商汤发布 SenseNova U1 系列多模态模型,原生统一架构实现连续图文创作,免费开源,可作为 GPT Image 2 的国产替代方案

商汤发布 SenseNova U1 系列多模态模型,原生统一架构实现连续图文创作,免费开源,可作为 GPT Image 2 的国产替代方案
GPT Image 2 的文字渲染和排版能力确实强,但 API 按量计费价格不低,国内团队接入也有门槛。商汤最新发布的 SenseNova U1 系列给出了一个开源免费的替代方案,不仅能做信息图,还支持在同一个模型内连续生成图文内容。
SenseNova U1 是商汤发布的采用全新 NEO-Unify 架构的多模态模型。它不是把"理解模型"和"生成模型"拼在一起,而是把图文理解、图文推理和图文生成放进同一套架构里统一处理。
传统多模态方案的痛点在于:语言模型负责理解和推理,视觉编码器负责把图片转成模型能读懂的表示,图像生成部分再把结果转回像素。理解和生成之间需要不断做模态转换,角色一致性很难保证。U1 去掉了传统的视觉编码器(VE)和图像生成中的 VAE,让模型直接从原始像素和文字里学习。
这是最能体现 U1 原生统一架构特征的能力。不是"先写一段话,再配一张图",而是在一个模型内部完成文字和图像的连续生成。这在行业内是首创。
传统图文生成流程是:文本模型先完成文案,再把某些段落交给图像模型生成插图,两个模型之间的衔接往往导致风格不一致。U1 的做法是在一次推理中交替输出文字和图像,保持整体风格统一。

信息图不是简单生成一张好看的图,它要求模型同时处理文字结构、视觉层级、版式布局、图标关系和信息密度。以前 AI 画图最容易翻车的地方恰好就是文字渲染和排版。U1 在这方面做了针对性优化。
这次开源的是 SenseNova U1 Lite 系列,包含两个版本:
| 版本 | 参数 | 定位 |
|---|---|---|
| U1 Lite 8B-MoT | 8B | 轻量级,适合接入工作流 |
| U1 Lite A3B-MoT | A3B | 更大容量,更强能力 |
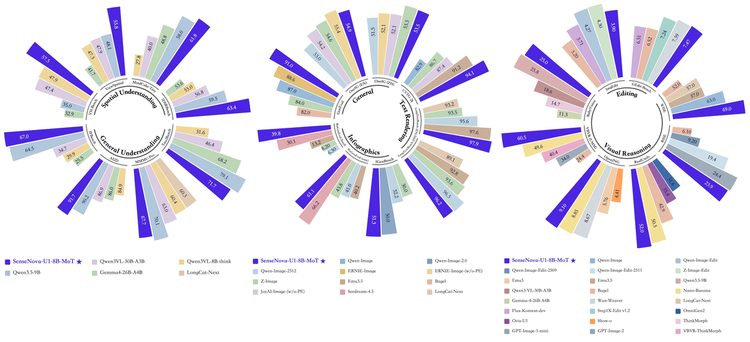
跑分上,U1 Lite 系列均达到同量级开源模型的 SOTA 水平。定位上,它不是要和最大规模的闭源模型硬拼参数,而是做一个"够强、够轻、能开源、能接进工作流"的多模态模型。
提示:信息图生成时建议在 Prompt 中明确指定整体风格、主色调、模块数量和每个模块的具体内容,输出效果会更好。例如:"生成一张深蓝色科技感海报,分四个模块,模块一为三国联合主办(含北美地图),模块二为赛程安排表..."

开源免费的 Codex 实战指南发布,涵盖桌面端安装、手机端远程操控、国内三种接入方案,帮你从零跑通 OpenAI Codex。

从资产准备到剪辑拼接的完整流程,教你用 AI 工具链制作 115 秒品牌广告长视频,解决人脸漂移、场景不统一等核心痛点。

商汤开源的 8B 参数信息图生成模型,Apache 2.0 协议支持商用,文字渲染稳定、版面控制精准,成本约为闭源方案的十分之一。