小米开源MiMo-V2.5和MiMo-V2.5-Pro两大模型,支持1M上下文、Token效率行业领先,附100万亿Token免费计划

小米开源MiMo-V2.5和MiMo-V2.5-Pro两大模型,支持1M上下文、Token效率行业领先,附100万亿Token免费计划
小米正式开源 MiMo-V2.5 系列模型,包含 MiMo-V2.5(310B/15B 激活,全模态基座)和 MiMo-V2.5-Pro(1.02T/42B 激活,旗舰 Agent)两大模型,采用宽松的 MIT 协议,支持商用部署和二次训练,无需额外授权。
这是小米大模型团队(罗福莉带队)4 个月交出的答卷。两个模型定位明确:
全系标配 1M 上下文窗口,并配套 TTS 语音合成和 ASR 语音识别模型,形成完整的「Agent 全家桶」。
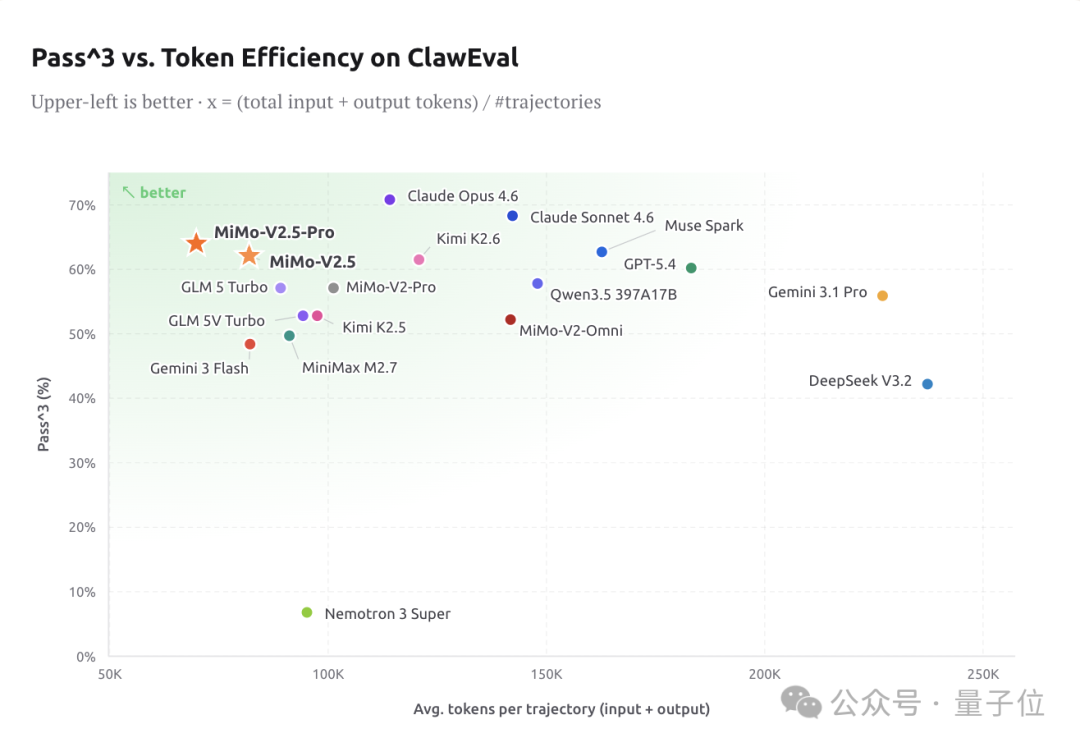
在 ClawEval 标准 Agent 任务中,MiMo-V2.5-Pro 单轨迹只用约 7 万 Token 就能达到 64% 的 Pass^3 通过率。而 Claude Opus 4.6、Gemini 3.1 Pro、GPT-5.4 普遍需要 12-18 万 Token。同样的效果,MiMo 直接省了 40%-60% 的成本。
官方展示的几个实测案例:
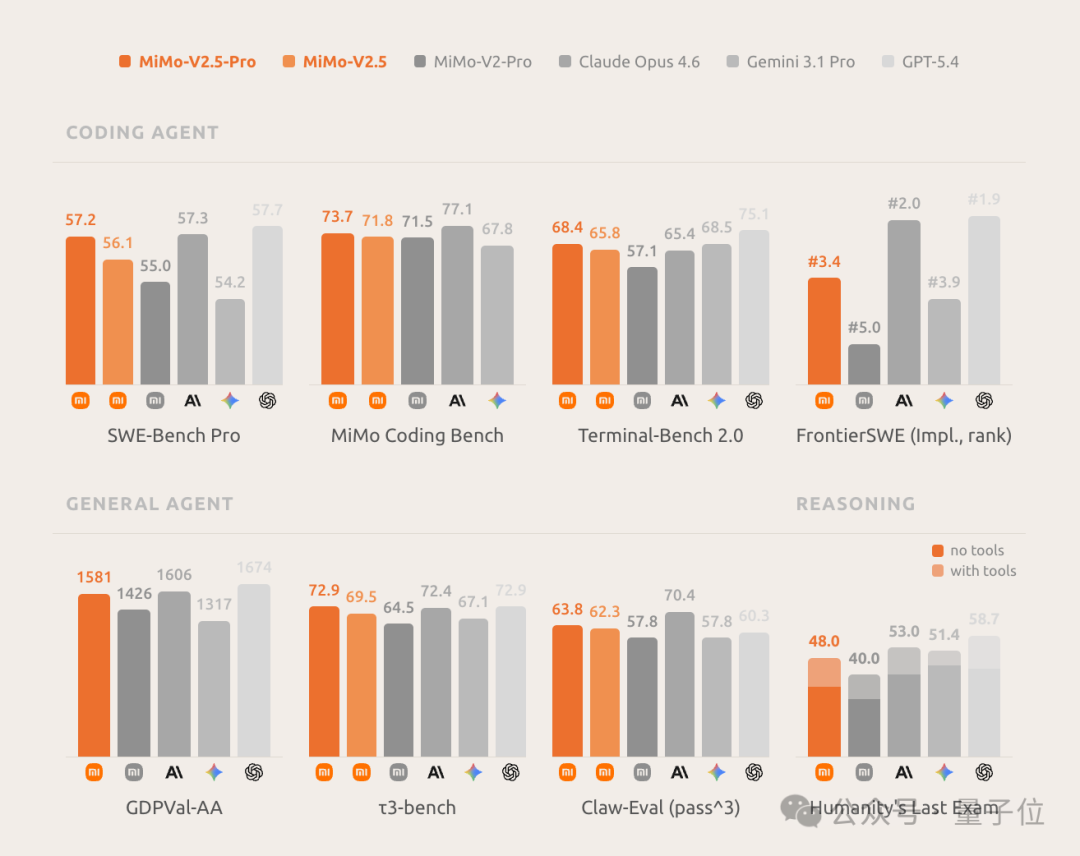
在 GDPVal-AA(Elo)、SWE-Bench Pro、Claw-Eval 等基准测试中,MiMo-V2.5-Pro 成绩逼近 Claude Opus 4.6 和 GPT-5.4,超越 DeepSeek-V4-Pro 和 Kimi K2.6。
MiMo-V2.5-Pro 在 256K 上下文内,缓存未命中时每百万输入 Token 价格为 1 美元,输出为 3 美元。256K-1M 区间价格翻倍。
更重要的是,小米推出了 100 万亿免费 Token 创造者激励计划,30 天内免费发放,面向全球开发者。申请地址:https://100t.xiaomimimo.com/
开源首日已完成 7 家芯片厂商适配:阿里平头哥、亚马逊云科技(Trainium2)、AMD、百度昆仑芯、燧原科技、沐曦、天数智芯。推理框架方面完成 SGLang 和 vLLM 的 Day 0 适配。


