ACL 2026 论文,用 20 条学术写作标准和全文上下文建模,把 AI 论文修改从泛泛润色变成可控的定向修订

ACL 2026 论文,用 20 条学术写作标准和全文上下文建模,把 AI 论文修改从泛泛润色变成可控的定向修订
把论文段落丢给 ChatGPT 说「make it better」,得到的结果往往只是句子更流畅了,但缺失的论证链条、术语不一致、motivation 不够强这些真正关键的学术问题完全没有被解决。XtraGPT 由新加坡国立大学何炳胜教授团队提出(ACL 2026 接收),专做一件事:基于全文上下文的可控论文修订。适合有论文初稿、需要按学术标准精修的研究者和学生。
XtraGPT 不是「AI 代写论文」工具。它是一个 revision-only(仅修改)的协作系统:
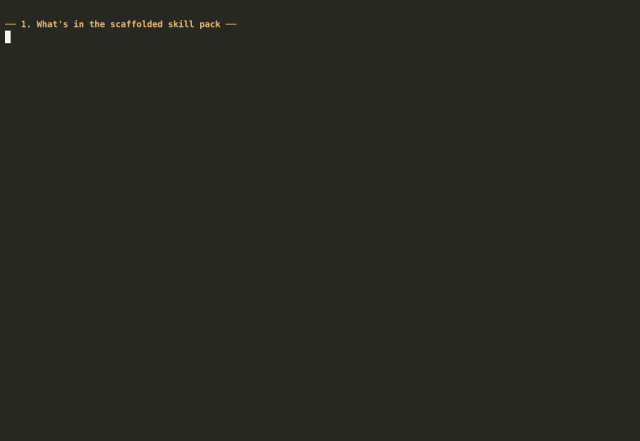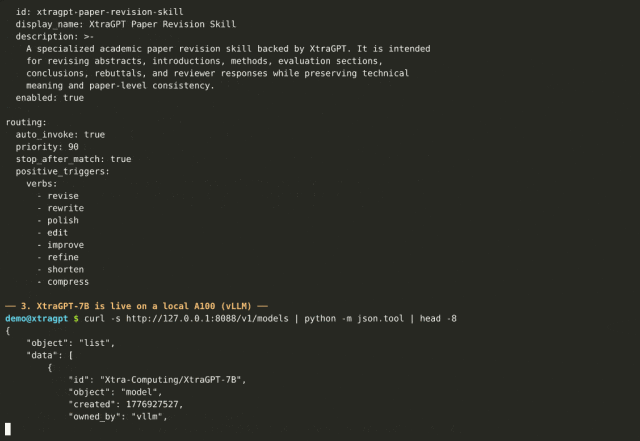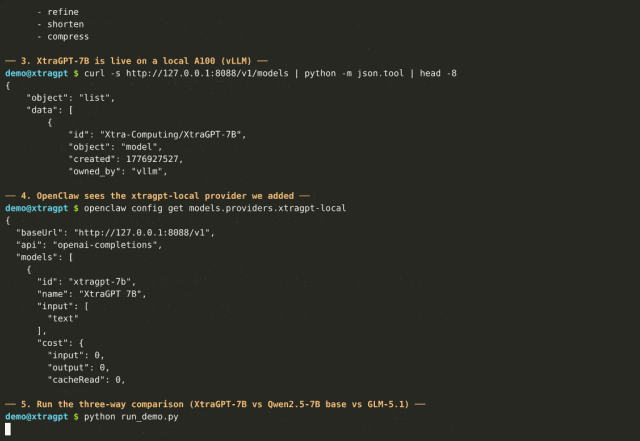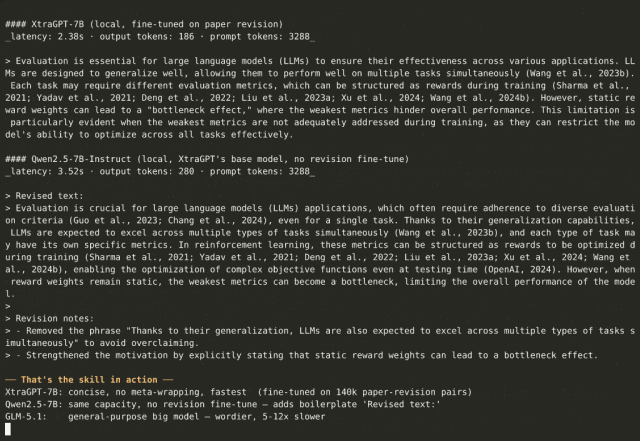
这与 ChatGPT 的核心区别在于:ChatGPT 只看到你给的那一段,而 XtraGPT 看到的是全文 16,384 token 的上下文。
这是 XtraGPT 最关键的能力。修改一段 motivation 时,模型会同时考虑引言中的问题定义、方法部分的假设、实验部分的结果,确保修改后的段落与全文保持一致。

消融实验证明:去掉全文上下文,效果下降约 15 分;而去掉 criteria grounding 只下降约 5 分。上下文比训练策略更重要。
XtraGPT 整理了覆盖论文六个部分的 20 条 section-level criteria:
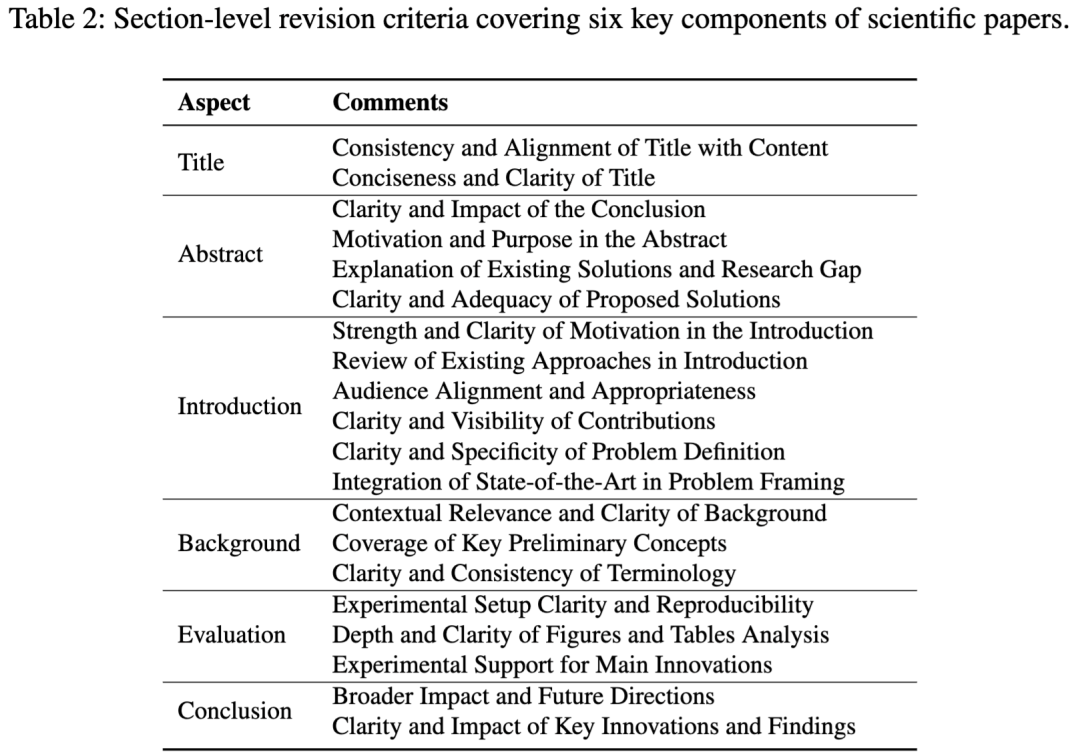
这些标准来自写作指南、审稿 rubric 和专家修订经验。你不需要手动选择标准——模型在训练阶段已经学会了把你的自然语言指令映射到对应的学术修改策略。
你用自然语言表达修改意图,模型执行定向修订。例如:
模型会在保持全文一致性的前提下,针对你指出的具体问题做修改。
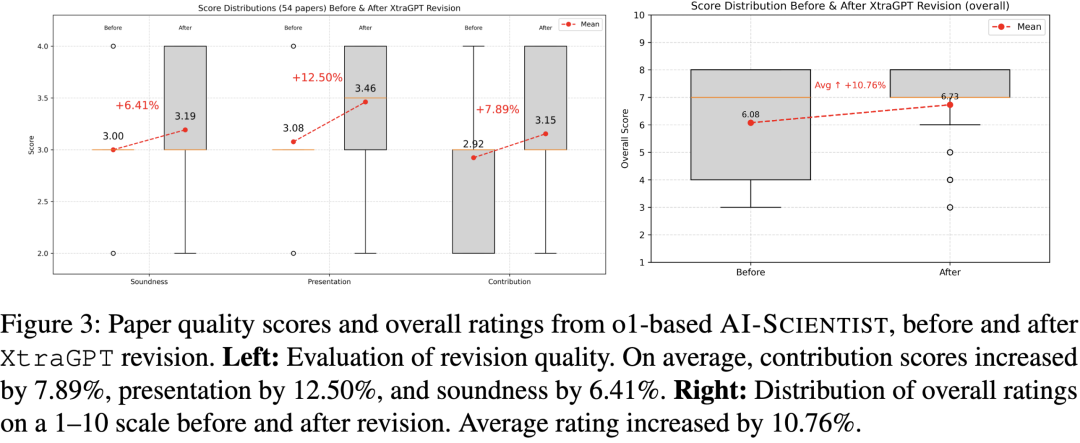
团队选取 54 篇 ICLR 2024 论文,用 XtraGPT 逐段修改,然后用 AI-Scientist judge 评分:
| 维度 | 提升幅度 |
|---|---|
| Contribution | +7.9% |
| Presentation | +12.5% |
| Soundness | +6.4% |
| Overall rating | 6.08 -> 6.73 (+0.65) |
在 7000 条测试样本上,XtraGPT-7B 和 XtraGPT-14B 的输出都被 Fast-DetectGPT 和 Binoculars 判定为人类文本一侧。
模型提供 1.5B 到 14B 多个版本,基于 Qwen-2.5 和 Phi 系列,可以在本地部署运行。
| 维度 | ChatGPT / Claude | XtraGPT |
|---|---|---|
| 上下文 | 只有你粘贴的段落 | 全文 16k token |
| 修改类型 | 泛泛润色 | 按学术标准定向修订 |
| 作者控制 | 模型决定改什么 | 作者指定改哪里、怎么改 |
| 训练数据 | 通用对话 | 14 万组真实论文修订对 |
| 输出 | 替换原文 | diff 格式,可审阅可拒绝 |

Claude Mythos Preview 帮助 Firefox 团队一个月修复 423 个安全漏洞,含 180 个高危漏洞和多个沙箱逃逸,含藏了 20 年的老 Bug。

谷歌发布 Gemini 3.5 Flash,编程和 Agent 能力全面超越 3.1 Pro,输出速度是其他前沿模型 4 倍,成本仅为 Claude Sonnet 六折。
谷歌发布 Gemini Omni,整合 Nano Banana、Veo 和 Genie,支持任意输入生成视频,用自然语言对话式编辑,已上线 Gemini App 和 Google Flow。