MiniMax M3 搭载全新稀疏注意力架构MSA,支持1M上下文窗口,Coding能力超过GPT-5.5,国内首个齐备前沿三大能力的模型

MiniMax M3 搭载全新稀疏注意力架构MSA,支持1M上下文窗口,Coding能力超过GPT-5.5,国内首个齐备前沿三大能力的模型
MiniMax M3 今日正式发布。这款模型在编程和 Agent 任务上达到前沿水平,搭载全新稀疏注意力架构 MSA(MiniMax Sparse Attention),最高支持 1M 超长上下文,同时是原生多模态模型,支持图片和视频输入并能操作电脑桌面。
M3 是国内第一个同时具备前沿 Coding 能力、超长上下文和原生多模态这三大要素的模型。
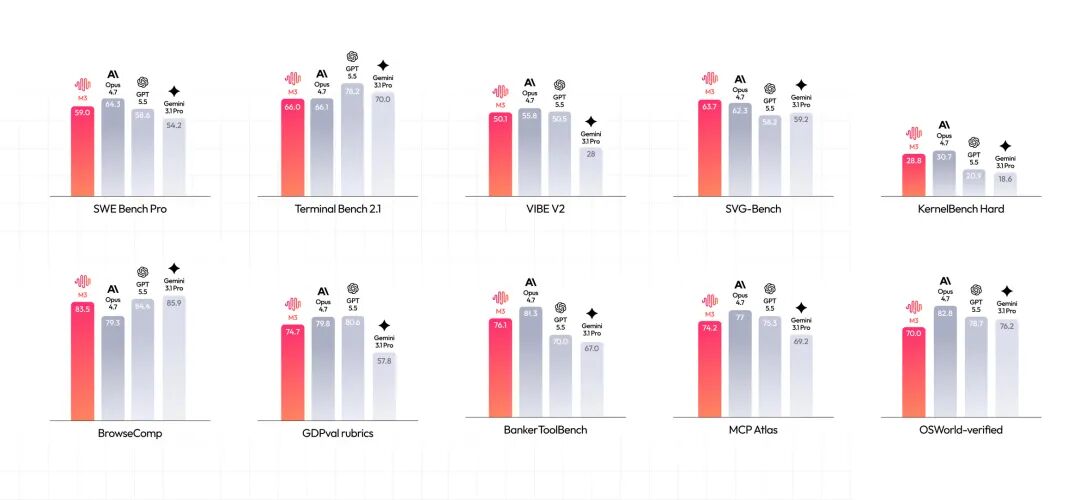
MiniMax M3 在多个基准测试中的表现
在衡量 Coding 能力的国际权威评测中,M3 达到国际领先水平:
M3 在 Agent 端到端评测框架 Claw-Eval 上也得到最高分。
MSA 是 MiniMax 自研的稀疏注意力架构,解决了全注意力机制计算复杂度平方级增长的问题。它的核心优势:
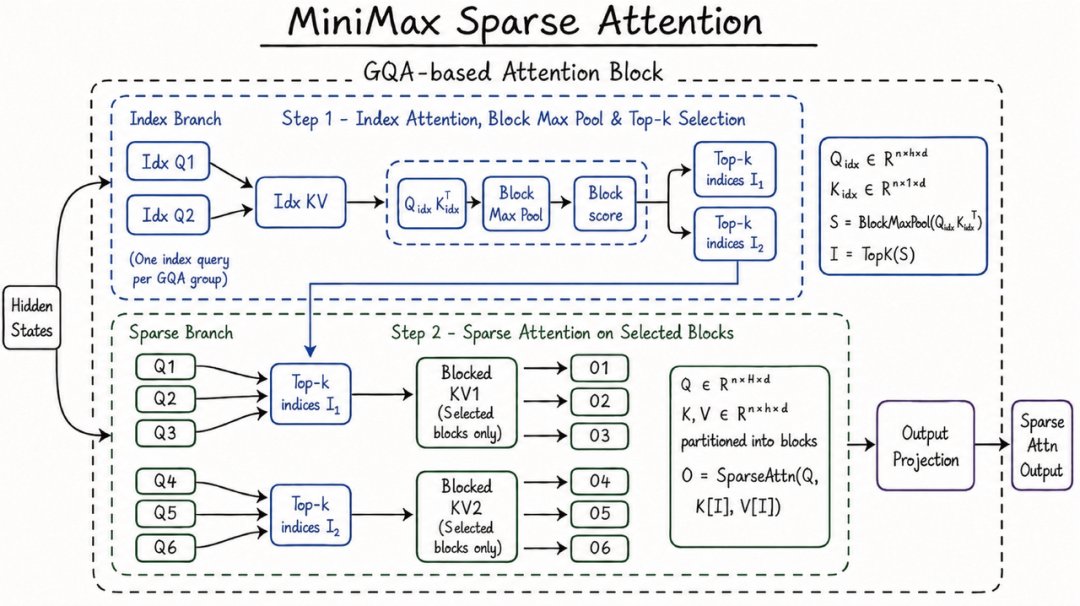
MSA 与其他稀疏注意力方案的速度对比
在 100 万上下文下,M3 每 token 计算量仅为上代模型的 1/20。Prefilling 阶段加速超过 9 倍,Decoding 阶段加速超过 15 倍。
M3 从 Step 0 开始进行多模态混合训练,不是后接视觉编码器,而是让不同模态数据的语义空间天然融合。训练数据中的 Interleaved data(交错数据)对性能提升尤为关键,训练 Token 规模已提升至 100 万亿量级。
MiniMax 团队给 M3 丢了一篇 ICLR 2025 Outstanding Paper Award 获奖论文——Learning Dynamics of LLM Finetuning,让它独立复现。
M3 自主运行了接近 12 小时,全程无人干预,最终:
这个测试同时调动了 M3 的三大能力:1M 超长上下文(读完整篇论文)、顶级编程能力(写实验代码)、原生多模态(生成和解读实验图表)。
你可以在以下平台第一时间体验 MiniMax M3:
M3 在 Coding 能力上的提升不仅靠 Benchmark 训练。MiniMax 构建了交互式用户模拟器框架,模拟真实开发者在协作过程中的行为模式:
这让 Agent 不再只是被动执行指令,而是能够主动与用户协同完成任务。下一代 Agent Coding 比的不仅是代码生成,更是长期协作能力和人与 Agent 的协同效率。

魔搭开源Diffusion Templates框架和11个现成模板,支持亮度、风格、修图、超分辨率等即插即用控制,大幅降低可控生成门槛。

GitHub 20k星的开源项目OpenCLI,将100+网站、微信、飞书等私域数据转为命令行操作,本地浏览器执行零Token消耗。

OpenAI和Anthropic正面对决:Codex企业用户免费2个月含一键迁移工具,Claude Code周额度提升50%。开发者成了最大赢家。