北航联合团队开源的 InCoder-32B Thinking 模型,通过 ECoT 错误驱动推理和 ICWM 世界模型,让 AI 在写工业代码前先预判执行结果。

北航联合团队开源的 InCoder-32B Thinking 模型,通过 ECoT 错误驱动推理和 ICWM 世界模型,让 AI 在写工业代码前先预判执行结果。
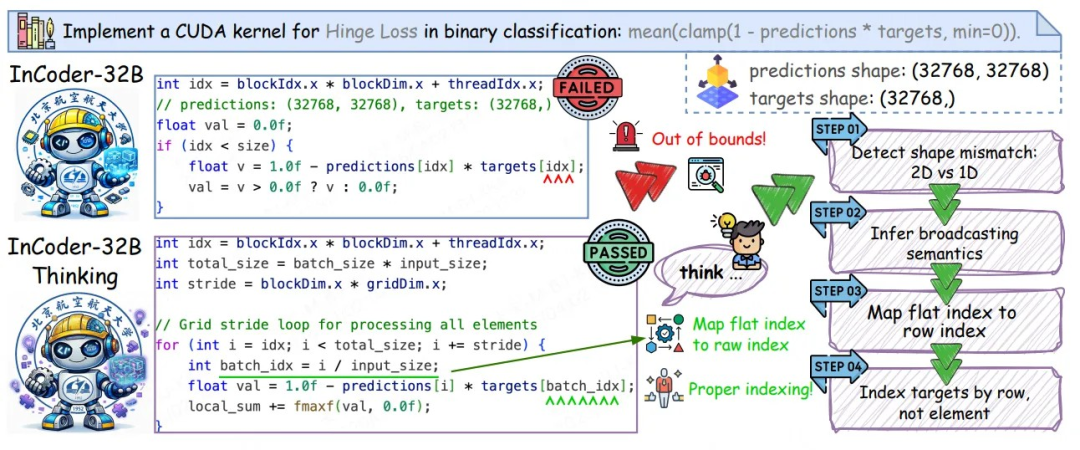
InCoder-32B Thinking 是一个专为工业代码场景设计的 32B 参数开源模型。它和普通代码模型的最大区别在于:写代码之前会先想清楚,这段代码放进真实系统会发生什么。
工业代码(Verilog、CUDA kernel、嵌入式程序等)和普通编程不同,语法正确远远不够。一个 Verilog 模块可能语法没问题,但在综合阶段直接失败;一个 CUDA kernel 逻辑上说得通,却在显存约束或索引映射上出错。
传统代码大模型只会"写",不会"想"。InCoder-32B Thinking 让模型在生成代码前,先预测这段代码在真实工具链中的执行结果。
Error-driven Chain-of-Thought(ECoT)是模型的核心训练方法。模型的思考能力不是人工标注的,而是从"生成 - 执行 - 报错 - 修复"的多轮过程中提炼出来的。
训练流程:
模型学到的不是"正确答案",而是工程师如何一步步定位问题、修复错误、验证结果。
Industrial Code World Model(ICWM)可以理解为代码的"预判引擎"。给定一段代码,它会预测:
ICWM 的预测准确率达到 96.7%,多轮轨迹一致性达到 94.4%。
不同工业任务的复杂度差异巨大。GPU kernel 优化的中位思考长度达到 19015 个字符,而 agentic coding 单步只有 91 个字符,差距超过 200 倍。
模型不是用固定长度的推理链,而是根据任务复杂度和环境反馈动态调整思考深度。
在 14 个通用代码 benchmark 和 9 个工业代码 benchmark 上的评测结果:
| 评测基准 | 得分 |
|---|---|
| CAD Coder | 84.0% |
| KernelBench L2 | 38.0% |
在芯片设计、GPU 优化、嵌入式、编译器、3D 建模等领域都取得了跨领域的提升。
模型和代码已完全开源:
# 克隆仓库
git clone https://github.com/CSJianYang/Industrial-Coder.git
cd Industrial-Coder
# 安装依赖
pip install -r requirements.txt
# 使用模型进行推理
python inference.py --model-path Multilingual-Multimodal-NLP/IndustrialCoder --task cuda_kernel32B 参数模型推理需要至少一张 A100 (80GB) GPU,或使用量化版本在较小显存上运行。具体配置建议参考 GitHub 仓库中的说明。

阿里巴巴发布 HappyHorse 1.1 视频生成模型,动态表现力、主体一致性等五大维度提升,1080P 价格下调 25%,已上线百炼平台。

DeepSeek 官方推荐的开源终端编程 Agent Deep Code,支持深度思考、推理强度调节与 Agent Skills,三步即可上手。

OpenAI Codex 新增 OSS 模式,支持通过 model_providers 配置接入 Ollama、LM Studio 等本地模型服务,可切换模型降低成本。