英伟达推出开源多模态推理模型,融合文本、视觉、语音,吞吐量达同类9倍,免费可用,支持本地至云端全场景部署

英伟达推出开源多模态推理模型,融合文本、视觉、语音,吞吐量达同类9倍,免费可用,支持本地至云端全场景部署
英伟达推出Nemotron 3 Nano Omni,一个在单一模型体系内融合文本、视觉、语音三大模态的开源推理模型。它的核心卖点是:吞吐量达到同类开放多模态模型的9倍,而且完全免费。如果你需要一个能同时处理视频、音频、文档、图片的轻量级模型,这个值得试一试。
Nemotron 3 Nano Omni可以处理以下输入类型:
模型以文本形式输出。它可以根据不同任务与模态动态激活专家网络(MoE架构),在保证高吞吐的同时实现强多模态感知。
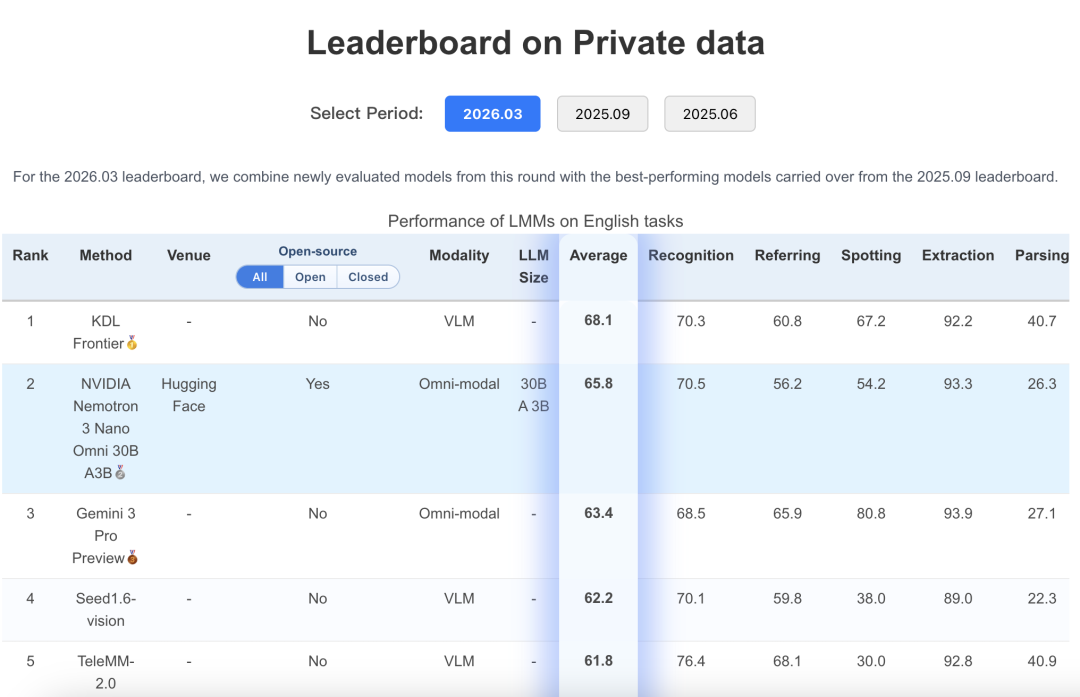
吞吐量是同类9倍
这得益于混合型MoE核心架构,创新性地将Mamba层与Transformer层深度融合。Mamba层负责提升序列处理效率与内存利用率,Transformer层保障精准的推理计算。整体内存和计算效率最高提升4倍。
在视频推理场景中,与替代的开放式全向模型相比,有效系统容量提高约9.2倍。在多文档推理中,提高约7.4倍。
基准测试成绩亮眼
根据海外用户实测:
Google在Android Show上发布Magic Pointer,让鼠标光标拥有视觉理解能力,指着屏幕说'把这个移到那里'就能操作,告别复杂提示词。
免费在线体验:
开源地址:
部署方式:
支持本地系统、数据中心和云环境部署,以满足监管、主权或数据本地化要求。
目前市场上暂无竞品同时具备以下全部特性:
对比来看:谷歌端侧模型Gemini Nano未开源,Meta Llama多模态版本无法在统一架构内整合音频处理能力。Nemotron 3 Nano Omni填补了这个空白。


