商汤开源SenseNova U1,采用NEO-Unify原生统一架构,完全去掉视觉编码器和解码器,8B参数挑战更大商业模型的图文生成能力。

商汤开源SenseNova U1,采用NEO-Unify原生统一架构,完全去掉视觉编码器和解码器,8B参数挑战更大商业模型的图文生成能力。
多模态AI模型长期以来都是"拼"出来的:理解用一套视觉编码器,生成用另一套变分自编码器,两套系统的学习目标不同、表示空间各异,信息在模块之间传递时难免损耗。商汤科技最新开源的SenseNova U1,要终结这种缝合时代。
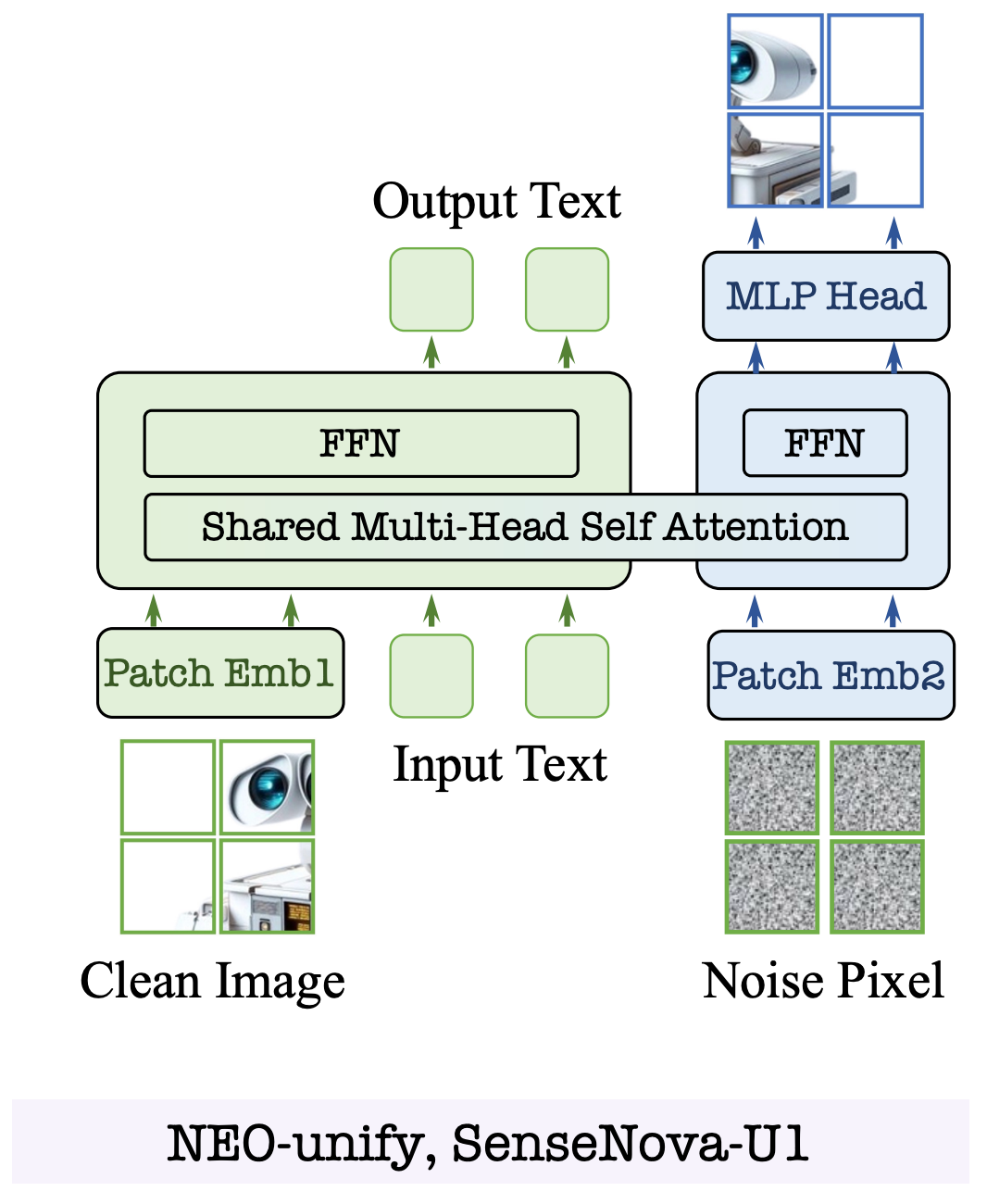
SenseNova U1基于商汤首创的NEO-Unify原生统一架构,让多模态理解、推理与生成在模型内部形成一条完整链路,不再依靠外部模块拼接。
核心特征:完全去掉了预训练视觉编码器(VE)和变分自编码器(VAE)。模型从接近原始形态的信息(像素与文字本身)中学习,在同一个表示空间里统一建模理解与生成。
此次开源的是SenseNova U1 Lite系列,包含两个规格:
| 模型 | 骨干网络 | 参数量 | 激活参数 |
|---|---|---|---|
| SenseNova-U1-8B-MoT | 稠密网络 | 8B | 8B |
| SenseNova-U1-A3B-MoT | MoE网络 | 38B(总参数) | 理解3B + 生成3B |
在Hugging Face和GitHub开源后,海外开发者社区迅速引发讨论。"完全去掉VE和VAE的统一架构"被视为近期多模态领域最值得关注的工程实践之一。
输入端放弃预训练VE,改用两层卷积加GELU激活将图像转化为token(每个token对应32x32像素块)。输出端同样放弃VAE解码器,直接用MLP预测原始像素块。
消融实验数据:NEO-Unify(2B)在MS COCO 2017上的图像重建PSNR达31.56、SSIM达0.85,接近Flux VAE的32.65和0.91。说明近无损输入既能支持语义理解,也能维持像素级精度。
统一架构需要处理从256x256到2048x2048的大跨度动态分辨率。传统方案基于固定噪声先验,分辨率变化时信噪比不一致,高分辨率下易崩坏。
NEO-Unify的解法:分辨率越高,噪声标准差按平方根比例同步上调,保证每个token在不同尺度下承受大致相同的噪声能量。
理解任务需要提取语义,生成任务需要将语义转化为像素,目标不同,直接共享所有参数会产生梯度干扰。
MoT架构让理解流与生成流在底层共享自注意力上下文,但在Q/K/V/O投影、归一化及MLP层进行完全参数解耦,实现"知识共享、专才专用"。
预训练语料约2.1万亿token,涵盖图文对、图注、信息图理解和纯文本。中期训练覆盖通用、Agent与空间、知识推理四大类。SFT阶段覆盖空间智能、多模态理解、推理等十个垂直领域。
累计token数超过3.4万亿,在同类开源统一模型中属于顶量级。
模型完全开源,包含代码、权重和技术报告。
如果你在做多模态应用开发,需要同时处理图像理解和图像生成任务,SenseNova U1的统一架构可以避免"拼两个模型"的工程复杂度。8B参数量在消费级显卡上就有不错的表现,38B MoE版本在激活参数仅3B的情况下能挑战更大的商业闭源模型。


