腾讯混元庞天宇团队开源UniRL,一套框架打通图像、视频、LLM多模态生成模型的强化学习训练,支持SD3、HunyuanVideo、Qwen等主流模型。

腾讯混元庞天宇团队开源UniRL,一套框架打通图像、视频、LLM多模态生成模型的强化学习训练,支持SD3、HunyuanVideo、Qwen等主流模型。
UniRL 是腾讯混元团队(庞天宇团队)开源的多模态生成模型强化学习后训练框架。它解决了一个长期痛点:图像扩散模型一套训练流程、视频生成另一套标准、VLM 和 LLM 又有不同的技术栈。UniRL 把这些全部统一到一套框架里。
多模态生成模型的 RL 训练面临四大挑战:
生成过程不同:LLM 处理离散 token 序列,图像/视频生成对应连续潜空间中的去噪轨迹。统一模型的一次 rollout 还会混合 token 生成与 latent 去噪。
系统闭环难稳定:rollout、log-prob replay 与策略更新跨多个模型和后端,训练侧必须严格复现采样侧的条件、噪声、时间步,否则产生 Training-Inference Mismatch。
奖励系统更重:多模态 reward 往往依赖 VLM、OCR、美学模型、视频理解模型,不是简单的文本规则。
显存压力大:中间产物是高维 latent、噪声、时间步和条件状态,视频生成中随分辨率和帧数快速放大。
这导致行业现状是"一个模型一套训练代码",开发者大量时间浪费在重复的工程实现上。
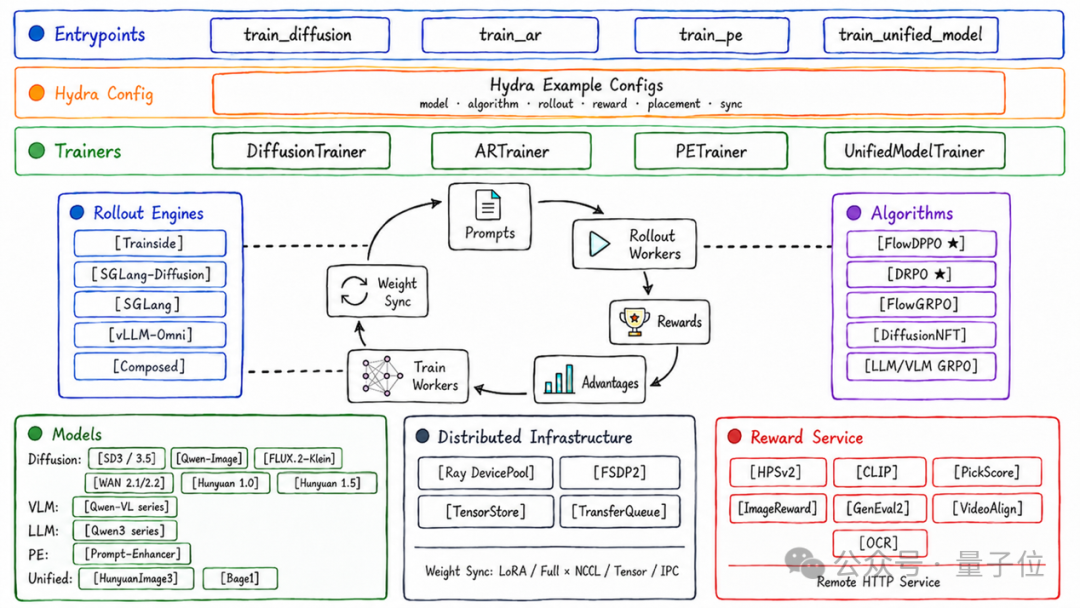
UniRL 统一多模态 RL 闭环:rollout -> reward -> advantage -> train -> weight-sync。
UniRL 提供了业界最广泛的多模态生成模型支持:
| 领域 | 支持模型 |
|---|---|
| 图像生成 | SD3/3.5、Qwen-Image、Z-Image、FLUX.2-Klein |
| 视频生成 | HunyuanVideo 1.0&1.5、WAN 系列 |
| 大语言模型 | Qwen3 系列 |
| 多模态理解 | Qwen-VL 系列 |
| 原生统一模型 | HunyuanImage 3.0、Bagel |
| 组合式模型 | LLM/VLM + Diffusion 的 Prompt-Enhancer |
UniRL 集成了多类常用 reward 组件:
UniRL 以 Ray worker group、Hydra flat recipe、可组合训练后端和可插拔 rollout engine 为核心骨架。它用轨迹(track)表示承载不同阶段的生成轨迹:AR 阶段是 TextSegment,图像生成阶段是 LatentSegment,不同 track 之间通过 parent-child 关系连接。
这使得 Bagel、HunyuanImage 3.0 这类统一多模态模型(先 AR 文本思考、再 DiT 图像生成)的链式流程可以被自然表示。
框架提供了完善的 examples,方便快速启动实验和复现算法。目前仍处于活跃迭代阶段,后续将继续扩展 rollout engine 支持、优化大规模训练性能。

8 万条人类终端录像炼成的 1530 任务评测集,覆盖 18 类工作流、1280 个命令工具,专治 Agent 在真实终端场景里‘榜上高分、落地翻车’的顽疾。

若愚九天机器人大脑驱动的防爆机器人揽月01,在加油站24小时自主完成开盖、取枪、注油、收枪全流程,把具身智能落进高危场景。

开源Agent安全框架TRIAD用三路决策(继续/更新/拒绝)替代二分类护栏,在提示注入攻击下仍能保住用户原本任务。