LibTV 平台集成 Seedance 2.0 满血版,画布式工作流串联剧本、分镜、生成、剪辑全流程,无需排队,附操作教程和避坑指南

LibTV 平台集成 Seedance 2.0 满血版,画布式工作流串联剧本、分镜、生成、剪辑全流程,无需排队,附操作教程和避坑指南
即梦官网用 Seedance 2.0 生成视频需要排队到怀疑人生。这篇文章介绍一个替代方案:LibTV 平台,集成了满血版 Seedance 2.0,完全不需要排队,还提供画布式工作流,从剧本到成片一站式搞定。
LibTV 不是视频生成模型,是一个平台。把市面上主流的视频生成模型(Seedance、可灵等)全部接进来,你不用一个一个去注册、充值,一站搞定。
2025 年 3 月 18 日发布,上线首日访问量突破 10 万。
它最大的不同在于工作流设计。 平时做视频是割裂的:剧本用一个工具,分镜换一个,生成再跳一个,剪辑还得去剪映。LibTV 把这些全打通了:
剧本 -> 视频脚本 -> 分镜设计 -> 视频生成 -> 成片全部在 LibTV 一个画布里完成。
![]()
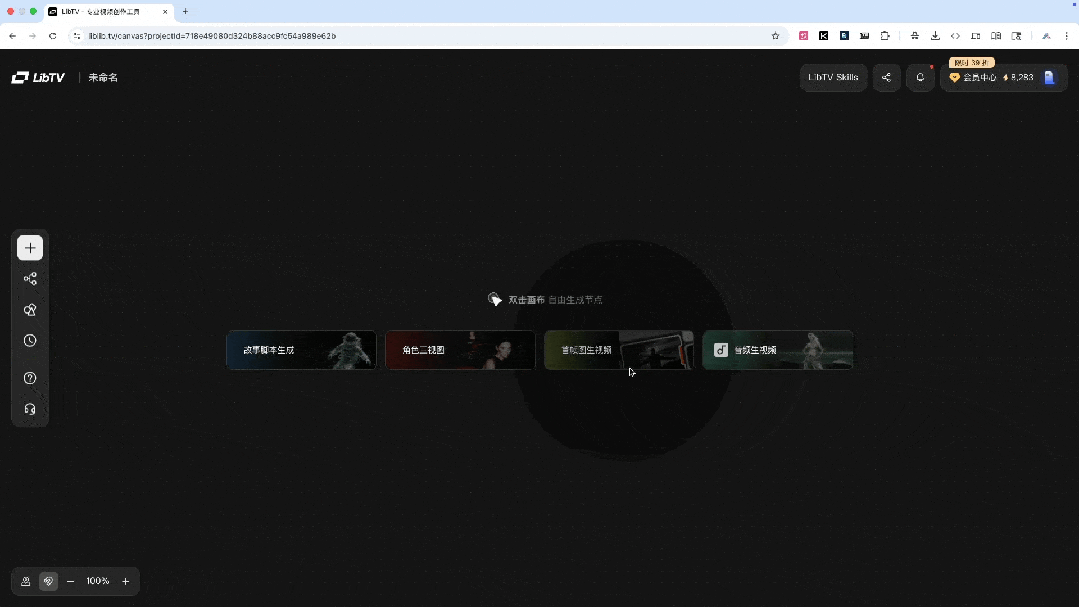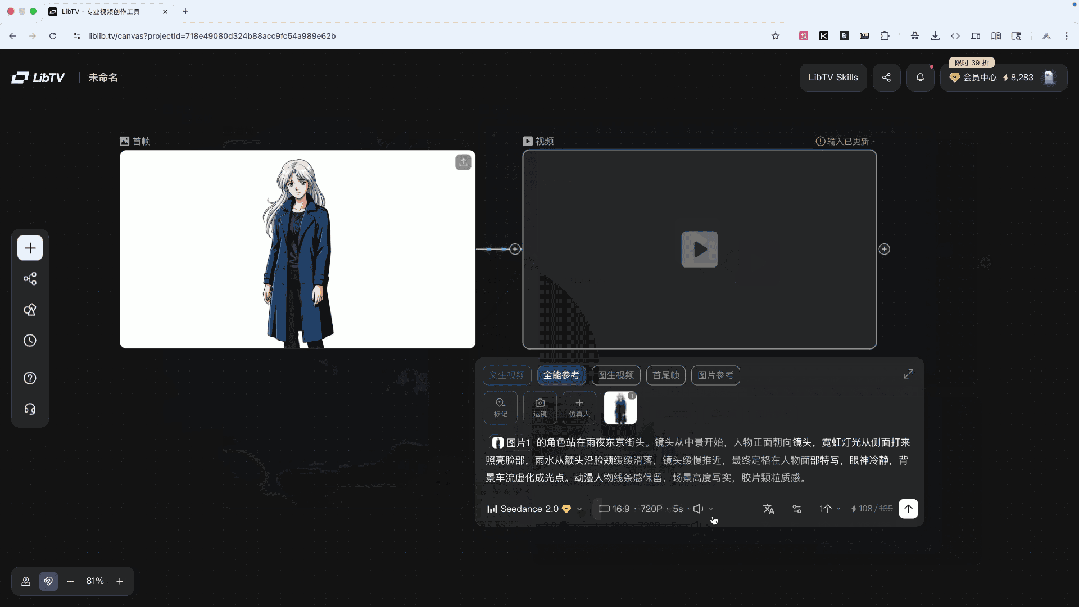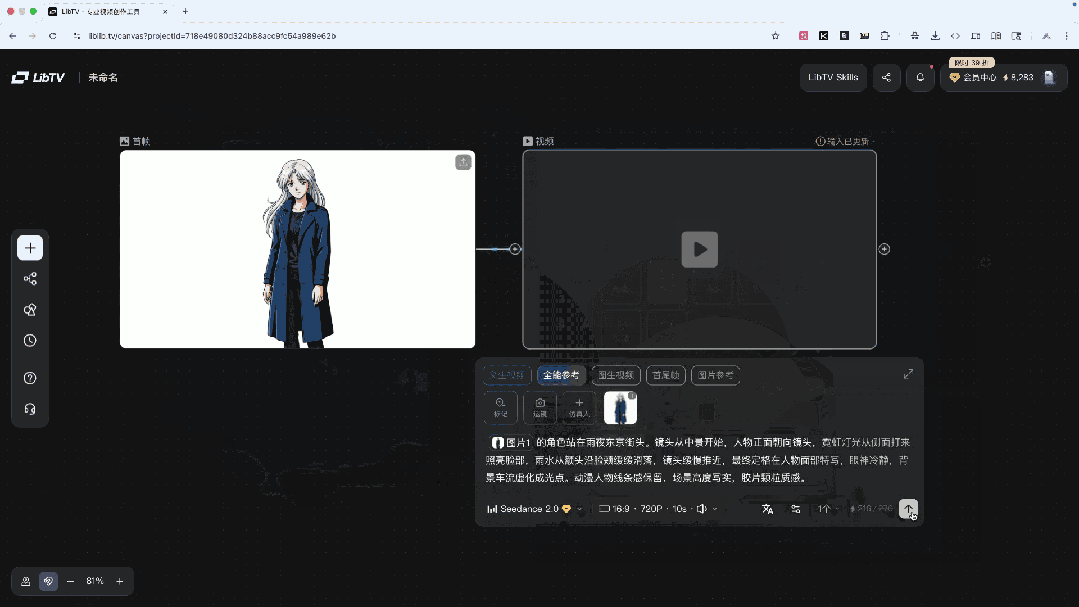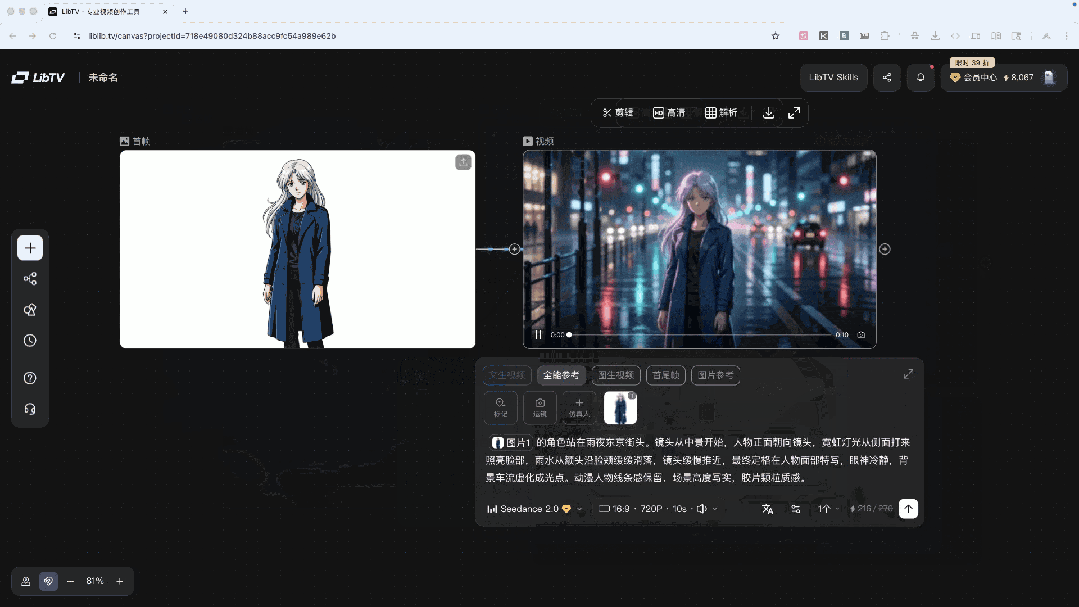
访问 liblib.tv,点击"开始创作"。界面和传统视频编辑器完全不同,是一个无限延伸的画布。

四种模式可选:
选择"首帧生视频",上传动漫角色图,写提示词,选模型(Seedance 2.0)、时长、比例,点击生成。
动漫线条感保留了,背景是写实的霓虹和雨水,没有明显割裂感,光影方向也是对的。
用 AI 生成一个女性角色图,然后用同一张图,生成两条完全不同的视频(雨天咖啡馆 vs 暴风雪山顶)。
![]()
关键发现: 两条视频里,人物的发色、轮廓、五官保持得相当稳定。这意味着你可以真正"签约"一个虚拟角色,让她持续出镜,而不是每期视频都换一张脸。
在画布里完成:从剧本生成脚本、分镜图,再批量生成视频,最后批量下载到剪映剪辑。
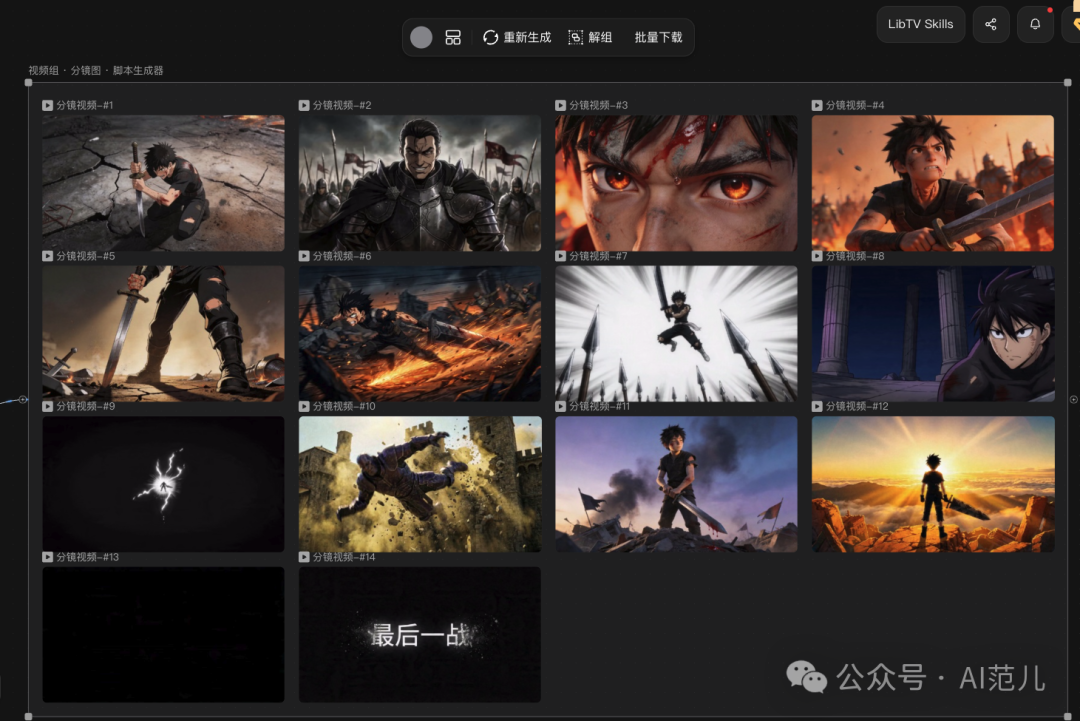
对某个片段不满意,直接在画布里改提示词重新跑。
Seedance 2.0 可以根据音乐卡点和声音来生成视频。操作极简:把图片和音频放一起,连到视频生成节点,写提示词,生成。
![]()
以前做卡点视频要手动一帧一帧对节奏,现在扔进去它自己踩点。
LibTV 的画布设计有几个实用特性:

装了 OpenClaw / AutoClaw 的用户,可以直接在聊天里让 Agent 帮你生成视频:
export LIBTV_ACCESS_KEY="你的访问密钥"![]()
真人授权问题: Seedance 2.0 目前关闭了上传真人照片生成视频的功能,预计 4 月 15 日后会开放,但需要授权确认。测试时建议先用卡通/动漫角色。
审核机制: 跟即梦一样,有些提示词会被直接拒但不告诉你具体哪个词有问题。只能逐字修改反复提交,需要耐心。
分镜时长 bug: 分镜表里定义好的每段视频时长,批量生成时没有被执行,只能选统一长度。
批量生成: 几十条视频批量跑,偶尔有几条提示词违规需要单独改,可能导致情节不连贯。
适合谁:
不适合谁:
核心优势: 不排队 + 画布工作流 + 多模型切换。这三个点组合起来,是目前 AI 视频生成领域最高效的创作体验。不再是"AI 生成素材,人来出片",而是"人说想法,AI 直接出片"。
定价: LibTV 本身注册使用,视频生成消耗对应模型的 API 积分。具体价格以平台为准。
相关链接:

OpenAI 推出 Codex Security 插件,在 Codex 里一键扫描代码漏洞、验证可利用性并给出修复方案,附带完整上手步骤。

阿里巴巴发布 HappyHorse 1.1 视频生成模型,动态表现力、主体一致性等五大维度提升,1080P 价格下调 25%,已上线百炼平台。

豆包专业版 68 / 200 / 500 元三档上线,核心是接入 2.1 Pro 的办公任务模式。这篇拆解定价、额度和值不值。