DeepSeek-V4与GPT-5.5同一天发布,开源对闭源的正面硬刚。推理、编程、长文本实测对比,帮你快速判断该用哪个。

DeepSeek-V4与GPT-5.5同一天发布,开源对闭源的正面硬刚。推理、编程、长文本实测对比,帮你快速判断该用哪个。
2026年4月24日,AI圈迎来了一个"疯狂星期五"——GPT-5.5和DeepSeek-V4在同一天发布。一个是闭源巨头的新一代预训练模型,一个是开源领域的效率革命者。这篇实测帮你快速判断:该用哪个。
| 参数 | DeepSeek-V4 Pro | DeepSeek-V4 Flash | GPT-5.5 |
|---|---|---|---|
| 参数量 | 1.6万亿 (MoE) | 2840亿 | 未公开 |
| 激活参数 | 49B | 13B | 未公开 |
| 上下文窗口 | 1M token | 1M token | 128K+ |
| 开源 | 是 | 是 | 否 |
| 价格 | 极低(开源) | 极低(开源) | 比GPT-5.4更高 |
V4最大的突破不是参数规模,而是效率。在100万token上下文下:

这意味着同样的硬件能处理多得多的请求,同样长度的文本花的钱少得多。
另外,V4完成了对华为昇腾芯片的深度适配,从英伟达CUDA生态向华为CANN架构做了底层代码迁移。API价格页面有一行小字:"受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。"
GPT-5.5建立在一次全新的预训练之上。这不是在旧模型上做微调,而是换了基础模型。
关键数据:
在Artificial Analysis指数的成本性能前沿上,GPT-5.5系列占据绝对主导地位。
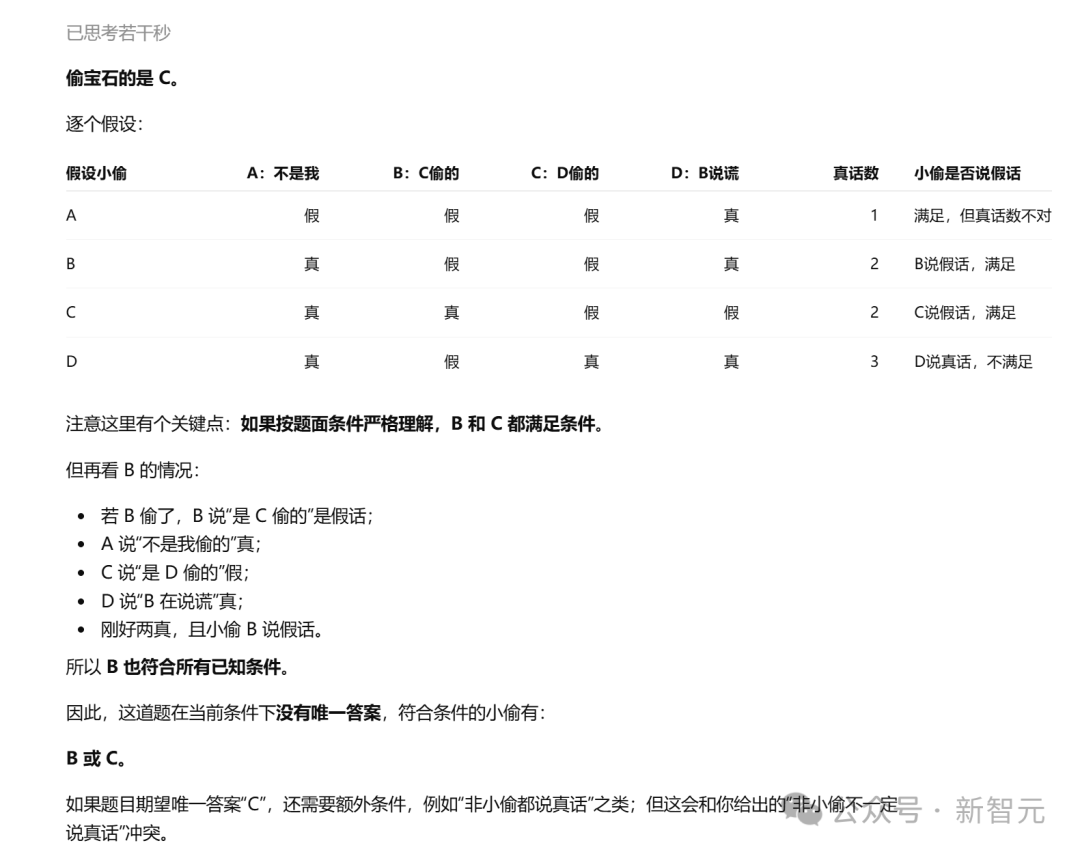
一道电梯谜题测试"真假话+身份推理"——有四个人只有一个人偷了宝石,四句话中恰好两句为真。关键在于:这道题的条件不充分,B和C都可能是小偷。
DeepSeek V4在agentic编程能力上是开源模型里最强的。实测中:
GPT-5.5在编程方面表现同样亮眼:
DeepSeek-V4的1M上下文(约能装三部《三体》)是它的绝对优势领域。在这个长度下,V4-Pro的推理算力只有V3.2的27%,这意味着它把百万token长文本的门槛踩到了地板上。
| 你的需求 | 推荐模型 |
|---|---|
| 成本敏感、需要本地部署 | DeepSeek-V4(开源免费) |
| 超长文本处理 | DeepSeek-V4(1M上下文) |
| 速度优先的复杂推理 | GPT-5.5 |
| 自主编程项目 | GPT-5.5(自主性更强) |
| 需要模型可微调 | DeepSeek-V4(开源权重) |
| Agent批量部署 | DeepSeek-V4(成本极低) |
沃顿商学院教授Ethan Mollick测试后的结论是:目前GPT-5.5 Pro是解决复杂问题的最佳模型。但DeepSeek-V4用开源和极低成本,把大模型能力推到了"平民化"的水平。
两个模型的发布在同一天完成,但走的是两条完全不同的路线——一个卷智能上限,一个卷效率极限。

Anthropic发布Mythos级旗舰模型,Fable 5面向所有用户开放,软件工程基准SWE-bench Pro拿下80.3%,定价输入10美元/百万token。

阿里千问上线国内首个全周期高考志愿填报Agent,面向1290万考生免费开放,提供志愿报告、志愿日历、志愿问答三项核心能力,40万AI考生提前压测。

美团Tabbit 1.0正式版发布,内置Agent能力支持网页自动化、妙招工作流和智能代理,标准版永久免费,可调用DeepSeek-V4-Pro、Kimi-K2.6等国产大模型。