百度开源 Unlimited OCR,3B 总参数 / 500M 激活的端到端 OCR 模型,刷新 OmniDocBench SOTA,单次推理转录数十页文档不失忆。

百度开源 Unlimited OCR,3B 总参数 / 500M 激活的端到端 OCR 模型,刷新 OmniDocBench SOTA,单次推理转录数十页文档不失忆。
如果你做过文档数字化、合同解析或长 PDF 转录,大概率被一个共同问题折磨过:OCR 模型一页一页"失忆",几十页文档靠外部调度器拼起来,越往后越慢、越乱。百度最新开源的 Unlimited OCR 直接瞄准这个痛点,单次推理从第一页读到最后一页,KV 缓存占用恒定。
它适合需要长文档端到端解析的开发者、做 RAG 知识库的团队,以及想把 OCR 嵌进生产管线但被"逐页处理"拖累的人。模型和代码已经全部开源,可以立刻拿来用。

一句话概括:一个把"参考滑动窗口注意力"(R-SWA)应用到极致的端到端 OCR MoE 模型。
激活参数不到它们零头,跑分却把它们全甩开。这是 Unlimited OCR 最直观的卖点。
标准注意力机制下,随着输出变长,KV 缓存像滚雪球一样疯涨——内存吃不消,速度越来越慢。这才是逼着所有 OCR 模型逐页处理、频频"失忆"的真正原因。
百度的解法是 Reference Sliding Window Attention(R-SWA,参考滑动窗口注意力),对应人抄书时的注意力模式:
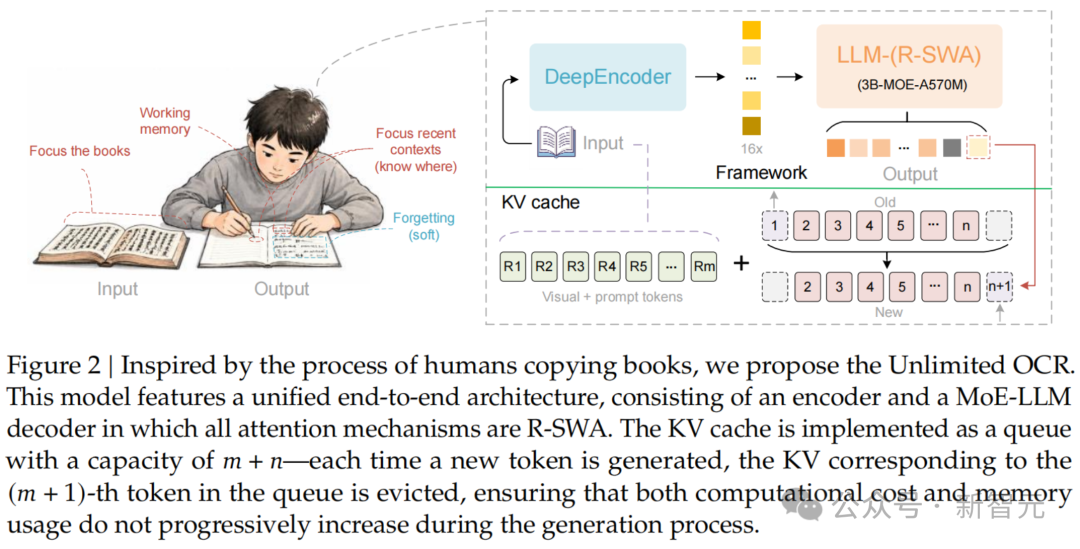
配合最初在 DeepSeek OCR 中登场的 DeepEncoder 编码器,一张 1024×1024 的 PDF 页面被压缩到仅 256 个视觉 token(16 倍压缩率)。由于视觉 token 在 R-SWA 下不参与状态转移,无论文档多长,图像信息永远清清楚楚,不会随解码过程退化。
在标准的 32K 上下文里,Unlimited OCR 一次前向推理就能转录数十页文档:
| 输入文档 | 编辑距离(与原文逐字比对) | 重复输出 Distinct-35 |
|---|---|---|
| 20 页 | 0.057 | — |
| 40 页以上 | < 0.11 | 97% |
几十页一口气转录,几乎没有复读。
跑分对比上,OmniDocBench v1.5 综合得分 93.23%,比 DeepSeek OCR 的 87.01% 高 6.22 个百分点;文本编辑距离从 0.073 降到 0.038,公式 CDM 从 83.37 飙到 92.61,表格 TEDS 从 84.97 升到 90.93。九大文档类型(PPT、论文、杂志、报纸等)中文本和阅读顺序两项全面超越 DeepSeek OCR,且在七个类别中领先 DeepSeek OCR 2。
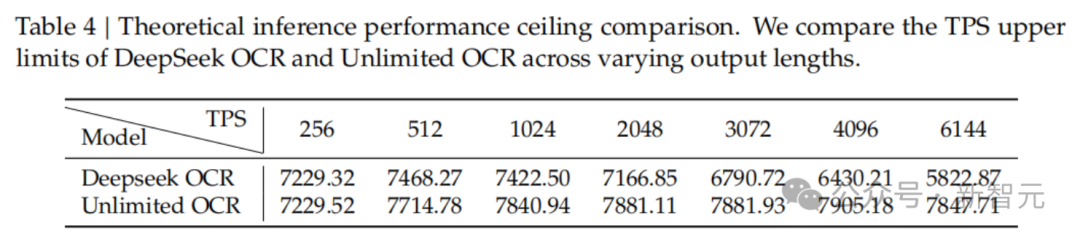
效率同样碾压:输出 6144 个 token 时,Unlimited OCR 的 TPS 是 7847,DeepSeek OCR 已经掉到 5822,差距 35%。这是一个 500M 激活的 MoE 小模型,在 DeepSeek OCR 基础上仅继续训练 4000 步的结果——R-SWA 对解析任务几乎是一种"免费午餐"。
仓库和模型权重都已开放:
直接拉取仓库按 README 部署即可,权重支持本地推理。对想要把 OCR 嵌进生产管线、又不想被逐页调度逻辑拖累的团队来说,这是一条值得评估的新路径。
💡 提示:当前版本上下文窗口为 32K,论文展望提到下一步要训到 128K,并构建 prefill pool 让模型学会自动翻页——届时 OCR 的边界会从"识别一页文字"扩展到"理解一整本书"。
技术报告署名里有意思的细节:核心贡献者三位,技术总监挂了个"YY"缩写。GitHub 致谢栏把 Deepseek-OCR 和 Deepseek-OCR-2 排在前两位,结合能力、时间线和署名方式,外界普遍猜测 YY 是从 DeepSeek 离职的 OCR 核心作者魏浩然(一手搭建了 DeepSeek OCR 一代到二代,包括 DeepEncoder 和 MoE 解码器)。
对使用者来说,更实际的意义是:这套 R-SWA 范式如果继续推广到 ASR(语音识别)和翻译,百度手里握着的就不只是一个 OCR 模型,而是一套通用的长程解析技术框架。值得长期关注。

