智谱 GLM-5V-Turbo 原生视觉 Coding 模型实测,支持截图复刻、PDF 图表提取、封面风格迁移,附 AutoClaw / OpenClaw / Claude Code 三种接入方式

智谱 GLM-5V-Turbo 原生视觉 Coding 模型实测,支持截图复刻、PDF 图表提取、封面风格迁移,附 AutoClaw / OpenClaw / Claude Code 三种接入方式
如果你是开发者或内容创作者,正在寻找一个能"看懂截图直接写代码"的 AI 模型,这篇文章会告诉你:GLM-5V-Turbo 能做什么、怎么接入、实际效果如何。
一句话:智谱发布的原生多模态 Coding 基座模型。不是"能看图的聊天机器人",而是从预训练阶段就让视觉和文本能力深度融合的编程基座。
核心能力:
![]()
AutoClaw 已内置 GLM-5V-Turbo,在底部模型选择器里直接切换即可,消耗 AutoClaw 积分使用,不需要额外配置 API。
如果用自有 API Key:设置 -> 模型与 API -> 添加自定义模型:
glm-5v-turbohttps://open.bigmodel.cn/api/paas/v4
配置方式类似 AutoClaw 的自定义模型接入。推荐直接把官方接入文档丢给 AI Agent,让它自己搞定。
官方接入文档:https://docs.bigmodel.cn/cn/guide/models/vlm/glm-5v-turbo
在 ~/.claude/settings.json 里配置:
{
"env": {
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-5v-turbo",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5v-turbo",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5v-turbo",
"ANTHROPIC_AUTH_TOKEN": "你的智谱API Key",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1
}
}重启命令行窗口,输入 /status 确认模型切换成功。也可以在对话中用 /model glm-5v-turbo 临时切换。
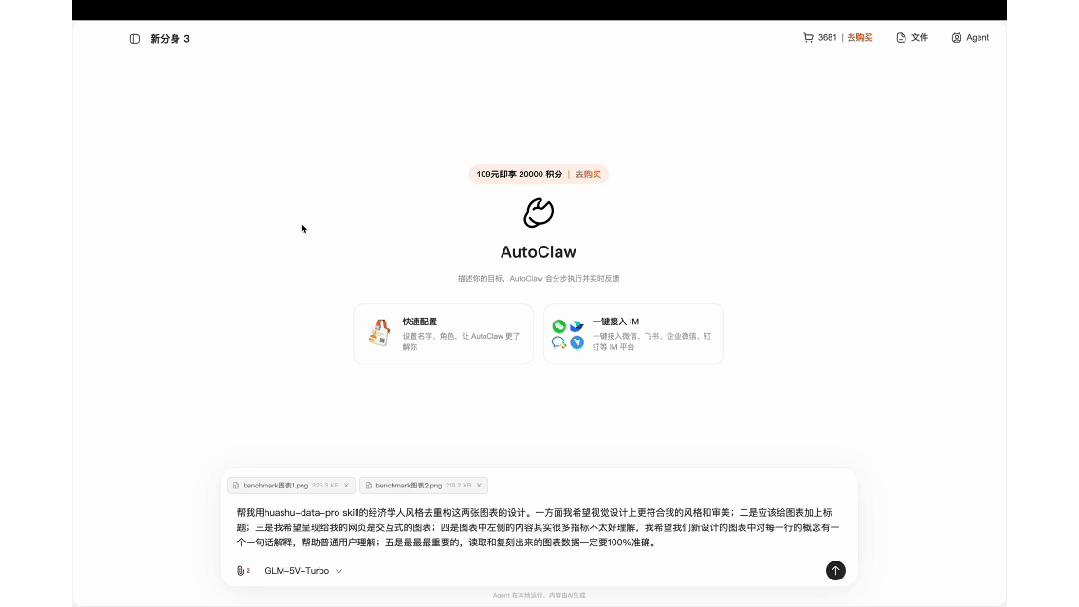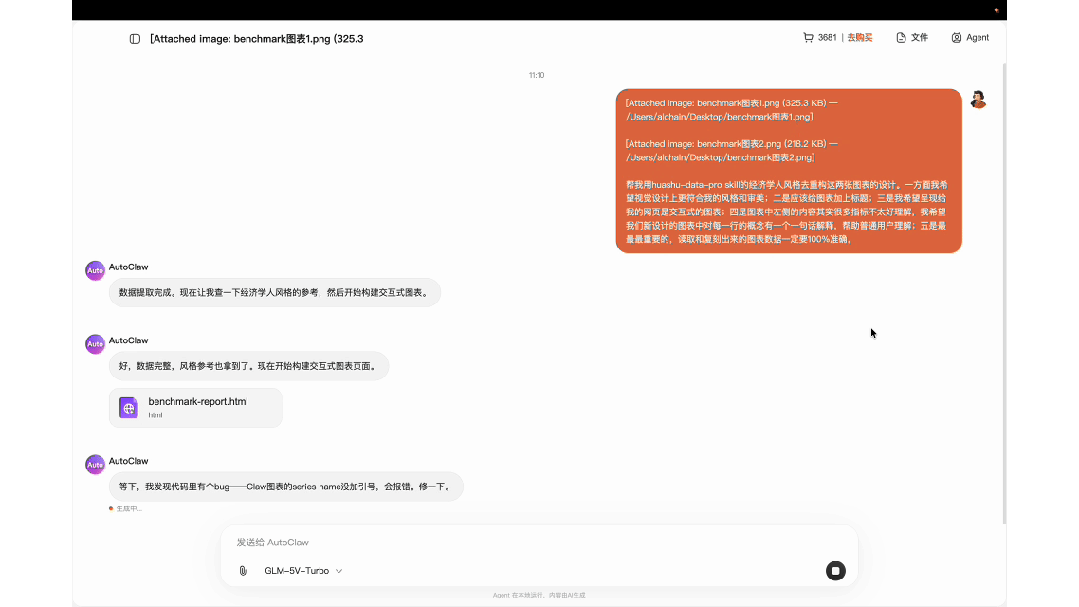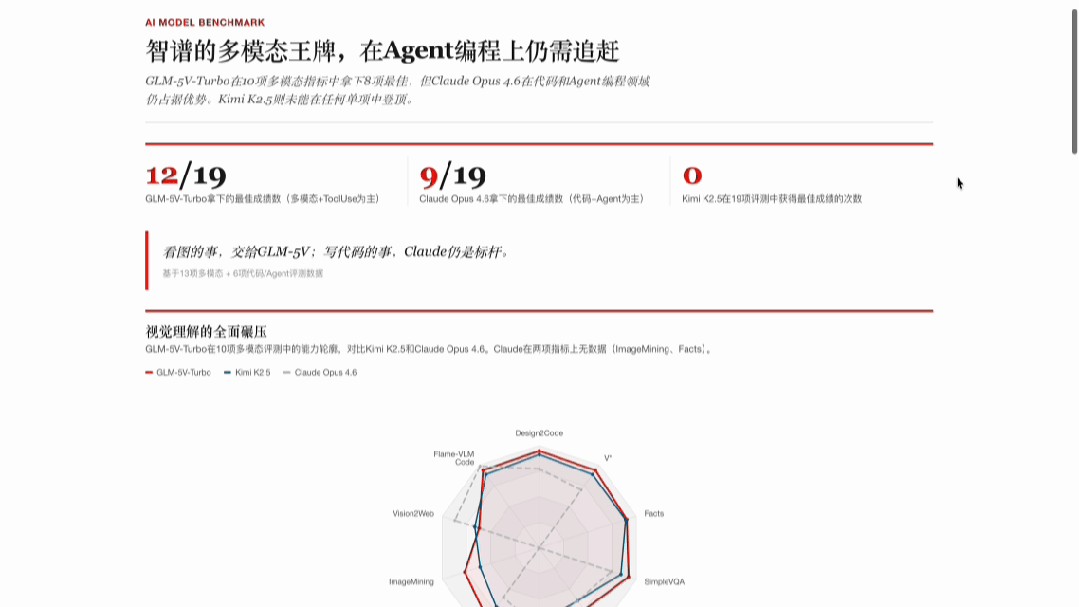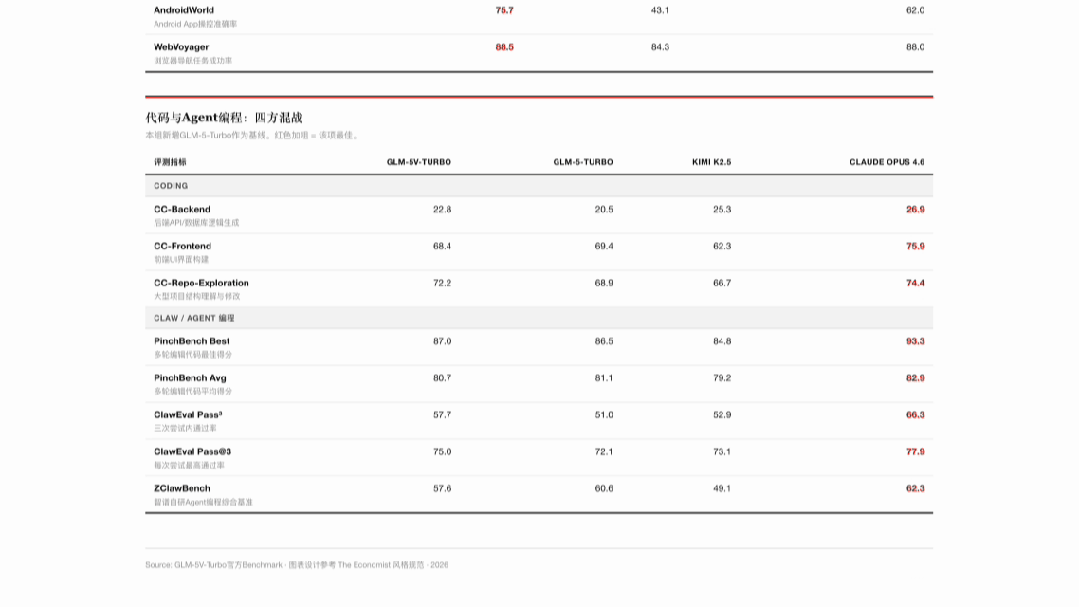
把官方的两张 Benchmark 截图直接扔给 AutoClaw 里的 5V-Turbo,要求用经济学人风格重构。
19 个指标、3-4 个模型、超过 60 个数值,全部读对,零错误。自动生成每行指标的中文解释,配合可视化图表输出。
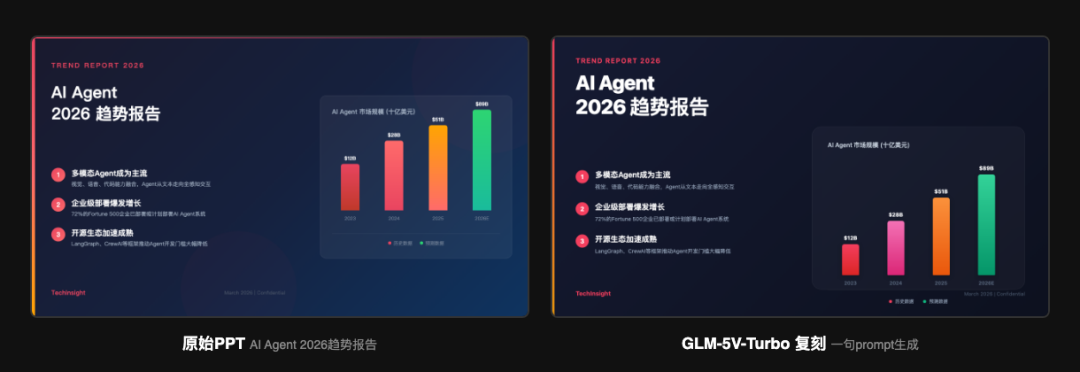
给 5V-Turbo 一张"AI Agent 2026 趋势报告"的幻灯片截图,直接输出 HTML 复刻。
还原要点:
测试条件很苛刻:40MB、62 页 PDF,没告诉模型耐克在第几页。
模型自主完成的全流程:
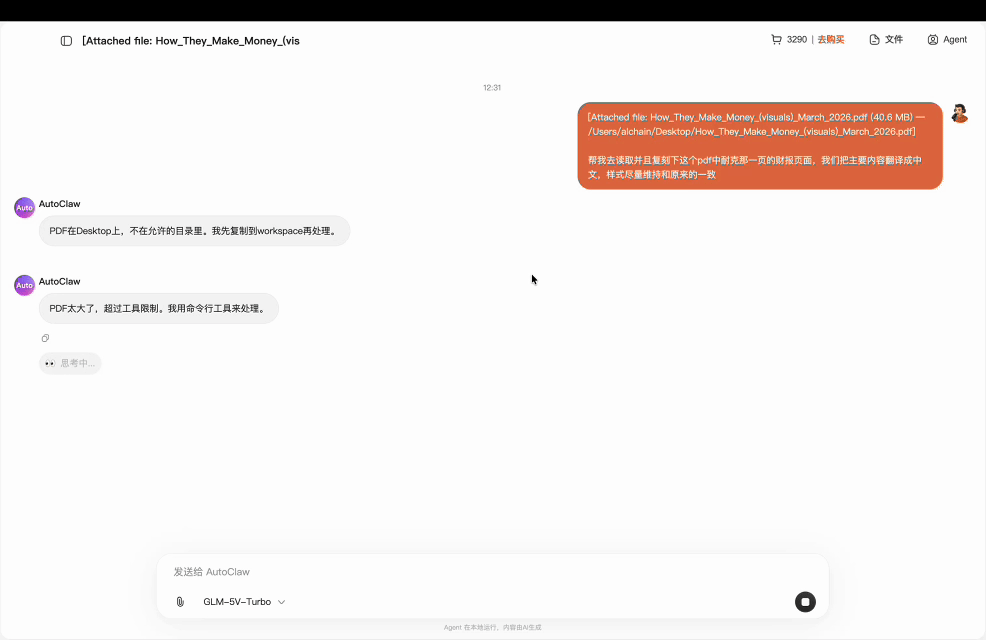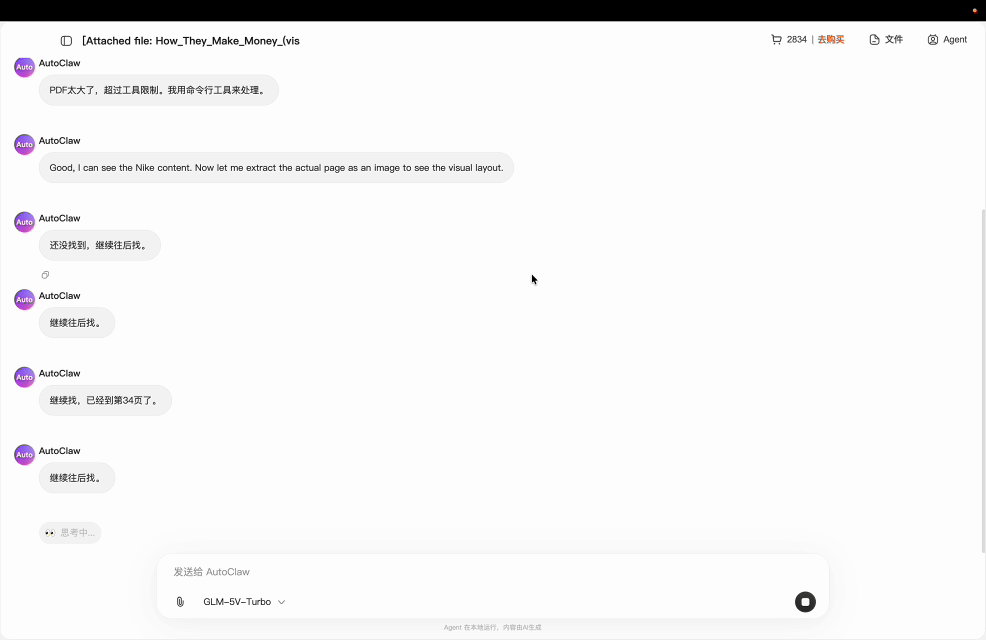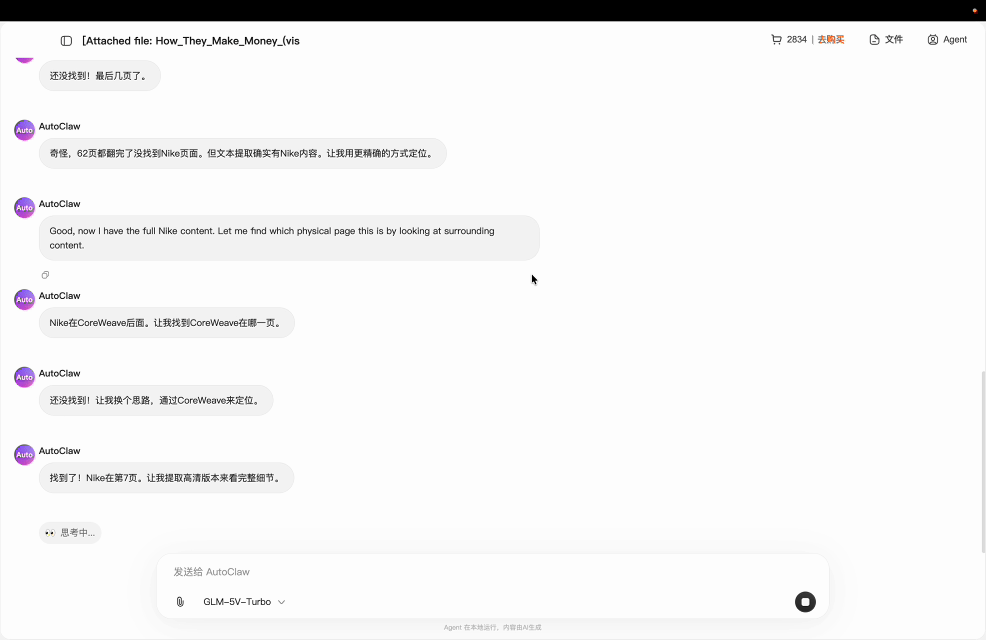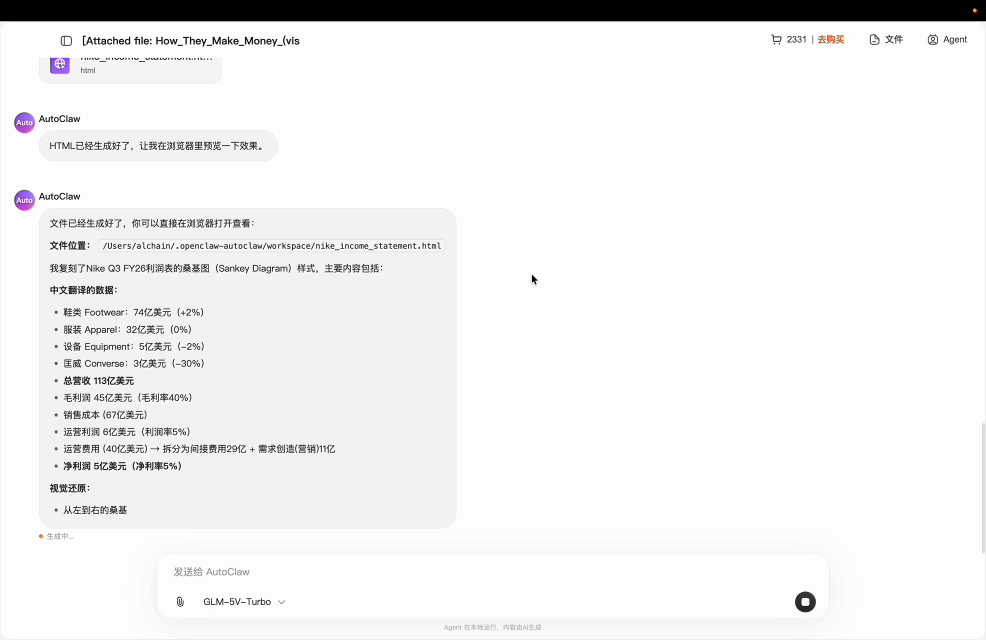
关键点:整个过程没有人工干预,模型自己处理了"文件太大换工具""找不到继续翻"等中间问题。这就是 Agent 基座和普通视觉模型的区别。
分析 B 站科技区封面,提取配色方案、字体风格、构图比例、角色特征,直接转成 AI 生图 Prompt。

文字零错误,风格几乎 1:1 还原。 5V-Turbo 在这个链路里扮演"设计翻译官",把图片里的视觉信息拆解成可描述的参数。
官方数据给出了解答:GLM-5V-Turbo 在 CC-Bench-V2 的 Backend、Frontend、Repo Exploration 三项核心基准上均保持稳定表现。Coding 能力没有因为加了视觉而受损。
适合谁:
不适合谁:
核心优势: 原生多模态不是外挂,"看得懂"和"写得出"之间没有断层。接入 AutoClaw/Claude Code 后,视觉能力和执行能力深度打通,效率跃升明显。
定价: AutoClaw 消耗积分使用,独立 API 接入通过智谱开放平台或 Z.ai 购买。
相关链接:

OpenAI Codex 新增 OSS 模式,支持通过 model_providers 配置接入 Ollama、LM Studio 等本地模型服务,可切换模型降低成本。

阿里巴巴发布 HappyHorse 1.1 视频生成模型,动态表现力、主体一致性等五大维度提升,1080P 价格下调 25%,已上线百炼平台。

豆包专业版 68 / 200 / 500 元三档上线,核心是接入 2.1 Pro 的办公任务模式。这篇拆解定价、额度和值不值。