Haiku 4.5 的定位能力。
当 AI 编程 Agent 在一个几十万行代码的大型项目中寻找该改哪个文件、哪个函数时,现有方案有两个流派的痛点:
核心矛盾在于:并行少了信息不够用,并行多了浪费资源。FuseSearch 的洞察是——关键不在于并行多少,而在于什么时候该多并行、什么时候该少并行。

FuseSearch只使用三个只读工具:glob找文件、grep搜内容、read_file读细节。
FuseSearch 的工具箱极其克制,只有三个只读工具:
零依赖,拿来就能用。不需要代码知识图谱,不需要语法解析器。语言无关,Python 和 Java 仓库都能用。
论文首次提出**工具效率(Tool Efficiency)**指标:
信息增益 = 新发现的代码实体数 / 总返回的代码实体数
效率越高说明每次搜索都在探索新区域;效率越低说明在做重复劳动。这个指标直接把"搜索质量"变成了可量化的训练目标。
阶段一:监督微调(SFT)
从 233 个高质量 GitHub 仓库中提取约 21,000 个 issue-patch 对,用 Kimi-K2-Instruct 生成搜索轨迹。双重筛选标准:定位准确率 >= 0.8,工具效率 >= 0.5。最终从约 24,000 条候选中精选出约 6,000 条高质量数据。
阶段二:强化学习(RL)
奖励函数设计极为精妙:
奖励 = 0.8 x 定位准确率 + 0.2 x (定位准确率 x 工具效率)注意那个乘积项:只有"找得准"且"搜得不浪费"同时满足才能拿到额外奖励。如果定位完全错误,无论效率多高奖励都是零——模型不能"高效地犯错"。
经过 RL 训练,模型自动学会了一种"老司机"式的自适应搜索模式:
这种"先广度、后深度"的模式完全是模型从奖励信号中自己学出来的,没有任何人工规则。
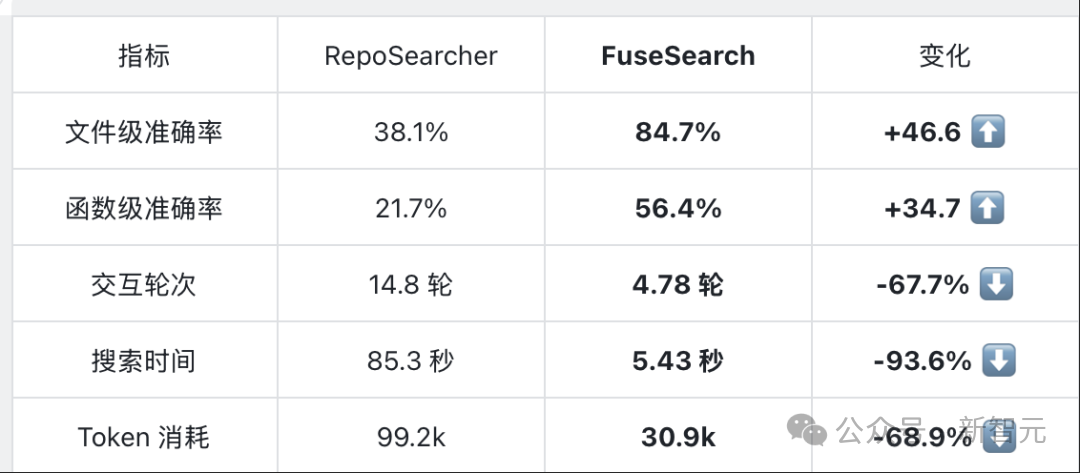
| 指标 | FuseSearch-4B | vs. 之前方法 |
|---|---|---|
| 文件级 F1 | 84.7% | 准确率翻倍 |
| 速度 | 快 93.6% | 速度快 16 倍 |
| Token 消耗 | 降低 68.9% | 省了近 70% |
一个可以本地部署的 4B 开源小模型,定位能力与 Claude Haiku 4.5 持平,同时更快、更省。
把 FuseSearch-4B 作为 Kimi-K2-Instruct 的"前置搜索引擎",不影响修复效果,直接把成本砍掉近一半。

腾讯云发布的两款领域龙虾AI工具,CloudQ 专注多云治理,AndonQ 擅长技术咨询,用自然语言对话替代控制台操作,提升云管理效率

面壁智能开源2B语音模型VoxCPM 2,支持30种语言、9种中国方言、声音克隆、音色设计与情绪控制,48kHz CD音质,免费商用。

开源微信命令行工具wechat-cli,支持11个命令操作本地微信数据,可导出聊天记录、搜索消息、统计分析,专为AI Agent集成设计。