阿里千问发布全模态模型Qwen3.5-Omni,支持文本、图片、音视频输入,可实时视频通话生成代码、解读论文,拿下215项SOTA,性能比肩Gemini 3.1 Pro

阿里千问发布全模态模型Qwen3.5-Omni,支持文本、图片、音视频输入,可实时视频通话生成代码、解读论文,拿下215项SOTA,性能比肩Gemini 3.1 Pro
Qwen3.5-Omni 是阿里千问推出的全模态AI模型,最大的亮点是可以像真人一样进行视频通话。你可以打开摄像头,让它看着你的屏幕实时生成代码、解读论文、分析视频内容。不需要复制粘贴文字,不需要截图上传,直接"看着说"就能完成工作。
适合谁用:开发者、研究人员、内容创作者,以及任何需要AI辅助处理多模态信息的人。
打开摄像头,在纸上画个前端草图,Qwen3.5-Omni 就能边看边生成完整的 HTML+CSS 代码。整个过程就像和真人程序员视频会议一样自然。

实测体验:
上传一段视频(比如电影预告片),Qwen3.5-Omni 能生成带时间戳的详细脚本,包括:
测试中,它成功拆解了《疯狂动物城2》预告片的所有分镜,甚至能准确识别37秒处的角色并分析氛围。
不用再对着满屏英文术语头疼。打开摄像头对准论文,Qwen3.5-Omni 会:
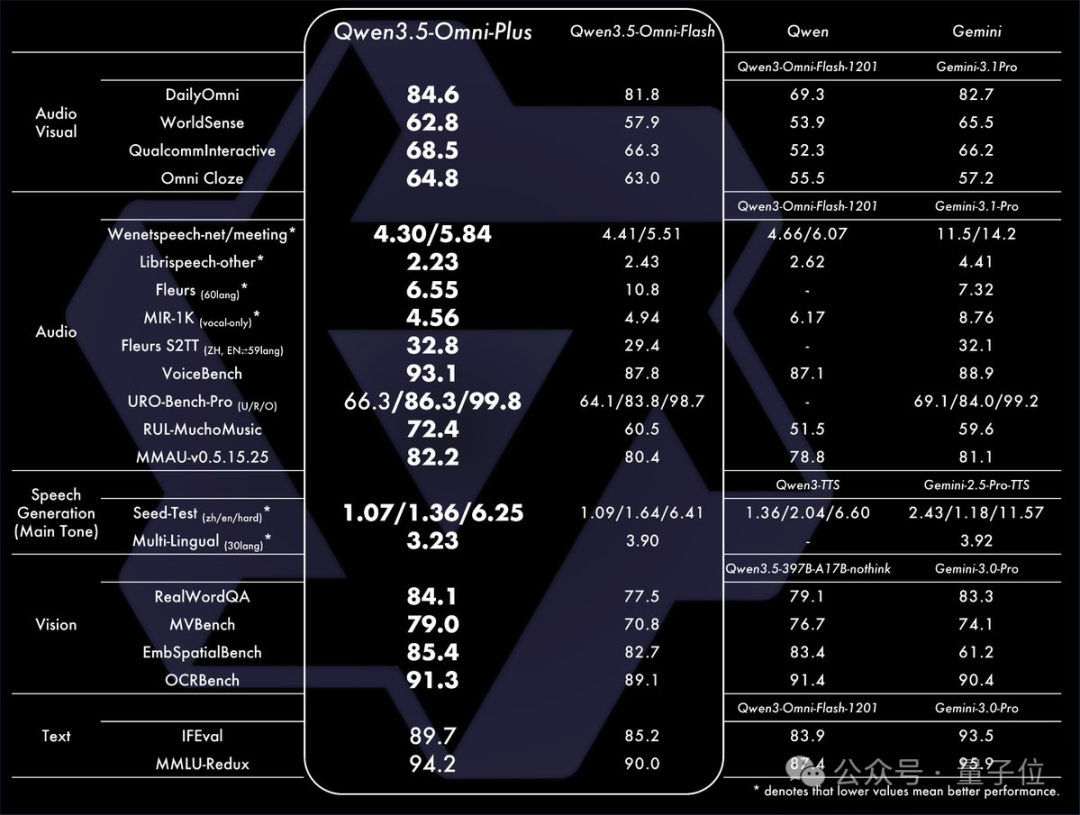
Qwen3.5-Omni 在多个基准测试中拿下 215项SOTA,整体成绩与 Gemini 3.1 Pro 打得有来有回:
自适应速率交错对齐技术,解决了AI说话不稳定的老问题(漏读、读错、数字发音奇怪)。
边输入、边处理、边生成,实现真正的实时交互,而不是"说一句等三秒"。
目前 Qwen3.5-Omni 已在 Qwen Chat 上线,支持三种尺寸:
体验方式:
API 调用:
体验地址:

Codex 的 Computer Use、Chrome 插件、应用内浏览器三种操作模式各有适用场景,本文拆解权限体系并给出最佳实践。

豆包专业版 68 / 200 / 500 元三档上线,核心是接入 2.1 Pro 的办公任务模式。这篇拆解定价、额度和值不值。

Anthropic 推出面向科研的 AI 工作台 Claude Science,内置 60+ 技能、可复现。另有开源平替 OpenScience 支持 DeepSeek/GLM。