百度基于 DeepSeek OCR 推出的 Unlimited OCR,通过 R-SWA 机制实现 32K 上下文长程解析,OmniDocBench v1.5 端到端 SOTA 达 93.23%。

百度基于 DeepSeek OCR 推出的 Unlimited OCR,通过 R-SWA 机制实现 32K 上下文长程解析,OmniDocBench v1.5 端到端 SOTA 达 93.23%。
DeepSeek OCR 留下的一个长文档解析难题,被百度接住了。百度在 HuggingFace 上开源了新模型 Unlimited OCR,在标准最大上下文长度 32K 的条件下,让 OCR 模型第一次能够一口气读完整本书——不是逐页处理,不是 for-loop 式拆任务,也不是靠外部调度器拼结果,而是真正意义上的一次前向推理直接完成数十页文档解析。本篇拆解它解决了什么问题、怎么用、以及开源后能干什么。
把它理解成「能读长文档的 DeepSeek OCR Plus」。它直接构建在 DeepSeek OCR 的基础之上——视觉压缩部分 DeepSeek OCR 已经做到极致(一张 1024×1024 文档页编码后只剩 256 个视觉 token),Unlimited OCR 没有重做编码器,而是把全部精力放在解码阶段。项目主页一句话点题:「push DeepSeek-OCR one step further」。
为什么 DeepSeek OCR 视觉 token 压缩这么狠,还是很难处理长文档?答案在解码端。
视觉 token 压缩之后,模型生成的文本不会凭空消失。随着输出越来越长,解码器里的 KV Cache 会不断增长:输出越长,显存占用越高;历史越长,注意力计算越重;生成速度越来越慢。
这就是为什么过去大多数 OCR 系统最终都退回到逐页解析模式——再高效的编码器,也解决不了解码阶段不断膨胀的历史负担。
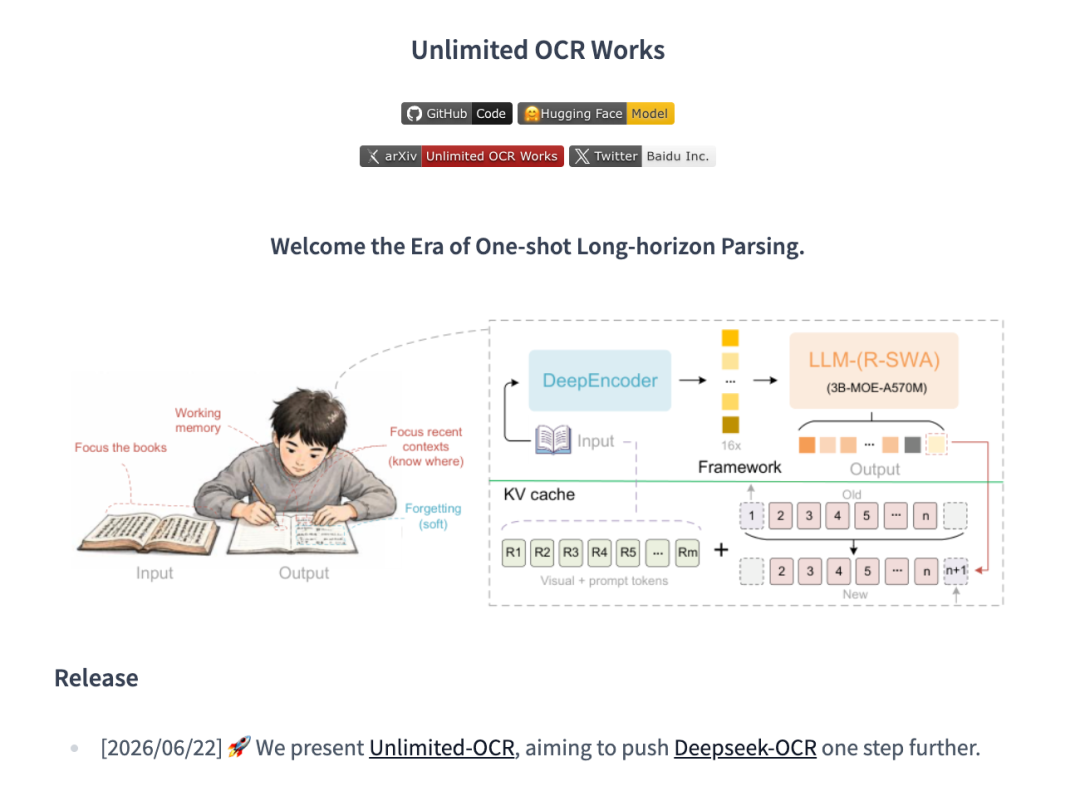
关键不是「能不能处理多页」,而是「能不能在不退化到逐页模式的前提下处理」——Unlimited OCR 选了后者。
Unlimited OCR 引入的核心机制是 R-SWA(Rotary Sliding Window Attention,旋转滑动窗口注意力)。它解决的问题直白:在不牺牲长程依赖建模能力的前提下,控制注意力计算成本。简单说,模型既能看到几十页之前的内容,又不让计算量随页数指数级爆炸——这是它能一次跑完整本书的底层原因。
在文档解析主流基准 OmniDocBench v1.5 上:
OmniDocBench v1.5 是文档解析领域的标准基准,93.23% 意味着在真实文档(论文、教材、合同等)的端到端提取上达到当前最佳水平。
由于一次前向推理能处理数十页,Unlimited OCR 特别适合:
模型已在 HuggingFace 开源,权重和代码可直接拉取:
💡 提示:因为是建立在 DeepSeek OCR 之上,已经在用 DeepSeek OCR 的工程可以平滑迁移,主要是替换注意力实现和加载新权重,不需要重做数据管线。

阿里发布视频生成模型 HappyHorse 1.1,五大维度升级,1080P 每秒 1.2 元降为 0.9 元,附实测对比与体验地址。

火山引擎 Seed-Audio 1.0 升级为影视级全要素直出,一段提示词即可生成多角色对话、音效与背景音乐,接近成片级声音。

百度开源 Unlimited OCR,3B 总参数 / 500M 激活的端到端 OCR 模型,刷新 OmniDocBench SOTA,单次推理转录数十页文档不失忆。