北邮、北大团队提出 STAGE 框架,通过预测「起始-结束帧对」解决多镜头视频连贯性问题,已录用至 CVPR 2026。

北邮、北大团队提出 STAGE 框架,通过预测「起始-结束帧对」解决多镜头视频连贯性问题,已录用至 CVPR 2026。
Sora、可灵、Seedance 2.0……AI 视频生成的视觉质量已经惊艳,但当你尝试用它们创作一个完整故事时,会发现一个致命问题:镜头切换时经常「穿帮」。
前一秒主角还穿红衣,下一秒就换了颜色;一个流畅的开箱动作,在特写镜头里却变成了「瞬移」。这些问题的根源在于:AI 只会「画单帧」,不会「拍分镜」。
北京邮电大学、北京大学和智源研究院的团队提出了 STAGE 框架,通过引入电影分镜的概念,让 AI 学会用镜头讲故事。论文已录用至 CVPR 2026。

目前主流的多镜头视频生成方法分两派:
计算成本极高,过程像「开盲盒」,难以控制。稍有不慎就满盘皆输。
先生成几个关键画面作为「路标」,再让视频模型去「脑补」中间过程。
第二种方法更灵活,但问题也随之而来:模型只知道每个镜头「大概长啥样」,却不懂得镜头与镜头之间该如何「衔接」。

STAGE 的核心思路是:不再预测孤立的关键帧,而是直接生成每个镜头的「第一帧」和「最后一帧」。
这个看似简单的改变,带来了三大优势:
所有镜头的起始/结束帧串联起来,形成稳固的视觉骨架,确保角色、场景在整个故事中的长期一致性。
起始帧和结束帧明确定义了镜头内部的动态变化,无论是人物走位还是镜头推拉,都有了清晰的起点和终点。
上一个镜头的「结束帧」和下一个镜头的「起始帧」之间的关系,直接对「转场」这一电影语言进行建模。
STAGE 的核心是 STEP2(STart-End frame-Pair Prediction)模型,它像一位 AI 导演,能将文字剧本翻译成可执行的视觉分镜。
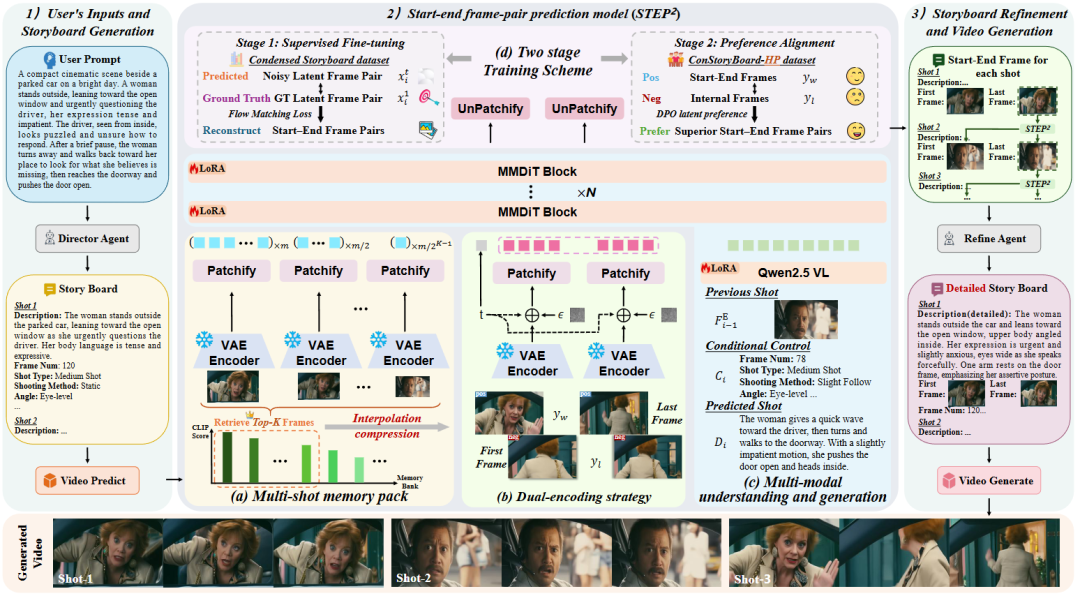
1. 多镜头记忆包(Multi-shot Memory Pack) 将所有历史镜头的视觉信息压缩成紧凑的「记忆包」,在保证长期一致性的同时避免巨大的计算开销。
2. 双重编码策略(Dual-Encoding Strategy) 将一个镜头的起始帧和结束帧「捆绑」在一起进行联合编码,让模型在生成之初就对整个镜头的动态了然于胸。
3. 两阶段训练方案(Two-stage Training)
团队构建了包含 10 万个高质量多镜头片段的数据集,每个镜头都标注了:
还从中挑选出最优转场案例,构建了 ConStoryBoard-HP 子集,专门用于第二阶段的「品味」训练。
在「火车上的女人」主题下,其他方法出现了场景不一致、风格失真、动作断裂等问题。STAGE 则完美保持了人物和环境的一致性。

在多个评测维度上,STAGE 均显著优于 CineTrans、StoryDiffusion、VideoGen-of-Thought 等 SOTA 方法。
项目代码和数据集将逐步开源:
git clone https://github.com/escapistmost/Storyboard-Anchored-Generation
cd Storyboard-Anchored-Generation
pip install -r requirements.txt适合谁?
不适合谁?
核心优势:
潜在限制:
未来展望: 团队提到未来可能引入 Agent 工作流,打造自动化环境构建流程,并扩展到更多任务场景(如 Terminal Bench、Skill Bench)。
相关链接:

Catnip 团队推出流式音视频社交模型 MaineCoon,22B参数实现47.5 FPS推理,支持30分钟以上音画同出,成本仅Veo 3的1/2000。

Agnes AI 无限期免费开放文本、图片、视频全模态模型API,本周升级1M超长上下文和4K超高清文生图能力。

AI 不是不会用,是你不会拆。从目标到动作到判断,一篇讲透如何把脑中经验变成 AI 能执行的结构化 Skill。