谷歌发布 Gemini Omni,整合 Nano Banana、Veo 和 Genie,支持任意输入生成视频,用自然语言对话式编辑,已上线 Gemini App 和 Google Flow。

谷歌发布 Gemini Omni,整合 Nano Banana、Veo 和 Genie,支持任意输入生成视频,用自然语言对话式编辑,已上线 Gemini App 和 Google Flow。
Gemini Omni 是谷歌在 I/O 2026 上发布的全新模型,定位为"世界模型"。它整合了图像模型 Nano Banana、视频生成模型 Veo 和世界模型 Genie,核心能力是"任意输入到任意输出"。当前阶段以视频生成为切入点,已面向 Google AI 订阅用户开放。如果你做视频内容创作或需要 AI 辅助的视觉制作,这个工具值得尝试。
Gemini Omni 不是单纯的视频生成模型。它把 Gemini 的推理能力与 Google 既有的生成式媒体模型结合,能同时理解文字、图像、音频、视频之间的关系,并基于这种理解生成或修改内容。
简单说:你可以给它一段文字、几张图片、一段音频,它理解这些素材之间的关联后,生成完整的视频内容。并且,你可以用自然语言持续修改生成结果。

这是 Omni 最实用的能力。你上传一段视频后,可以用自然语言告诉它怎么改:
Omni 会保留原始视频的人物动作和场景结构,只修改你指定的部分。每一轮修改都基于上一轮的结果继续,角色一致性、物理规律和场景记忆都会保持。

Omni 在物理模拟上有了质的飞跃。它能理解重力、动能、碰撞等物理规律。例如,当你要求生成"一条在连锁反应轨道上快速滚动的弹珠"时,Omni 展现出对物理法则的精确理解。
输入"制作一段蛋白质折叠的黏土动画解释",Omni 能直接产出带有结构演示的教学视频,不只是文字配图。
Omni 可以把图片、文字、视频和音频作为参考素材,整合成一个连贯的输出。不再需要从零开始写 Prompt,你可以直接用现有的素材组合作为输入。
Gemini Omni Flash 已于 5 月 19 日上线,面向以下用户开放:
| 使用渠道 | 开放范围 |
|---|---|
| Gemini App | Google AI Plus、Pro、Ultra 订阅用户 |
| Google Flow | Google AI 订阅用户 |
| YouTube Shorts | 本周起对所有用户免费 |
| API | 未来几周面向开发者和企业客户 |
在 Gemini App 中,你可以选择"生成视频"体验 Omni 的能力。目前提供 18 种预设风格,包括 80 年代 MV、蒙太奇、美漫、涂鸦特效、像素冒险等。Pro 账户每天有 3 次生成机会。
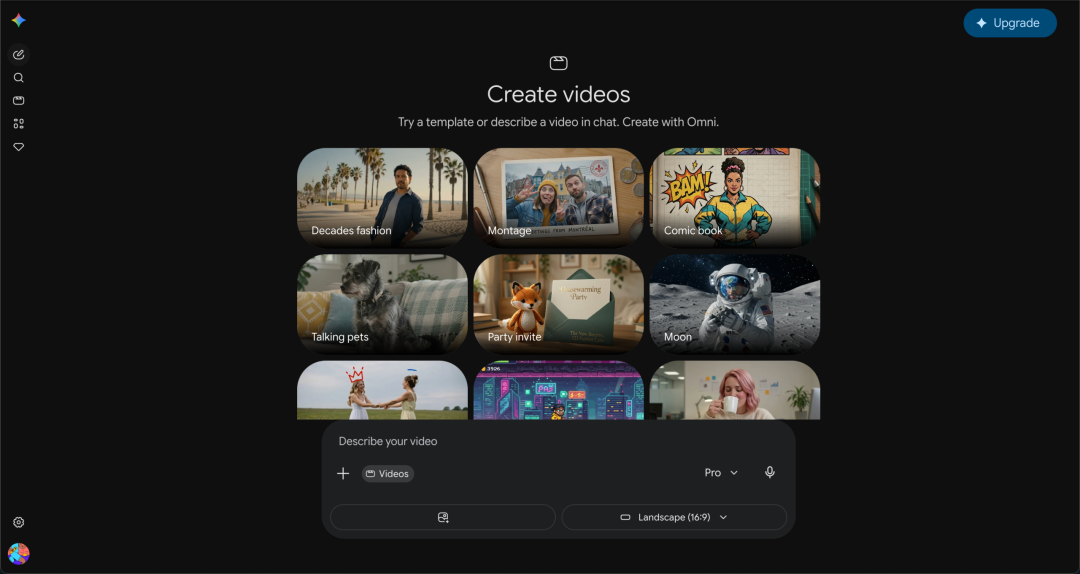
所有 Omni 生成的视频都自带肉眼不可见的 SynthID 数字水印。你可以在 Gemini App、Chrome 和 Google Search 中验证内容是否由 AI 生成。针对真实人脸的使用,Omni 还提供了 Avatar(数字分身)功能。
目前已经有网友将 Omni 和 Seedance 2.0 进行了初步对比。整体来看,Seedance 2.0 表现更稳定,Omni 在某些特定场景下表现更强,特别是在物理模拟和多轮编辑方面。

阿里巴巴发布 HappyHorse 1.1 视频生成模型,动态表现力、主体一致性等五大维度提升,1080P 价格下调 25%,已上线百炼平台。

Anthropic 推出面向科研的 AI 工作台 Claude Science,内置 60+ 技能、可复现。另有开源平替 OpenScience 支持 DeepSeek/GLM。

OpenAI 推出 Codex Security 插件,在 Codex 里一键扫描代码漏洞、验证可利用性并给出修复方案,附带完整上手步骤。