GPT-Image-2 正式发布,无需复杂提示词即可生成高质量运营海报、知识卡片、游戏UI和网页设计稿,全面实测6大场景

GPT-Image-2 正式发布,无需复杂提示词即可生成高质量运营海报、知识卡片、游戏UI和网页设计稿,全面实测6大场景
OpenAI 正式发布了 GPT-Image-2,这是旗下首个具备思考能力的图像模型。它有两个模式:Instant 模式向所有用户开放,主打速度;Thinking 模式需要 Plus/Pro/Business 账户,生成前会联网搜索、规划结构并自我核查。
最让人惊喜的是:你不需要写复杂提示词。随手几个字,就能出非常高质量的结果。本文用 6 个真实场景,带你看看它到底能做什么。
日常工作中经常需要生成产品更新公告、活动海报等运营图片。以前至少需要设计师半天,现在几秒钟搞定。
苹果风格宣传图,提示词只需要:
用 gpt-image-2 为这个产品生成苹果风格的中文卡片宣传图

排版精美,中文字体渲染清晰,不需要额外调整。
品牌风格宣传图,给它一个产品更新链接:
根据这篇文章生成一个产品更新的介绍海报,风格需要符合 OpenAI 以往的设计风格,整体呈现苹果风、卡片化、高级感
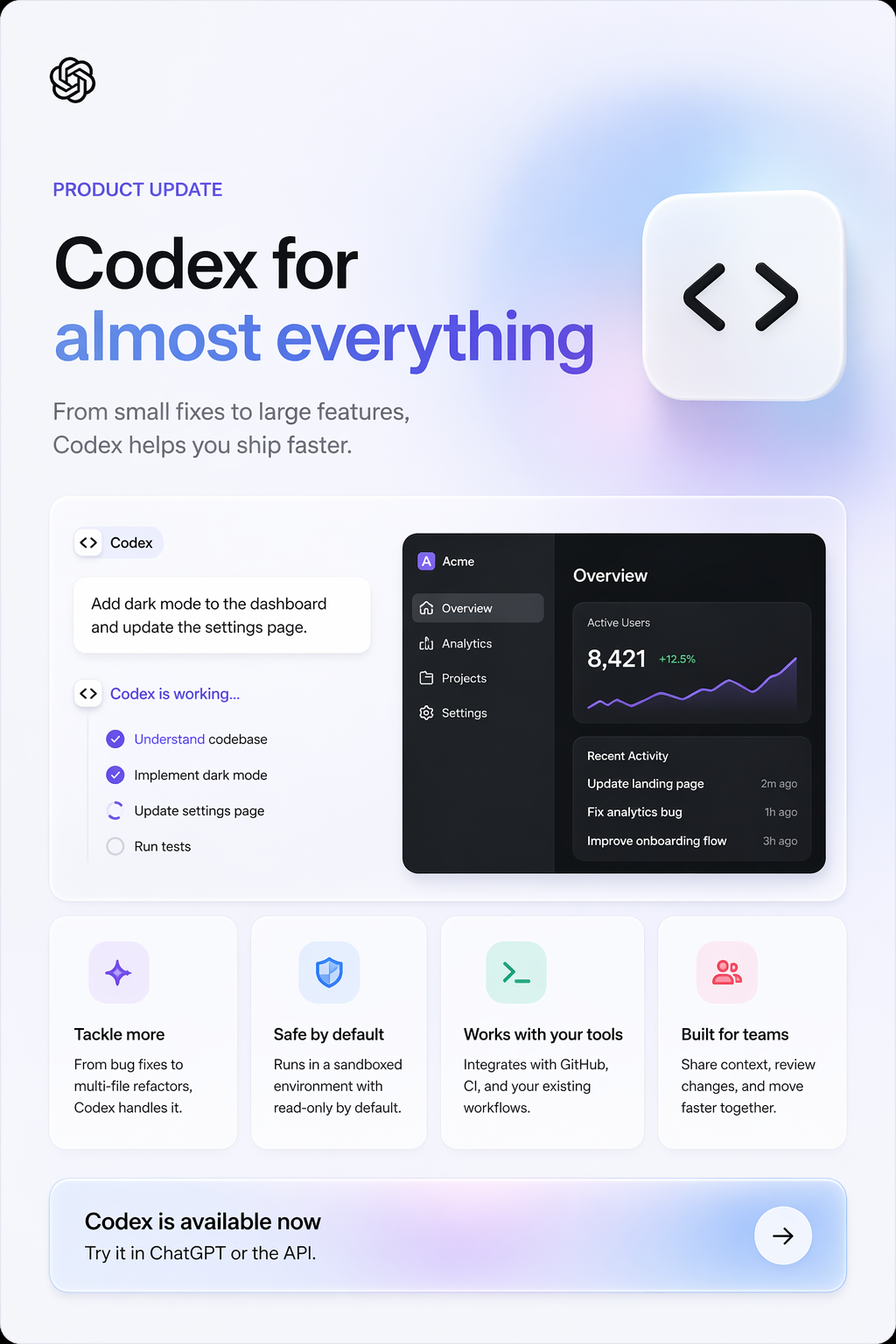
渐变配色、简洁设计感,风格延续得很好。
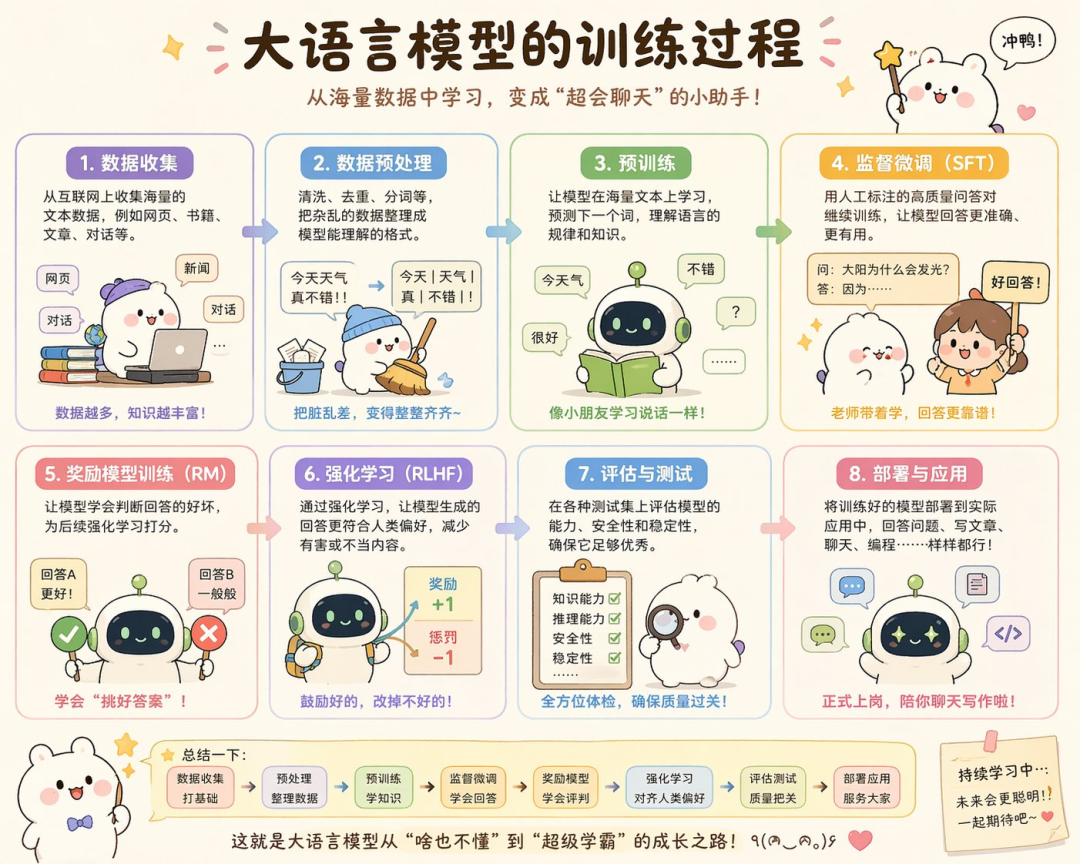
知识类卡片需要丰富的排版和准确的世界知识,这是 Image 2 的强项。
用可爱的风格画一张大语言模型的训练过程科普图
它甚至能生成超长长图,比如一张完整的北京秋季游览攻略,涵盖景点、行程、美食、交通指南,排版精细:
你不用告诉它该画什么,它知道一张科普图该有哪些内容。
游戏界面涉及复杂的 UI 布局、角色立绘、文字排版,Image 2 在这方面表现惊人。
参考《无畏契约》的游戏风格,生成一个以三国为主题、神话风格的 FPS 游戏选人界面 UI 图片
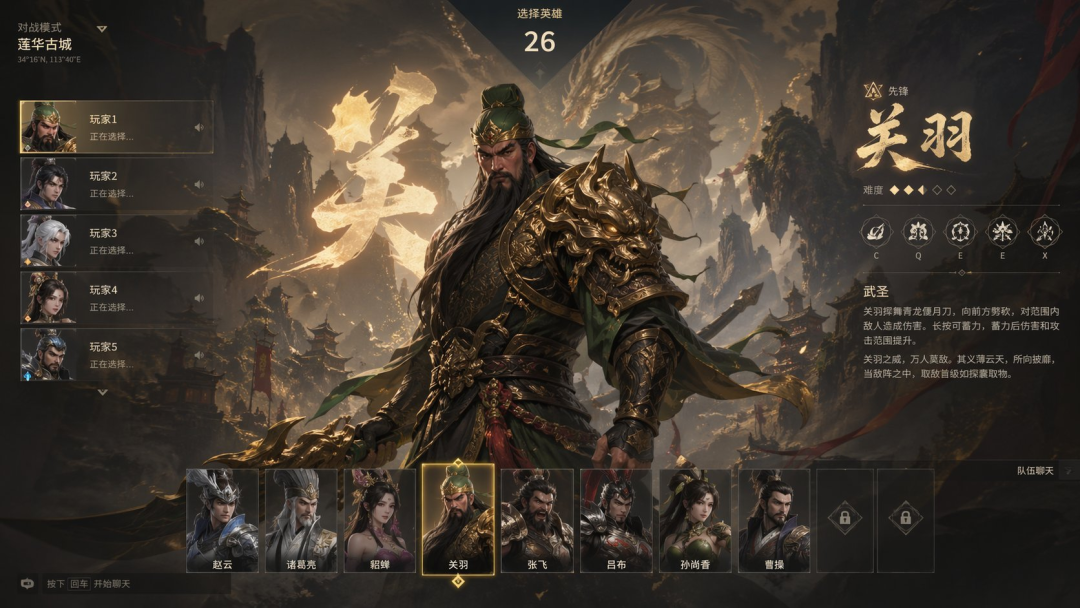
连极简提示词都能准确理解:
生成一个"黑神话武松"的游戏截图

更有意思的是,你可以直接在 ChatGPT 里玩 ARPG 游戏 -- 它生成带立绘和选择框的界面,你选哪个方向,它就画出下一张图。
💡 提示: 一张图加几句对话就是一个可玩的游戏 demo,游戏原型的门槛又塌了一层。
这是最让人意外的场景。只给一张汽车侧面照,它居然脑补出了完整的汽车官网:
为这个汽车生成符合其气质和风格的官网 UI 设计稿
内饰、剖面图、轮毂、大灯、尾翼、甚至价格全部自动填充,而且信息基本正确。
B 端官网也没问题:
为 B 端广告投放平台生成一个官网的 UI 设计稿
它知道这类网站应该展示哪些卖点和信息,仿佛一个资深产品经理和设计师的组合。
人像是检验图片模型最残酷的标准,因为人眼对细节极度敏感。
一个亚洲女生在黄昏花田里穿白纱裙,逆光摄影

逆光打在纱裙上的光晕、头发丝被风吹散的弧度,这种细节以前只有专业摄影师蹲半小时才能抓到。
💡 提示: 想让输出最自然,最有效的关键词是 "photorealistic"。模型会主动规避塑料感,复刻真实照片的特征。
把论文发给它,让它用杂志风格排版成可视化长图:
帮我用高级、有杂志感的排版风格,详细且图形化地介绍这篇论文的内容,生成一张长图

对于需要快速消化大量论文的研究者和开发者来说,这是一个非常实用的用法。
Image 2 并非完美,以下场景仍容易翻车:
| 入口 | 模式 | 用户范围 |
|---|---|---|
| ChatGPT | Instant | 所有用户(免费体验一周) |
| ChatGPT Plus/Pro/Business | Thinking | 付费用户 |
| Codex | 集成 | Codex 用户 |
| API (gpt-image-2) | 按画质/分辨率计费 | 开发者 |
目前 Canva、Figma、Adobe、OpenArt 已经明确接入 gpt-image-2。
如果你是设计师,Image 2 不会取代你,但会淘汰那些只会执行需求的设计师。它最擅长的是快速出方案、批量生成变体、处理重复性设计工作。把省下来的时间放在创意策略和品牌调性把控上,才是正确的用法。
如果你是开发者或产品经理,它可以直接帮你生成运营素材、产品原型视觉稿、科普图文,不再需要排队等设计资源。

火山引擎推出 Agent Plan,将字节自研模型、主流三方模型和联网搜索等工具打包订阅,适配 Claude Code、OpenClaw 等 Agent 平台。

Anthropic 发布 Agent View 研究预览版,一个界面管理多个 Claude Code 会话,支持后台并行、状态追踪和 worktree 隔离。

飞书 CLI 开源近 120 项能力,结合 Claude Code 实现会议知识库沉淀、工作复盘、对账自动化、画板协作和自动报销,全程免费可用。