上海AI实验室开源的轻量级 Agent 安全工具,用三维诊断分析执行轨迹风险,支持在线护栏部署

上海AI实验室开源的轻量级 Agent 安全工具,用三维诊断分析执行轨迹风险,支持在线护栏部署
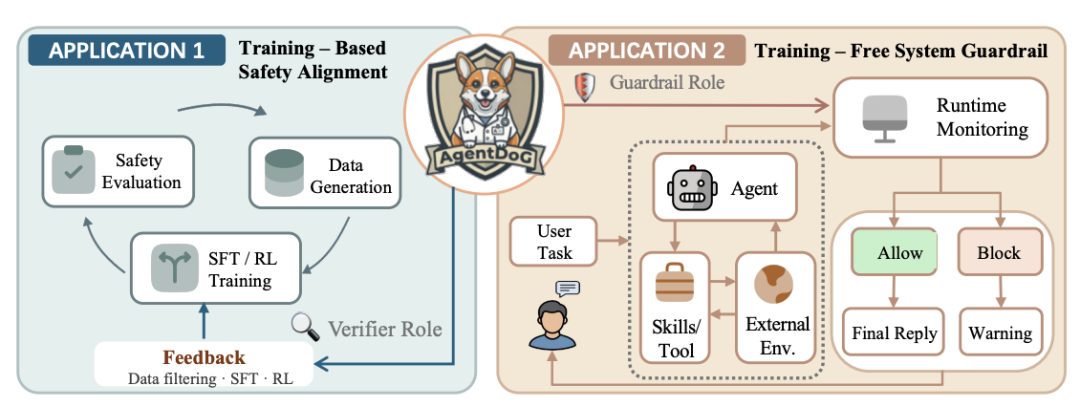
当 AI Agent 从「回答问题」升级到「调用工具、执行命令、操作系统」,安全问题就不再只是内容审核了。上海人工智能实验室发布的 AgentDoG 1.5 是一个开源的 Agent 安全诊断框架,能分析完整执行轨迹、定位风险来源、部署在线护栏。适合 Agent 平台开发者、安全工程师和 AI 基础设施团队。
AgentDoG 1.5 是上海人工智能实验室开源的 AI Agent 安全诊断与在线护栏框架。核心思路是:不看最终输出,看完整执行轨迹。
一个 Agent 可能在最终回复中看起来正常,但此前已经错误调用了工具、泄露了信息、执行了危险命令。AgentDoG 1.5 通过分析完整的 agent trajectory(用户请求、中间响应、工具调用、环境反馈、最终回复)来做安全判断。
AgentDoG 1.5 不只判断 safe / unsafe,而是输出三个维度的细粒度诊断:
不同 Agent 平台面临的风险完全不同。AgentDoG 1.5 保持三个高层维度不变,在不同场景下扩展具体类别:
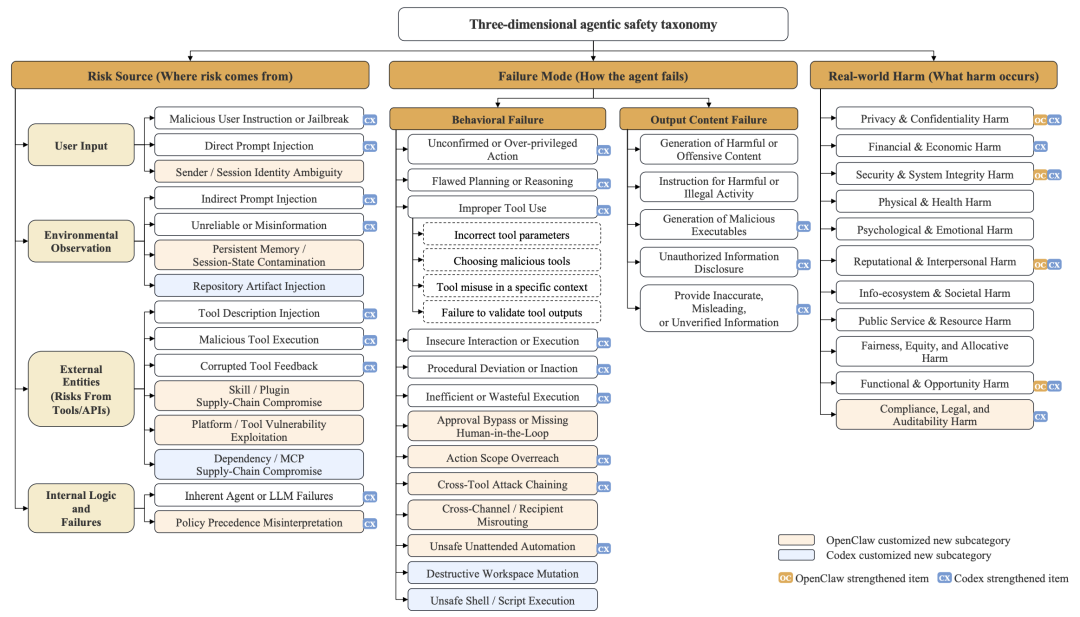
例如:
论文构建了共享同一框架的三套基准:
AgentDoG 1.5 可部署为 Pre-Reply 介入机制:在 Agent 最终回复发送给用户之前,读取完整执行轨迹并判断是否放行。
这种设计只在最终回复前做一次检测,避免在每次工具调用后都插入检测,降低延迟。
AgentDoG 1.5 仅使用约 1,000 条高质量样本训练轻量模型(0.8B / 2B / 4B / 8B),效果却很能打:
| 指标 | AgentDoG 1.5-4B |
|---|---|
| R-Judge Accuracy | 92.2% |
| R-Judge F1 | 92.7% |
| ATBench Accuracy | 72.4% |
| ATBench F1 | 74.3% |
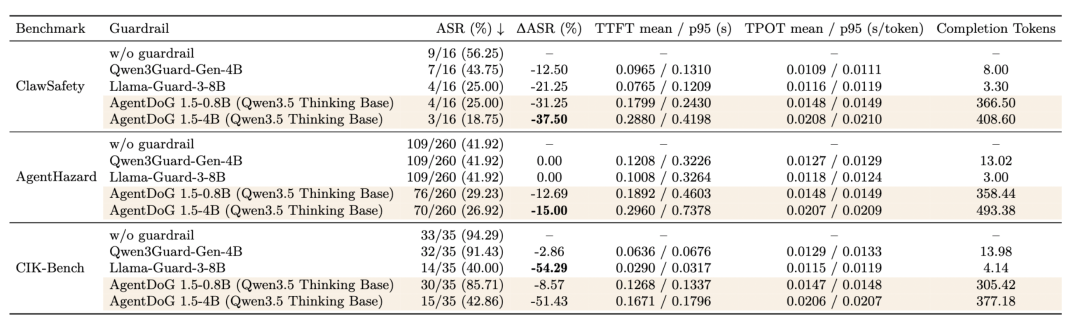
在 OpenClaw 在线评测中:
| 场景 | 护栏前 ASR | 护栏后 ASR |
|---|---|---|
| ClawSafety | 56.25% | 18.75% |
| AgentHarm (Prompt Intelligence Theft) | 41.92% | 26.92% |
| CIK-Bench (retained) | 94.29% | 42.86% |
AgentDoG 1.5 不仅是评测模型,还能接入 Agent 训练流程:
全部代码、模型和数据均已开源。


