GLM-5.2 作为首个进入新御三家的中国开源模型,1M长上下文与Coding能力接近闭源旗舰水平,MIT协议可直接使用。

GLM-5.2 作为首个进入新御三家的中国开源模型,1M长上下文与Coding能力接近闭源旗舰水平,MIT协议可直接使用。
GLM-5.2 是智谱 AI 发布的开源大模型,MIT 协议,在 Code Arena 排行榜上排名第一。它是首个进入 AI 编程"御三家"的中国模型。价格是 Opus 和 GPT 的零头,Coding Plan 直接能跑。我们通过两道真实任务来看看它到底什么水平。
测试者把攒了大半年的 60 多个自建 Skill 甩给三个模型,要求它们读取所有 Skill、画出系统架构、找出冲突和重复部分,最后生成一个 HTML 看板。

| 指标 | Opus 4.8 | GLM-5.2 | Codex (GPT) |
|---|---|---|---|
| 上下文峰值 | 34.1万 / 1M | 22.7万 / 1M | 15.7万 / 25.8万 |
| 覆盖 Skill 数 | 34 | 64(最多) | 61 |
| 找出冲突 | 9 组 | 9 对 | 31 对 |
| 读取策略 | 全塞进单一上下文 | 直读40个+子代理摘要其余 | 分批抽取 |
GLM-5.2 覆盖了最多的 64 个 Skill,还挖出了一个其他两个模型都没发现的 bug。值得注意的是,Codex 受限于 258K 上下文窗口,自己承认做了取巧处理。
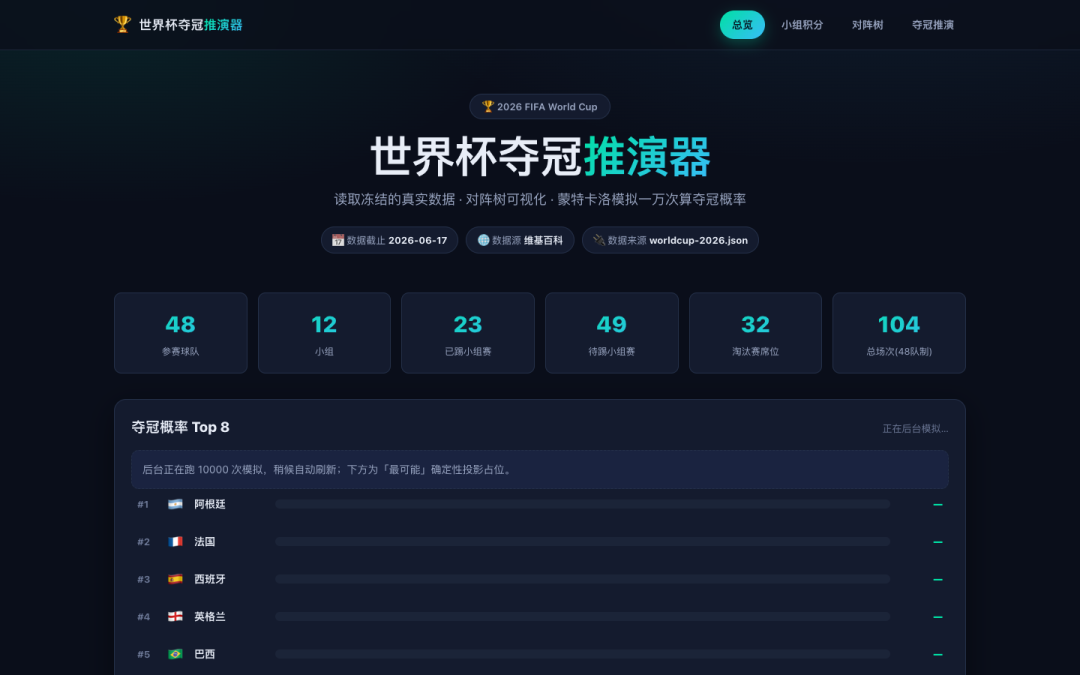
给三个模型同样的世界杯数据和任务:做一个夺冠推演器网站,淘汰赛对阵树 SVG 画,蒙特卡洛模拟跑一万次算夺冠概率。
| 维度 | Opus 4.8 | GLM-5.2 | Codex |
|---|---|---|---|
| 五维总分 | 96 | 91 | 82 |
| 淘汰赛赛制 | 正确 32 强 | 正确 32 强 | 偷懒做了 16 强 |
| 上下文峰值 | 20.2万 / 1M | 7.2万 / 1M | 9.1万 / 258k |
| 自我验证 | 自开浏览器测+修2个bug | Node 逻辑测试 | 浏览器自测 |
| 设计观感 | 暗色最精致 | 暗色干净克制 | 浅色 |
GLM-5.2 生成的推演器是暗色配青绿风格,干净克制。32 强赛制正确,胜者高亮带比分、败者灰掉。蒙特卡洛 0.34 秒跑完一万次。H 组四队全 1 分时,能按净胜球正确排序——tiebreaker 写对了。
它比 Opus 差在哪?没配国旗、对阵树没连接线、概率条要手动点一下才出。但它只吃了 7.2 万 token——Opus 的三分之一,同样的活最省。
GPT 和 GLM-5.2 的预测比较接近(阿根廷约 25%),Opus 只给了 17%。
GLM-5.2 可通过以下方式使用:

全球最大开源AI Agent项目发布重大更新:Windows原生接入、技能工坊让Agent自我进化、多Agent工作板协同,16亿台PC变算力节点。

阶跃星辰新模型输出速度达409 tokens/s,单任务成本为Claude Opus 4.6的1/9,编程能力达其97%,专为Agent高频调用场景设计。

开源AI Agent框架OpenSquilla 3.0推出MetaSkill,用自然语言自动合成多步骤工作流,搭配智能模型路由降低使用成本。