8B参数开源多模态模型,砍掉视觉编码器和VAE,支持信息图生成、连续图文交错输出,本地可部署,性能直逼GPT-Image-2

8B参数开源多模态模型,砍掉视觉编码器和VAE,支持信息图生成、连续图文交错输出,本地可部署,性能直逼GPT-Image-2
商汤SenseNova U1是本周开源社区最值得关注的多模态模型。它只有8B参数,却做到了开源同量级的SOTA水平,部分指标接近闭源商业模型。更重要的是,它采用全新的NEO-Unify架构,直接砍掉了视觉编码器(VE)和变分自编码器(VAE),让模型原生统一"看图"和"生图"两件事。对于需要本地部署、批量出图、或把多模态能力嵌入自己产品的开发者来说,U1提供了一条GPT-Image-2无法提供的路。
SenseNova U1有两个版本:8B的dense版本和A3B的MoE版本,都已开源(Apache 2.0)。
它的核心亮点有三个:
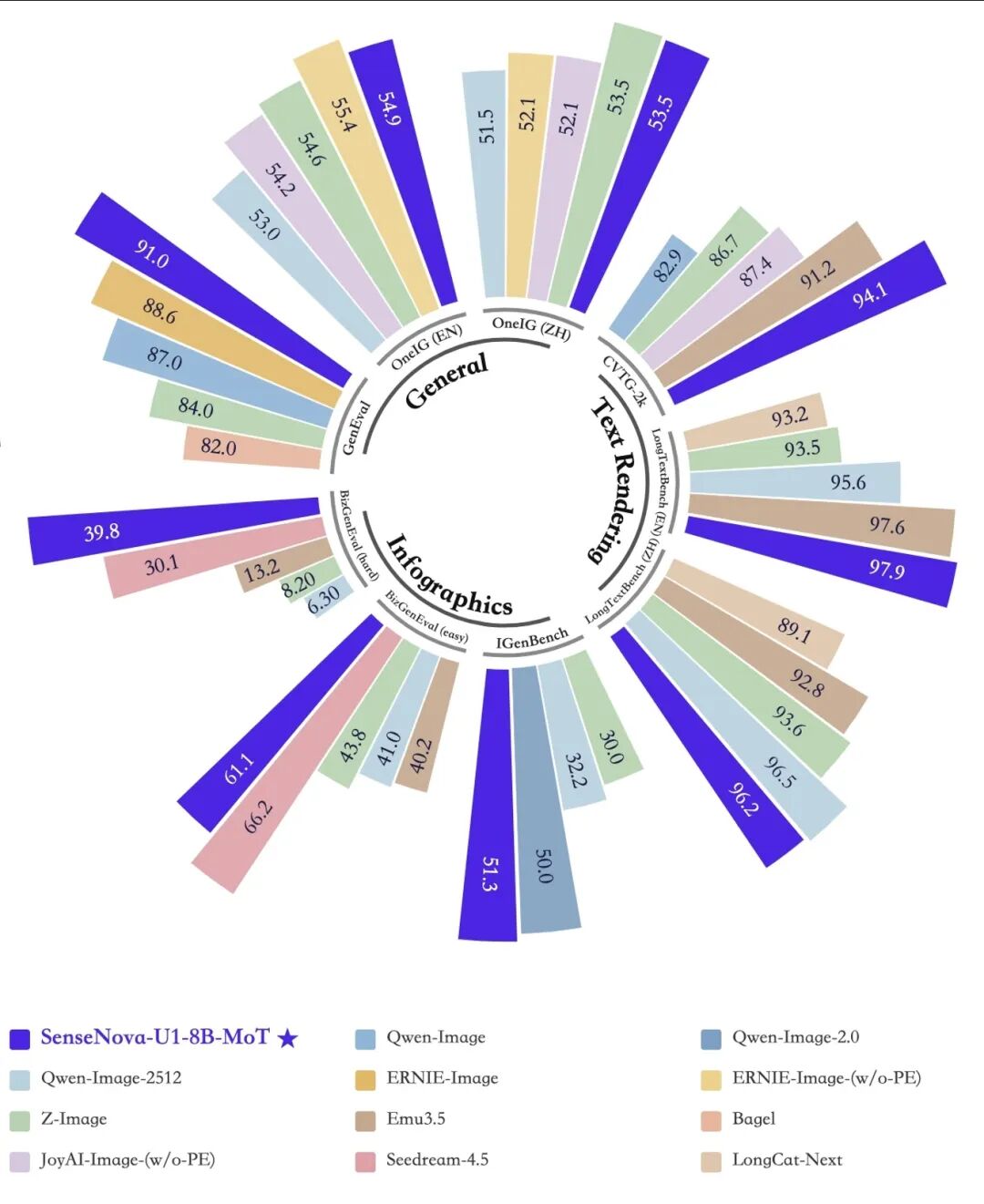
U1在信息图生成基准上的得分与Qwen-Image 2.0、Seedream 4.5等大模型基本持平,但延迟显著更低。
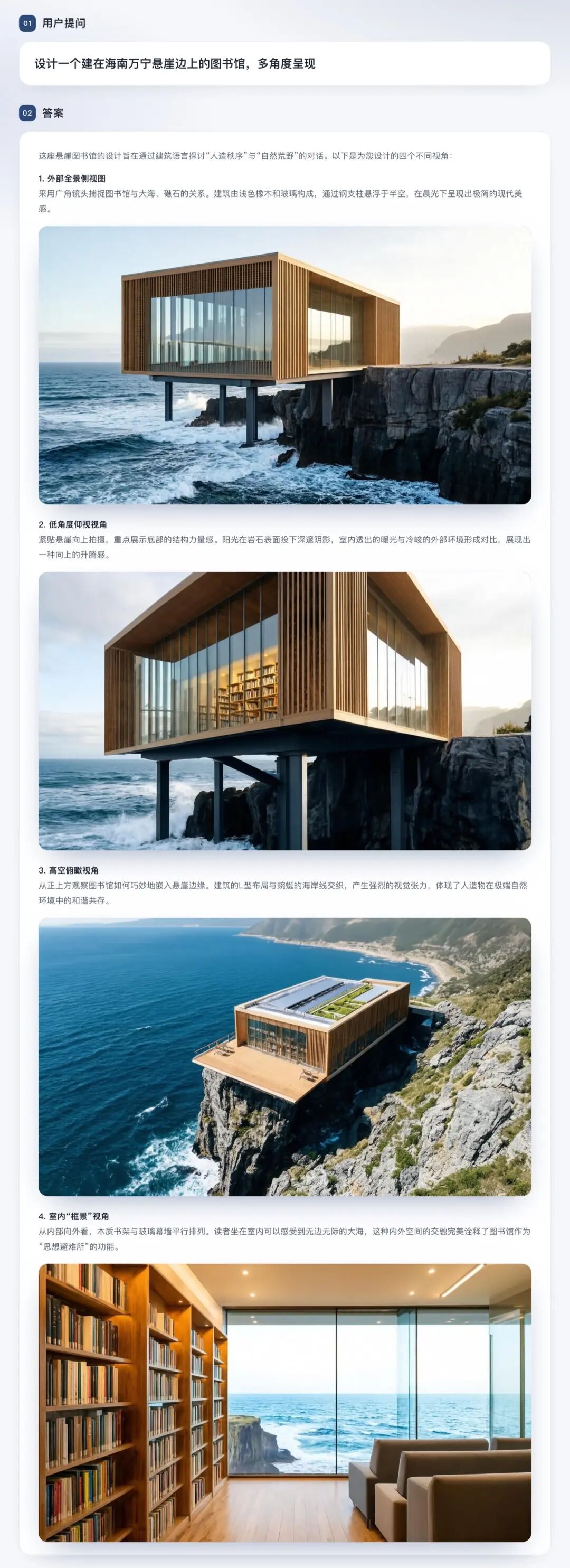
大多数生图模型是"一次prompt出一张图"的单点能力。U1的图文交错让它能在一次输出里完成"概念 -> 概念图 -> 解释段落 -> 对比图 -> 总结"这样的混排。
几个典型的应用场景:
答案在架构层。传统多模态模型用"拼积木"的方式:视觉编码器负责"看",VAE负责"画",中间接一个LLM负责"想"。三个模块各自独立训练,理解和生成走的是两条路。
NEO-Unify架构把VE和VAE都扔了。模型直接读原始像素、直接输出像素,在同一个骨干网络里让文本和视觉端到端统一训练。这让它不再做"翻译",而是真正"理解了再画"。
U1目前还有一些局限:
开源资源:
部署要求:

字节跳动图像模型 Seedream 5.0 Pro 上线火山引擎 API,主打局部精准编辑、14 语种文字生成与图层分离。

百度开源 Unlimited OCR,在 DeepSeek OCR 基础上引入 R-SWA 注意力机制,让 OCR 模型在 32K 标准上下文内单次前向推理解析数十页文档,OmniDocBench v1.5 拿下 93.23% 端到端 SOTA。

火山引擎发布 Doubao-Seed-Audio 1.0,把对白、配乐、音效和环境声压进一条 Prompt 一次性直出,支持多角色对白、2 分钟长程一致与参考音色续写,被称为语音模型的 Seedance 时刻。