清华大学开源视频生成加速框架RhymeFlow,无需重训练即可让Wan 2.1、CogVideoX等DiT模型推理提速1.5x-1.8x,质量几乎无损,62.5%用户无法区分差异。

清华大学开源视频生成加速框架RhymeFlow,无需重训练即可让Wan 2.1、CogVideoX等DiT模型推理提速1.5x-1.8x,质量几乎无损,62.5%用户无法区分差异。
清华大学与 GigaAI 联合开源了 RhymeFlow——一个完全训练免费的视频生成加速框架。它不需要重新训练模型,直接在推理阶段应用"帧间异步调度",让 Wan 2.1、CogVideoX 等 DiT 视频模型的推理速度提升 1.5 倍到 1.8 倍。
在 82 人的双盲用户研究中,62.5% 的用户无法将 RhymeFlow 的输出与原始模型区分开来。
当前主流 DiT 视频模型(Wan 2.1、CogVideoX、Sora)有一个共同的痛点:生成一段 81 帧 720p 视频,单张 A800 GPU 要跑将近 17 分钟。
现有的加速方法(稀疏注意力、KV 缓存、量化)优化的是单步内的计算量。但没人动过一个更根本的问题——所有帧被一视同仁,哪怕相邻帧内容几乎完全相同,也要走完完整的 50 步去噪流程。
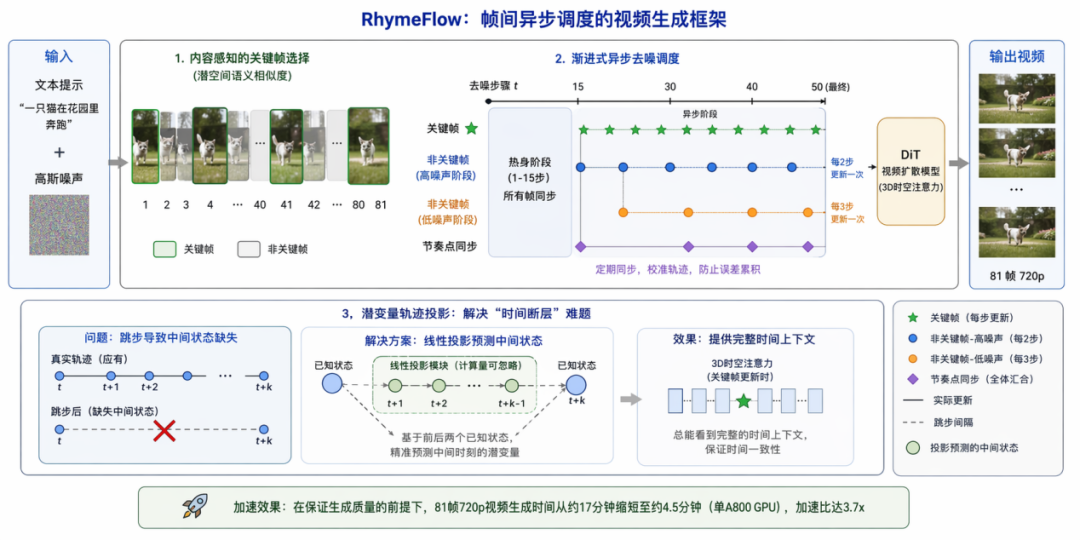
RhymeFlow 的核心洞察是:视频的语义和运动是连续的,关键帧决定全局结构,非关键帧的轨迹高度可预测。既然如此,为什么不让不同帧各走各的路?

不是简单均匀采样,而是通过潜空间语义相似度,自动识别包含场景切换、物体运动突变的关键帧。这些帧获得完整的计算资源,确保视频的结构完整性和语义准确性。
关键帧每步都更新,非关键帧按噪声阶段差异化跳步推进:
非关键帧跳步后,中间状态缺失会破坏 3D 注意力的时间一致性。RhymeFlow 用一个计算量可忽略的线性投影模块,基于前后两个已知状态精准预测中间时刻的潜变量——相当于给非关键帧画了一条平滑的运动轨迹。
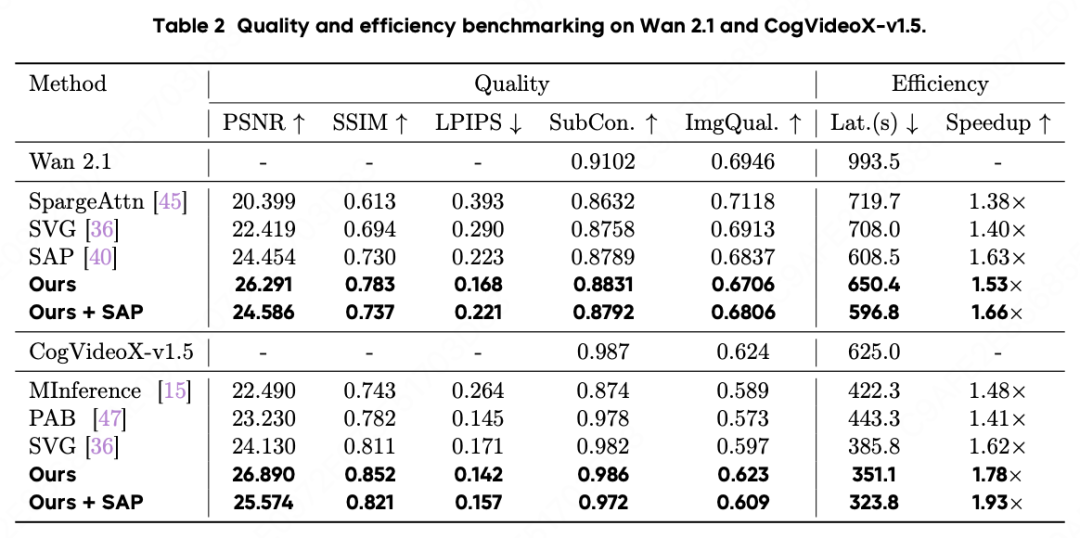
在主流开源模型上的测试结果:
与 SOTA 方法对比:
82 人双盲用户研究:
RhymeFlow 适合以下场景:
框架完全开源,无需重新训练模型,可直接集成到现有的 DiT 推理管线中。

手把手带你跑通百度搭子 DuMate 的提需求→授权→执行→交付链路,安装、界面、办公场景实操与自动化一文说清

Anthropic 发布 Claude Tag,把 Claude 嵌入 Slack 工作流,支持共享上下文、持续记忆和主动介入,团队协作新范式。

豆包上线专业版,搭载豆包 2.1 Pro 的 Agent 驱动办公任务模式,能操作本地电脑、分析财报、自建 Skill,实测交付质量对标 Claude Opus。