MiniMax M3 是国内首个同时支持 1M 上下文、原生多模态和 Coding 的开源模型,SWE-Bench Pro 达 59%,实测表现亮眼。

MiniMax M3 是国内首个同时支持 1M 上下文、原生多模态和 Coding 的开源模型,SWE-Bench Pro 达 59%,实测表现亮眼。
MiniMax M3 是国内第一个把三件事同时做到的开源模型:1M 上下文、原生多模态、Coding Agent。在此之前,能同时跑通这三件事的只有 GPT、Claude、Gemini 的最新旗舰,而且全是闭源的。M3 的出现撕开了这个口子。
MiniMax M3 是 MiniMax 公司发布的旗舰开源模型,支持:
搭配模型发布的还有 MiniMax Code,这是专为 M3 设计的 Harness,对标 Claude Code。
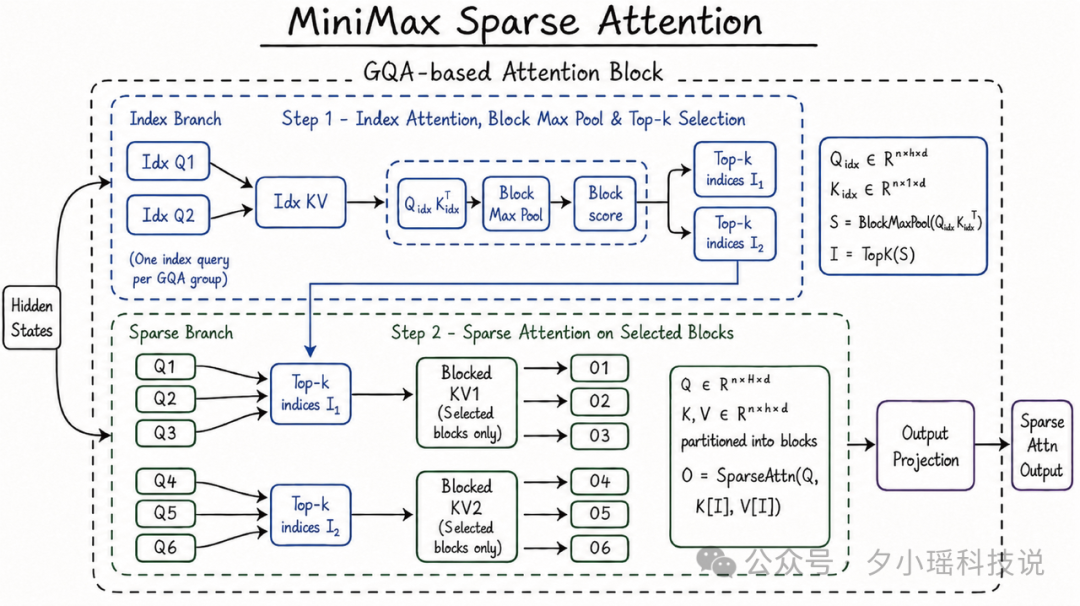
M3 能做到 1M 上下文的关键,是一种新的注意力机制 -- MiniMax Sparse Attention(MSA)。
传统注意力机制下,每读一个字都要跟前面所有字比对一次。读到第 100 万个字,就要比对 100 万次,字数翻倍计算量翻四倍。
MSA 的做法是以 KV 块为外层循环,让每块只读一次、访存连续。实测效果:
把一个包含视频、图片、文档的素材包丢给接了 M3 的 Claude Code,只说一句"参考这些素材,做一个企业官网的展示页"。M3 自己读素材、写代码、本地测试、部署。中间服务器环境脏导致 404,它也自己查到路径问题并修复。16 分钟交付成品。
把一个 PPT 教学视频直接发给 MiniMax Code,只说"看下这个视频,教我"。M3 把视频里的动作扒成文字版 SOP,连"合并形状得先选矩形、再按住 Shift 选文字,顺序反了效果就不对"这种细节都抠出来了。进一步让它直接做好 PPT,半小时交付。
把一篇 ICLR 2025 Outstanding Paper Award 论文丢给 M3,让它从零复现。M3 自主运行接近 12 小时,产出 18 次 commit、23 张实验图,跑通了核心实验,观测到了论文讨论的挤压效应并验证了缓解方法。
MiniMax M3 已上线,可通过以下方式使用:
| 维度 | MiniMax M3 | Claude Opus | GPT-5.5 |
|---|---|---|---|
| 1M 上下文 | 支持 | 支持 | 支持 |
| 原生多模态 | 支持 | 支持 | 支持 |
| Coding Agent | 59% (SWE-Bench Pro) | 接近 Opus 4.7 | 低于 M3 |
| 开源 | 是 | 否 | 否 |
M3 作为开源模型,在综合能力和使用成本的性价比上已经站得住脚。对于需要长上下文 + 多模态 + Coding 三合一能力的开发者,M3 是目前开源生态中唯一的选择。

GPT Image 2 疑似整合 GPT-4o,用 LLM 主导语义规划、扩散模型负责像素生成,实现文字准确渲染和多轮编辑一致性,代表了图像生成的新范式。

OpenAI 和 Anthropic 官方提示词指南核心要点:用结果定义任务而非步骤,删掉多余绝对词,定义停止条件,让新模型发挥最大能力。

Hermes 三层记忆架构解决 Agent 记不住的问题,四阶段提示词搭建 Lead + VOC + GEO + Reddit + TikTok 五人 AI 团队,接入飞书群自动协作。