GPT-5.5 正式发布,Terminal-Bench 82.7% 夺冠,1M 上下文翻倍提升,Codex 搭配 gpt-image-2 开启图像驱动开发新工作流

GPT-5.5 正式发布,Terminal-Bench 82.7% 夺冠,1M 上下文翻倍提升,Codex 搭配 gpt-image-2 开启图像驱动开发新工作流
2026年4月24日,OpenAI 正式发布 GPT-5.5。这不是一次简单的模型迭代 -- 它在 Agent 编程、百万级上下文处理和知识工作三大维度同时拉开代际差距。对开发者和内容创作者来说,最值得关注的不是跑分数字,而是它如何改变你日常的工作流。
GPT-5.5 的核心定位是面向 Agent 任务的新型智能,不只是更聪明的聊天机器人,而是能把复杂任务推进到底的执行引擎。
关键评测数据对比:
| Benchmark | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 |
|---|---|---|---|---|
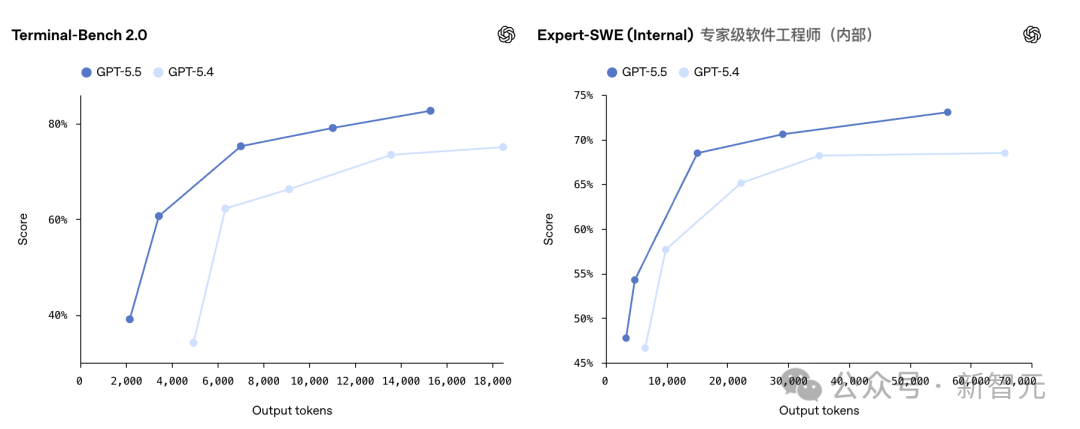
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| Expert-SWE | 73.1% | 68.5% | -- | -- |
| GDPval(知识工作) | 84.9% | 83.0% | 80.3% | 67.3% |
Terminal-Bench 2.0 测试的是全链路 Agent 能力 -- 给模型一个终端环境和一个模糊目标,让它自己规划路径、调工具、写脚本、处理报错、反复迭代。GPT-5.5 在这个维度领先 Opus 4.7 超过 13 个百分点。
注意:SWE-Bench Pro 中 Claude Opus 4.7 得分 64.3%,高于 GPT-5.5 的 58.6%。但 OpenAI 和 Anthropic 均承认该数据存在记忆污染(memorization)问题,横向对比需谨慎。
这是 GPT-5.5 进步最夸张的维度。
MRCR v2 测试 512K 到 1M 超长上下文:
Graphwalks BFS(超长上下文图遍历):GPT-5.5 是 45.4%,GPT-5.4 只有 9.4%,整整五倍提升。
过去两年超长上下文一直是 Gemini 的护城河。GPT-5.5 首次把 1M 窗口的实用性拉到了可用的水平。
GPT-5.5 上线后,Codex IDE 内置的图像生成切到了 gpt-image-2,支持 $imagegen 指令直接生成或修改 UI 素材、布局、sprite sheet。
这带来了全新的开发工作流:图像作为中间工件驱动代码生成。
实际操作流程:
有用户实测 12 分钟内从参考图到一套完整 UI 界面。
gpt-image-2 的关键突破是基本解决了 AI 画图中"文字渲染"的老大难问题,使得生成的 UI 参考图可以直接用于开发流程。
GPT-5.5 驱动的 Codex 分析了生产流量数据,用自适应分区算法替换了固定分块策略,token 生成速度提升超过 20%。
最终效果:GPT-5.5 的逐 token 延迟和 GPT-5.4 相当,但完成同类 Codex 任务消耗的 token 更少。更强但不更慢,靠的是让模型本身参与优化运行自己的基础设施。
GPT-5.5 已在 ChatGPT 和 Codex 中正式上线。API 定价与 GPT-5.4 保持同一档位,且由于 token 消耗降低,实际使用成本反而可能下降。
适合以下场景的开发者优先尝试:

社区作者耗时 7 天整理的开源 WorkBuddy 实战蓝皮书(GitHub: AlephAITech/WorkBuddyGuide,MIT),覆盖教程、Skills、MCP、自动化和多智能体实践。本文帮你快速找到自己需要的章节。

登顶 Product Hunt 周榜的 AnySearch 不是一个搜索框,而是给 AI Agent 喂“已过滤、去重、结构化”信息的统一 API。本文拆解它的定位、接入方式与为什么能省 Token。

Anthropic 发布 Claude Sonnet 5,默认开启自适应思考、引入新分词器,定价维持 $3/$15,8月31日前享 $2/$10 限时价。