阶跃星辰发布新一代语音识别模型,推理速度提升 400%,支持 30 分钟音频一次性转写,定价仅为上代的 1/10

阶跃星辰发布新一代语音识别模型,推理速度提升 400%,支持 30 分钟音频一次性转写,定价仅为上代的 1/10
OpenResearcher 提供完整开源的深度研究轨迹合成流水线,9.7 万条长程训练数据免费可用,微调后 30B 模型在 BrowseComp-Plus 达到 54.8% 准确率,超越多个主流闭源模型。
如果你经常需要把会议录音、课程视频、采访素材转成文字,阶跃星辰刚发布的 StepAudio 2.5 ASR 值得关注。它的核心卖点很简单:快、便宜、准。推理速度比上代提升 400%,5 分钟音频几乎"一眨眼"就能转完,定价 0.15 元/小时 -- 只有上一代的 1/10。
StepAudio 2.5 ASR 是阶跃星辰发布的自动语音识别模型,基于 Audio Encoder + Linear Adapter + LLM + MTP-5 融合架构,将大语言模型的推理加速技术(Multi-Token Prediction)引入了语音识别领域。
核心参数:
| 指标 | 数据 |
|---|---|
| 推理峰值 | 500 tokens/s |
| 速度提升 | 约 400%(vs 上代) |
| 时延降低 | 60% |
| 成本下降 | 80% |
| 最长一次性转写 | 30 分钟 |
| 定价 | 0.15 元/小时 |
| 支持语言 | 中文、英文、中英混合 |
| 音频格式 | WAV、MP3、OGG、PCM |
传统方案需要把长音频切片、分段识别、后期拼接,切割后的片段互相独立,容易造成上下文割裂和语义断层。
StepAudio 2.5 ASR 复用 LLM 原生 32K 上下文窗口,支持端到端一次性处理最长 30 分钟的连续音频,无需分段切割,全程保留完整上下文关联。
实测中对中英混杂的日常表达、绕口令等发音紧凑场景都能稳定识别,口语中的自然重复和口头复述特征也会被完整保留。
官方数据显示推理效率高于 Qwen3 ASR(1.7B)、FunASR-Nano、Doubao-ASR-2603 等同类模型。
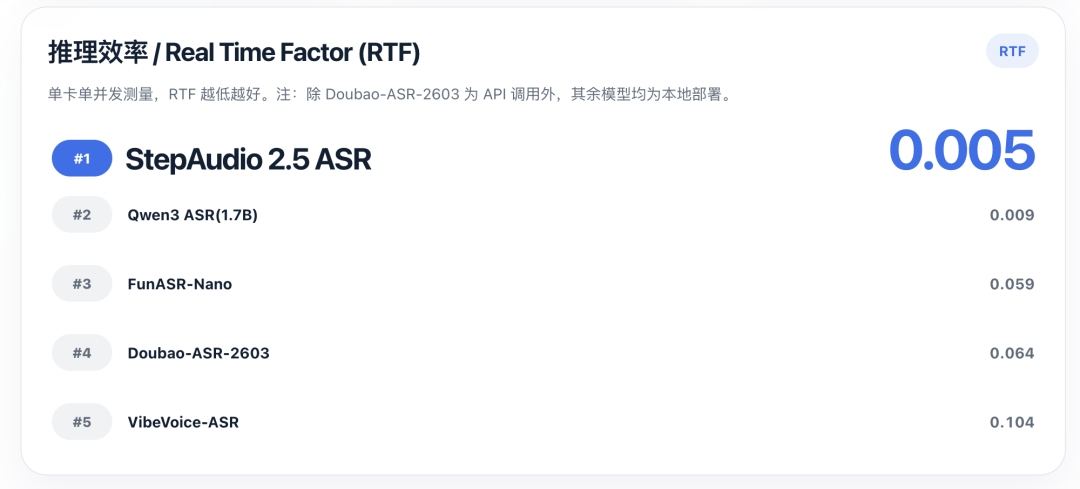
在大段连续口述场景下,模型能实现长时间连贯输出,识别过程中文本还原稳定、语义完整,长音频转写质量均衡。
实测者选取了不同类型的音频进行测试:
实时录音模式(适合语音备忘、现场会议纪要):
文件上传模式(适合课程录音、采访转写):
提示:实时录音场景下表现更稳定。如果文件上传失败,可以尝试先用其他工具转换音频格式后再上传。
| 场景 | 说明 |
|---|---|
| 会议纪要 | 30 分钟内会议一次性转写 |
| 采访录音转写 | 保留完整上下文,不会丢失语义 |
| 课程内容归档 | 5 分钟课程"秒级"转写 |
| 语音备忘 | 实时录音转写,2 分钟内快速记录 |
| 客服录音质检 | 中英混合识别,成本极低 |
0.15 元/小时,是上代 Step ASR 2(1.5 元/小时)的 1/10。
这个价格意味着:转写一场 2 小时的会议只要 0.3 元,一个月每天开 2 小时会也只要不到 10 元。


