南大快手联合提出CodeTracer框架,无需重训即可自动定位Coding Agent失败节点,F1分数比基线提升近30个百分点。

南大快手联合提出CodeTracer框架,无需重训即可自动定位Coding Agent失败节点,F1分数比基线提升近30个百分点。
当AI代码Agent执行任务失败时,你往往不知道它在哪一步出了错。现有评测只看最终的成功或失败,对过程中每一步决策的对错一无所知。CodeTracer解决了这个问题——它是一个无需重新训练的轨迹追溯框架,能自动定位Agent的失败节点并将诊断信息反馈回去。
随着SWE-Agent、OpenHands等代码Agent的能力越来越强,执行轨迹也愈发冗长——一次完整流程往往包含数百至上千个步骤。当Agent失败时,开发者面临三个核心痛点:
整个框架由三个紧密协作的核心模块组成:
不同Agent框架的日志格式互不兼容。CodeTracer的策略是"探索-适配-复用":先自动扫描运行目录识别日志结构,然后在注册表中查找匹配的解析器。若无匹配项,自动生成新解析器并注册入库,供后续同类格式复用。

将扁平的执行序列转化为层级轨迹状态树,区分两类步骤:
每个节点附加意图与结果摘要,整棵树成为压缩版的导航索引。
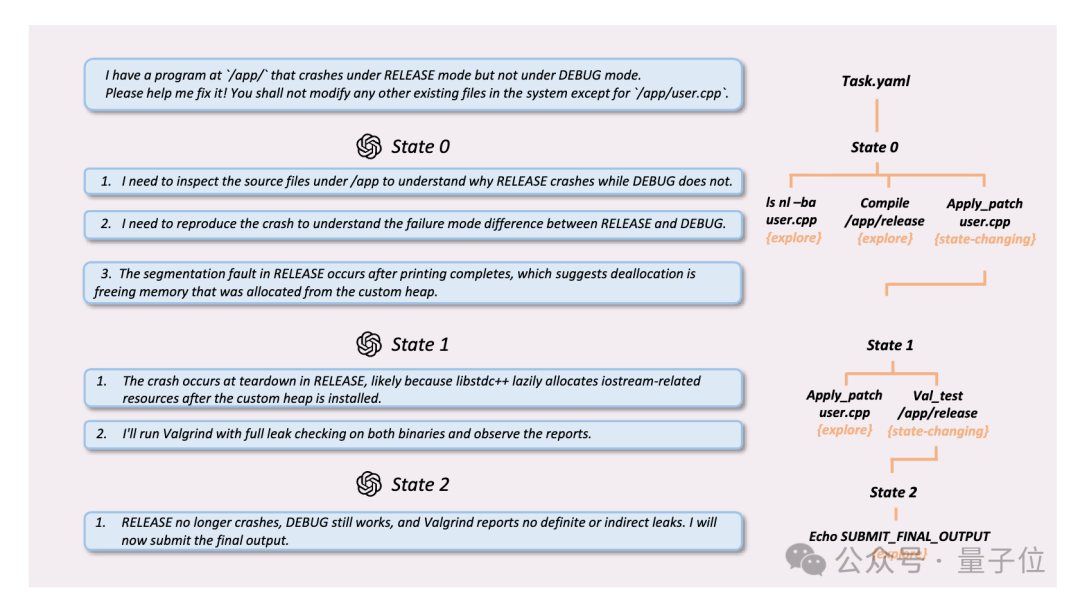
Trace Agent沿轨迹树遍历检索,输出三项诊断结果:
诊断信号可作为前置提示注入原Agent,驱动其在相同资源约束下重新执行——即"反思回放"机制。诊断消耗的Token不计入回放预算,保证对比公平。
对SWE-Agent、MiniSWE-Agent、OpenHands、Terminus 2四大框架的测试显示:过度复杂的编排设计只带来更长执行链和更高Token成本,却无法带来能力突破。决定成功率上限的核心是底层模型的推理能力。
从5到300次迭代的全面扫描显示:迭代至约35%-40%最长长度时成功率快速上升,中后期曲线趋于饱和。当Agent早期就形成错误假设时,额外迭代只会空耗资源。
失败轨迹中无效步骤占比约40%,接近成功轨迹(22%)的两倍。这说明Agent失败并非找不到关键信息,而是无法将有效证据转化为正确决策。
在CodeTraceBench上的测试结果:
不同模型的诊断风格:

用 Pi 智能体框架配合 LM Studio 推理引擎,在本地 Mac 上跑 Gemma 4 完成 Agent 编码任务,附完整 Docker 配置和 models.json 示例。

清华微软联合开源的多智能体推理框架,通过 Reasoner、Verifier、Meta-Strategist 三个角色让长程推理可验证可回溯,Apex 基准超 GPT-5.5 达 13.5%。

百度基于 DeepSeek OCR 推出的 Unlimited OCR,通过 R-SWA 机制实现 32K 上下文长程解析,OmniDocBench v1.5 端到端 SOTA 达 93.23%。