OpenResearcher 提供完整开源的深度研究轨迹合成流水线,9.7 万条长程训练数据免费可用,微调后 30B 模型在 BrowseComp-Plus 达到 54.8% 准确率,超越多个主流闭源模型。

OpenResearcher 提供完整开源的深度研究轨迹合成流水线,9.7 万条长程训练数据免费可用,微调后 30B 模型在 BrowseComp-Plus 达到 54.8% 准确率,超越多个主流闭源模型。
训练一个能真正「搜索 → 浏览 → 推理」的深度研究 Agent,最大的瓶颈不是模型本身,而是缺乏高质量的长程研究轨迹数据。Texas A&M、Waterloo、UC San Diego 等机构联合推出的 OpenResearcher,是目前第一个完全开源、可本地复现的深度研究轨迹合成流水线,合成数据已被 NVIDIA 采用于基座模型训练。
OpenResearcher 不是一个直接使用的研究工具,而是一条训练深度研究 Agent 的数据合成流水线。它解决的问题是:如何在不依赖昂贵在线 API 的情况下,批量生成包含 100+ 轮工具调用的长程研究轨迹,用于微调小参数量模型。
核心思路:一次性抓取在线语料构建包含 1500 万篇候选文档的本地搜索引擎,由教师模型在完全离线环境中调用 search、open、find 三种工具合成研究轨迹。
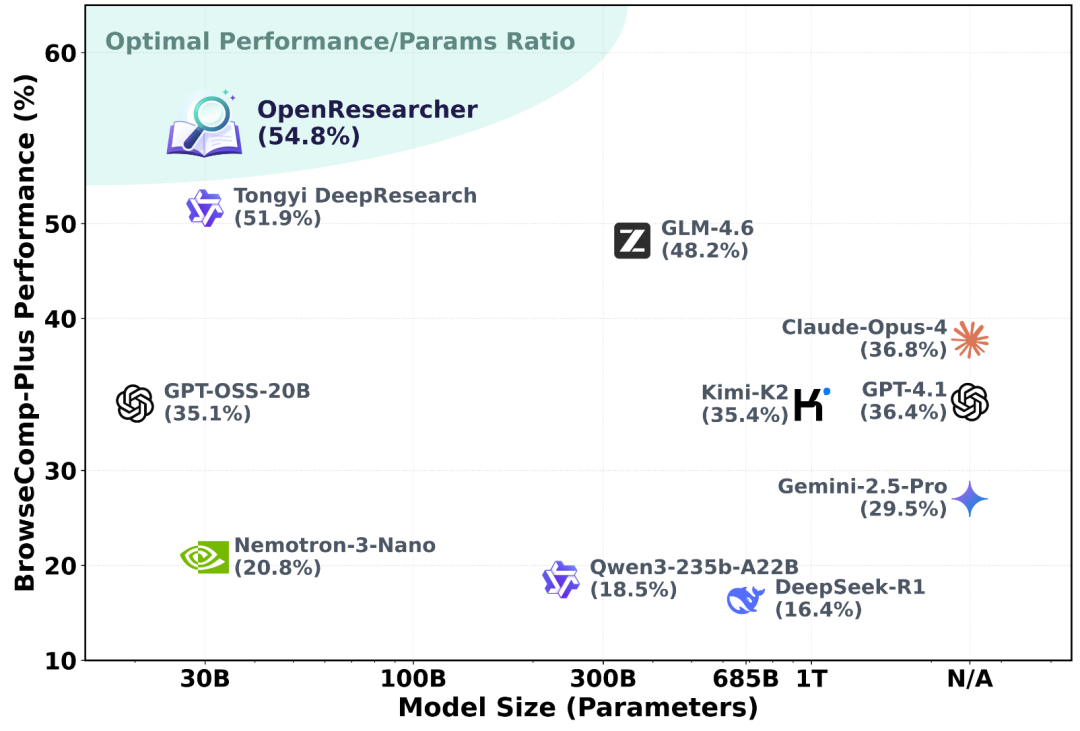
OpenResearcher 30B 在参数量/性能比维度上显著领先所有对比模型。
传统方案每次失败的搜索路径都消耗 API 配额,大规模合成意味着数万美元开支。OpenResearcher 将所有文档本地化,教师模型在离线环境中完成全部合成,成本大幅降低。
Agent 在合成过程中只使用三种原子工具,结构简洁易于迁移:
search:在本地语料库中检索相关文档open:打开并读取指定文档全文find:在文档内精准定位特定信息现有开源数据集多为 2-5 轮浅层交互,无法覆盖真实深度研究场景。OpenResearcher 的轨迹平均工具调用次数远超现有数据集,是训练长程推理能力的关键差异点。

Codex 的 Computer Use、Chrome 插件、应用内浏览器三种操作模式各有适用场景,本文拆解权限体系并给出最佳实践。

DeepSeek 官方推荐的开源终端编程 Agent Deep Code,支持深度思考、推理强度调节与 Agent Skills,三步即可上手。

Anthropic 推出面向科研的 AI 工作台 Claude Science,内置 60+ 技能、可复现。另有开源平替 OpenScience 支持 DeepSeek/GLM。